 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVchitect-2.0: Parallel Transformer for Scaling Up Video Diffusion Models
Jan 14, 2025
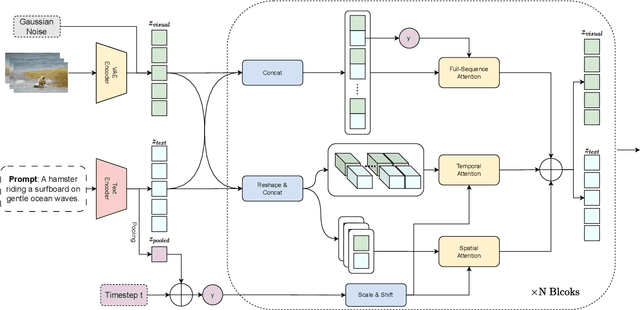
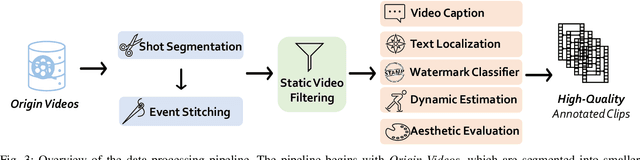
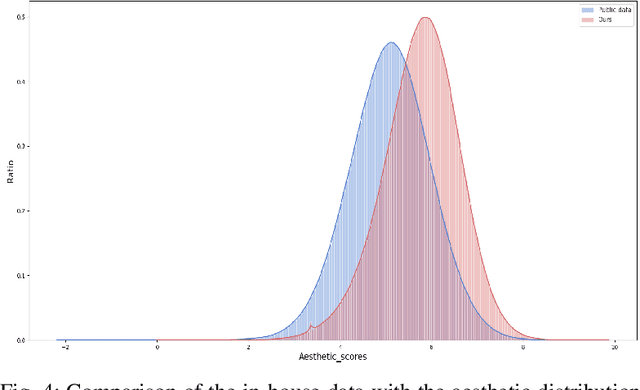
We present Vchitect-2.0, a parallel transformer architecture designed to scale up video diffusion models for large-scale text-to-video generation. The overall Vchitect-2.0 system has several key designs. (1) By introducing a novel Multimodal Diffusion Block, our approach achieves consistent alignment between text descriptions and generated video frames, while maintaining temporal coherence across sequences. (2) To overcome memory and computational bottlenecks, we propose a Memory-efficient Training framework that incorporates hybrid parallelism and other memory reduction techniques, enabling efficient training of long video sequences on distributed systems. (3) Additionally, our enhanced data processing pipeline ensures the creation of Vchitect T2V DataVerse, a high-quality million-scale training dataset through rigorous annotation and aesthetic evaluation. Extensive benchmarking demonstrates that Vchitect-2.0 outperforms existing methods in video quality, training efficiency, and scalability, serving as a suitable base for high-fidelity video generation.
VBench++: Comprehensive and Versatile Benchmark Suite for Video Generative Models
Nov 20, 2024



Video generation has witnessed significant advancements, yet evaluating these models remains a challenge. A comprehensive evaluation benchmark for video generation is indispensable for two reasons: 1) Existing metrics do not fully align with human perceptions; 2) An ideal evaluation system should provide insights to inform future developments of video generation. To this end, we present VBench, a comprehensive benchmark suite that dissects "video generation quality" into specific, hierarchical, and disentangled dimensions, each with tailored prompts and evaluation methods. VBench has several appealing properties: 1) Comprehensive Dimensions: VBench comprises 16 dimensions in video generation (e.g., subject identity inconsistency, motion smoothness, temporal flickering, and spatial relationship, etc). The evaluation metrics with fine-grained levels reveal individual models' strengths and weaknesses. 2) Human Alignment: We also provide a dataset of human preference annotations to validate our benchmarks' alignment with human perception, for each evaluation dimension respectively. 3) Valuable Insights: We look into current models' ability across various evaluation dimensions, and various content types. We also investigate the gaps between video and image generation models. 4) Versatile Benchmarking: VBench++ supports evaluating text-to-video and image-to-video. We introduce a high-quality Image Suite with an adaptive aspect ratio to enable fair evaluations across different image-to-video generation settings. Beyond assessing technical quality, VBench++ evaluates the trustworthiness of video generative models, providing a more holistic view of model performance. 5) Full Open-Sourcing: We fully open-source VBench++ and continually add new video generation models to our leaderboard to drive forward the field of video generation.
