 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion-NPO: Negative Preference Optimization for Better Preference Aligned Generation of Diffusion Models
May 16, 2025Diffusion models have made substantial advances in image generation, yet models trained on large, unfiltered datasets often yield outputs misaligned with human preferences. Numerous methods have been proposed to fine-tune pre-trained diffusion models, achieving notable improvements in aligning generated outputs with human preferences. However, we argue that existing preference alignment methods neglect the critical role of handling unconditional/negative-conditional outputs, leading to a diminished capacity to avoid generating undesirable outcomes. This oversight limits the efficacy of classifier-free guidance~(CFG), which relies on the contrast between conditional generation and unconditional/negative-conditional generation to optimize output quality. In response, we propose a straightforward but versatile effective approach that involves training a model specifically attuned to negative preferences. This method does not require new training strategies or datasets but rather involves minor modifications to existing techniques. Our approach integrates seamlessly with models such as SD1.5, SDXL, video diffusion models and models that have undergone preference optimization, consistently enhancing their alignment with human preferences.
RenderMe-360: A Large Digital Asset Library and Benchmarks Towards High-fidelity Head Avatars
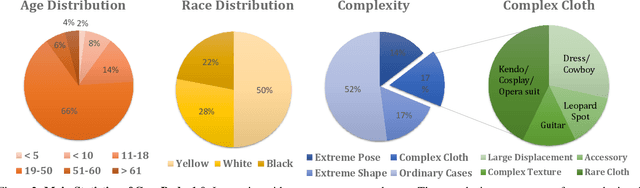
May 22, 2023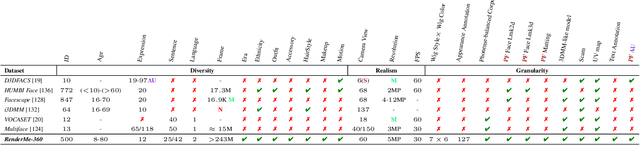
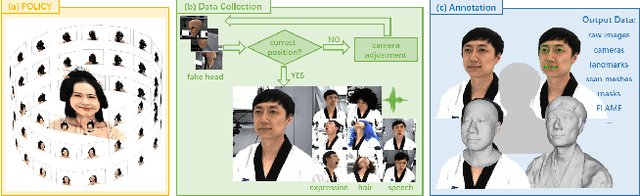


Synthesizing high-fidelity head avatars is a central problem for computer vision and graphics. While head avatar synthesis algorithms have advanced rapidly, the best ones still face great obstacles in real-world scenarios. One of the vital causes is inadequate datasets -- 1) current public datasets can only support researchers to explore high-fidelity head avatars in one or two task directions; 2) these datasets usually contain digital head assets with limited data volume, and narrow distribution over different attributes. In this paper, we present RenderMe-360, a comprehensive 4D human head dataset to drive advance in head avatar research. It contains massive data assets, with 243+ million complete head frames, and over 800k video sequences from 500 different identities captured by synchronized multi-view cameras at 30 FPS. It is a large-scale digital library for head avatars with three key attributes: 1) High Fidelity: all subjects are captured by 60 synchronized, high-resolution 2K cameras in 360 degrees. 2) High Diversity: The collected subjects vary from different ages, eras, ethnicities, and cultures, providing abundant materials with distinctive styles in appearance and geometry. Moreover, each subject is asked to perform various motions, such as expressions and head rotations, which further extend the richness of assets. 3) Rich Annotations: we provide annotations with different granularities: cameras' parameters, matting, scan, 2D/3D facial landmarks, FLAME fitting, and text description. Based on the dataset, we build a comprehensive benchmark for head avatar research, with 16 state-of-the-art methods performed on five main tasks: novel view synthesis, novel expression synthesis, hair rendering, hair editing, and talking head generation. Our experiments uncover the strengths and weaknesses of current methods. RenderMe-360 opens the door for future exploration in head avatars.
High-fidelity 3D GAN Inversion by Pseudo-multi-view Optimization
Nov 29, 2022We present a high-fidelity 3D generative adversarial network (GAN) inversion framework that can synthesize photo-realistic novel views while preserving specific details of the input image. High-fidelity 3D GAN inversion is inherently challenging due to the geometry-texture trade-off in 3D inversion, where overfitting to a single view input image often damages the estimated geometry during the latent optimization. To solve this challenge, we propose a novel pipeline that builds on the pseudo-multi-view estimation with visibility analysis. We keep the original textures for the visible parts and utilize generative priors for the occluded parts. Extensive experiments show that our approach achieves advantageous reconstruction and novel view synthesis quality over state-of-the-art methods, even for images with out-of-distribution textures. The proposed pipeline also enables image attribute editing with the inverted latent code and 3D-aware texture modification. Our approach enables high-fidelity 3D rendering from a single image, which is promising for various applications of AI-generated 3D content.
