 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverting Generative Adversarial Renderer for Face Reconstruction
May 08, 2021

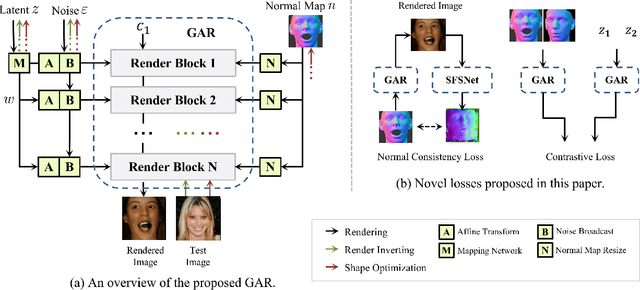
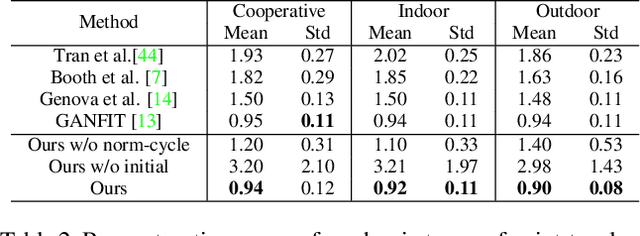
Given a monocular face image as input, 3D face geometry reconstruction aims to recover a corresponding 3D face mesh. Recently, both optimization-based and learning-based face reconstruction methods have taken advantage of the emerging differentiable renderer and shown promising results. However, the differentiable renderer, mainly based on graphics rules, simplifies the realistic mechanism of the illumination, reflection, \etc, of the real world, thus cannot produce realistic images. This brings a lot of domain-shift noise to the optimization or training process. In this work, we introduce a novel Generative Adversarial Renderer (GAR) and propose to tailor its inverted version to the general fitting pipeline, to tackle the above problem. Specifically, the carefully designed neural renderer takes a face normal map and a latent code representing other factors as inputs and renders a realistic face image. Since the GAR learns to model the complicated real-world image, instead of relying on the simplified graphics rules, it is capable of producing realistic images, which essentially inhibits the domain-shift noise in training and optimization. Equipped with the elaborated GAR, we further proposed a novel approach to predict 3D face parameters, in which we first obtain fine initial parameters via Renderer Inverting and then refine it with gradient-based optimizers. Extensive experiments have been conducted to demonstrate the effectiveness of the proposed generative adversarial renderer and the novel optimization-based face reconstruction framework. Our method achieves state-of-the-art performances on multiple face reconstruction datasets.
TRB: A Novel Triplet Representation for Understanding 2D Human Body
Oct 25, 2019
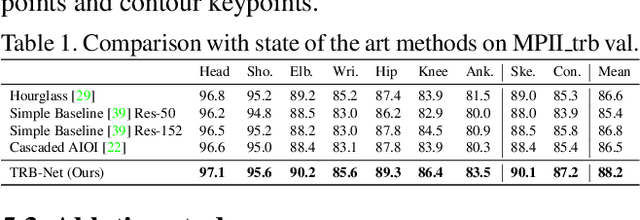


Human pose and shape are two important components of 2D human body. However, how to efficiently represent both of them in images is still an open question. In this paper, we propose the Triplet Representation for Body (TRB) -- a compact 2D human body representation, with skeleton keypoints capturing human pose information and contour keypoints containing human shape information. TRB not only preserves the flexibility of skeleton keypoint representation, but also contains rich pose and human shape information. Therefore, it promises broader application areas, such as human shape editing and conditional image generation. We further introduce the challenging problem of TRB estimation, where joint learning of human pose and shape is required. We construct several large-scale TRB estimation datasets, based on popular 2D pose datasets: LSP, MPII, COCO. To effectively solve TRB estimation, we propose a two-branch network (TRB-net) with three novel techniques, namely X-structure (Xs), Directional Convolution (DC) and Pairwise Mapping (PM), to enforce multi-level message passing for joint feature learning. We evaluate our proposed TRB-net and several leading approaches on our proposed TRB datasets, and demonstrate the superiority of our method through extensive evaluations.