NTIRE 2024 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 15, 2024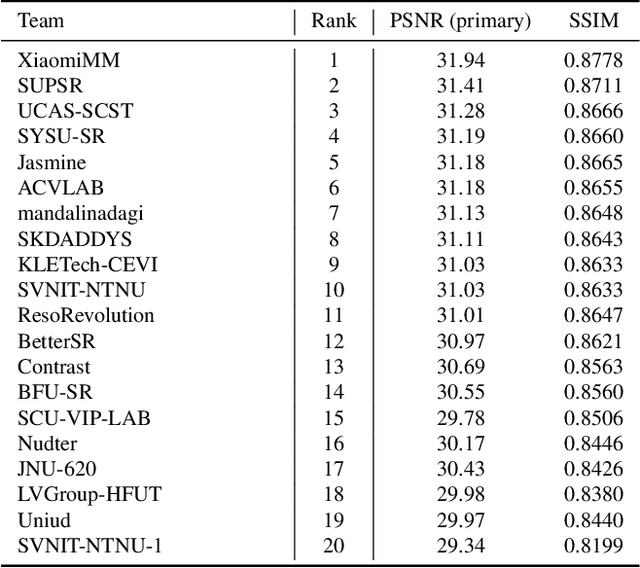
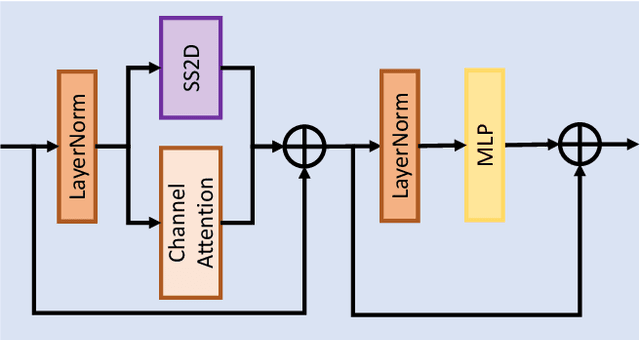
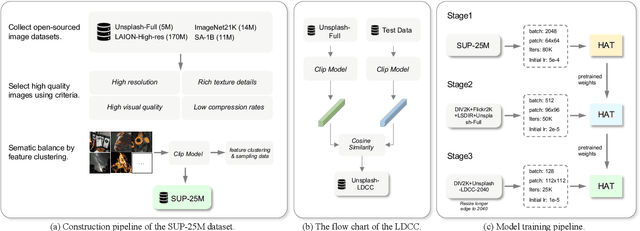
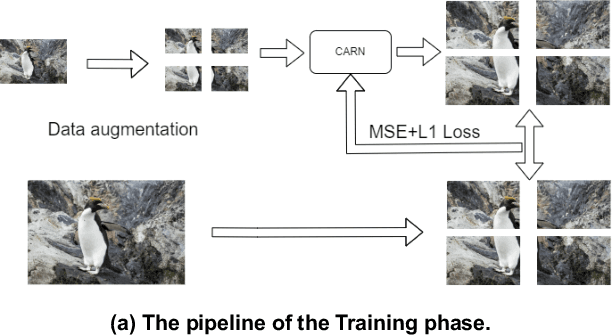
This paper reviews the NTIRE 2024 challenge on image super-resolution ($\times$4), highlighting the solutions proposed and the outcomes obtained. The challenge involves generating corresponding high-resolution (HR) images, magnified by a factor of four, from low-resolution (LR) inputs using prior information. The LR images originate from bicubic downsampling degradation. The aim of the challenge is to obtain designs/solutions with the most advanced SR performance, with no constraints on computational resources (e.g., model size and FLOPs) or training data. The track of this challenge assesses performance with the PSNR metric on the DIV2K testing dataset. The competition attracted 199 registrants, with 20 teams submitting valid entries. This collective endeavour not only pushes the boundaries of performance in single-image SR but also offers a comprehensive overview of current trends in this field.