Generalizable Neural Performer: Learning Robust Radiance Fields for Human Novel View Synthesis
Apr 25, 2022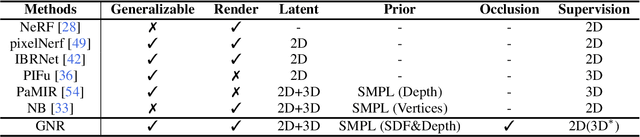
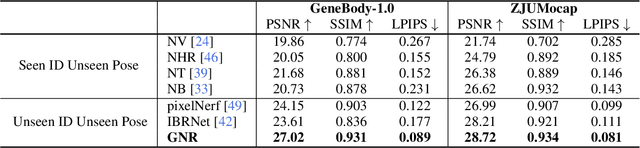
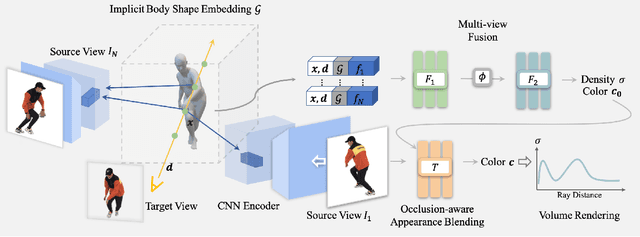
This work targets at using a general deep learning framework to synthesize free-viewpoint images of arbitrary human performers, only requiring a sparse number of camera views as inputs and skirting per-case fine-tuning. The large variation of geometry and appearance, caused by articulated body poses, shapes and clothing types, are the key bottlenecks of this task. To overcome these challenges, we present a simple yet powerful framework, named Generalizable Neural Performer (GNR), that learns a generalizable and robust neural body representation over various geometry and appearance. Specifically, we compress the light fields for novel view human rendering as conditional implicit neural radiance fields from both geometry and appearance aspects. We first introduce an Implicit Geometric Body Embedding strategy to enhance the robustness based on both parametric 3D human body model and multi-view images hints. We further propose a Screen-Space Occlusion-Aware Appearance Blending technique to preserve the high-quality appearance, through interpolating source view appearance to the radiance fields with a relax but approximate geometric guidance. To evaluate our method, we present our ongoing effort of constructing a dataset with remarkable complexity and diversity. The dataset GeneBody-1.0, includes over 360M frames of 370 subjects under multi-view cameras capturing, performing a large variety of pose actions, along with diverse body shapes, clothing, accessories and hairdos. Experiments on GeneBody-1.0 and ZJU-Mocap show better robustness of our methods than recent state-of-the-art generalizable methods among all cross-dataset, unseen subjects and unseen poses settings. We also demonstrate the competitiveness of our model compared with cutting-edge case-specific ones. Dataset, code and model will be made publicly available.
Simulating Fluids in Real-World Still Images
Apr 24, 2022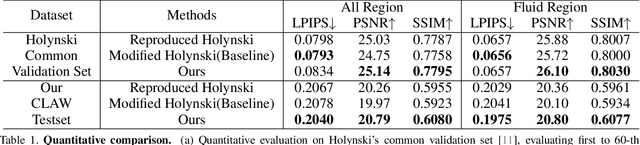
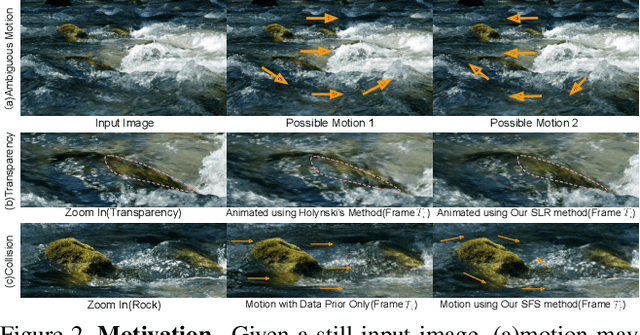
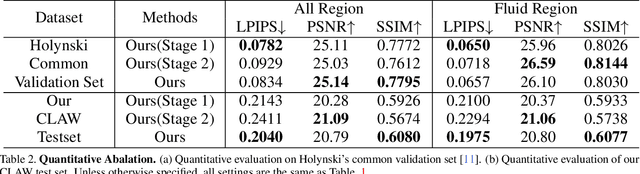
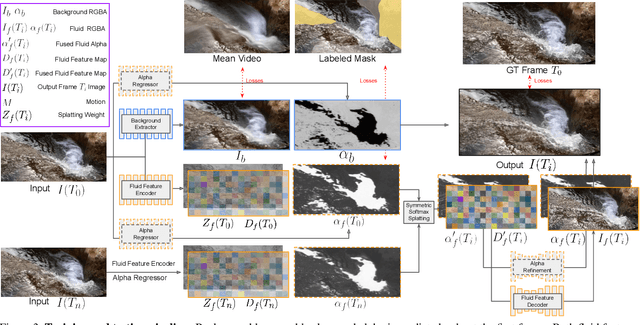
In this work, we tackle the problem of real-world fluid animation from a still image. The key of our system is a surface-based layered representation deriving from video decomposition, where the scene is decoupled into a surface fluid layer and an impervious background layer with corresponding transparencies to characterize the composition of the two layers. The animated video can be produced by warping only the surface fluid layer according to the estimation of fluid motions and recombining it with the background. In addition, we introduce surface-only fluid simulation, a $2.5D$ fluid calculation version, as a replacement for motion estimation. Specifically, we leverage the triangular mesh based on a monocular depth estimator to represent the fluid surface layer and simulate the motion in the physics-based framework with the inspiration of the classic theory of the hybrid Lagrangian-Eulerian method, along with a learnable network so as to adapt to complex real-world image textures. We demonstrate the effectiveness of the proposed system through comparison with existing methods in both standard objective metrics and subjective ranking scores. Extensive experiments not only indicate our method's competitive performance for common fluid scenes but also better robustness and reasonability under complex transparent fluid scenarios. Moreover, as the proposed surface-based layer representation and surface-only fluid simulation naturally disentangle the scene, interactive editing such as adding objects to the river and texture replacing could be easily achieved with realistic results.
Inverting Generative Adversarial Renderer for Face Reconstruction
May 08, 2021

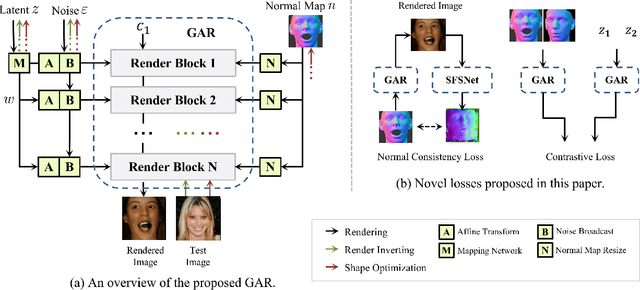
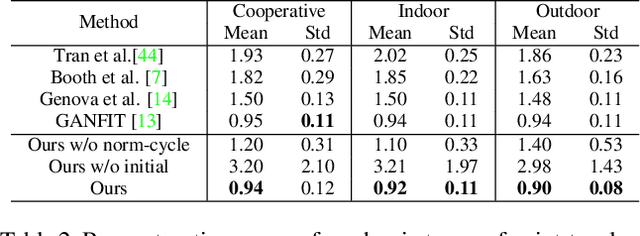
Given a monocular face image as input, 3D face geometry reconstruction aims to recover a corresponding 3D face mesh. Recently, both optimization-based and learning-based face reconstruction methods have taken advantage of the emerging differentiable renderer and shown promising results. However, the differentiable renderer, mainly based on graphics rules, simplifies the realistic mechanism of the illumination, reflection, \etc, of the real world, thus cannot produce realistic images. This brings a lot of domain-shift noise to the optimization or training process. In this work, we introduce a novel Generative Adversarial Renderer (GAR) and propose to tailor its inverted version to the general fitting pipeline, to tackle the above problem. Specifically, the carefully designed neural renderer takes a face normal map and a latent code representing other factors as inputs and renders a realistic face image. Since the GAR learns to model the complicated real-world image, instead of relying on the simplified graphics rules, it is capable of producing realistic images, which essentially inhibits the domain-shift noise in training and optimization. Equipped with the elaborated GAR, we further proposed a novel approach to predict 3D face parameters, in which we first obtain fine initial parameters via Renderer Inverting and then refine it with gradient-based optimizers. Extensive experiments have been conducted to demonstrate the effectiveness of the proposed generative adversarial renderer and the novel optimization-based face reconstruction framework. Our method achieves state-of-the-art performances on multiple face reconstruction datasets.