 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNormalized Avatar Synthesis Using StyleGAN and Perceptual Refinement
Jun 21, 2021


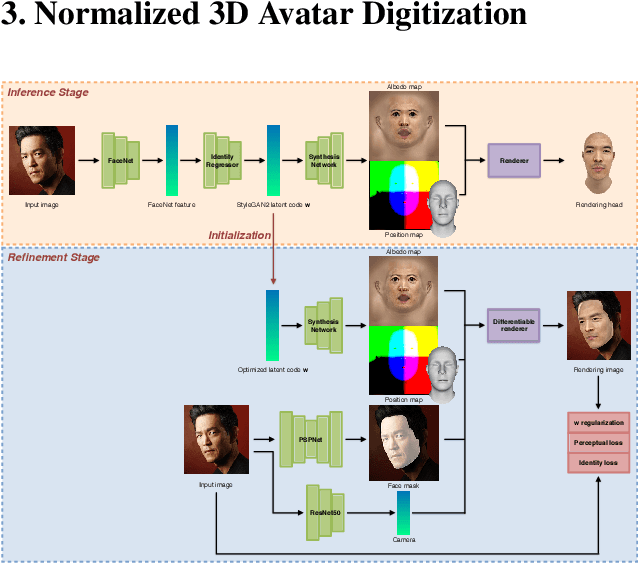
We introduce a highly robust GAN-based framework for digitizing a normalized 3D avatar of a person from a single unconstrained photo. While the input image can be of a smiling person or taken in extreme lighting conditions, our method can reliably produce a high-quality textured model of a person's face in neutral expression and skin textures under diffuse lighting condition. Cutting-edge 3D face reconstruction methods use non-linear morphable face models combined with GAN-based decoders to capture the likeness and details of a person but fail to produce neutral head models with unshaded albedo textures which is critical for creating relightable and animation-friendly avatars for integration in virtual environments. The key challenges for existing methods to work is the lack of training and ground truth data containing normalized 3D faces. We propose a two-stage approach to address this problem. First, we adopt a highly robust normalized 3D face generator by embedding a non-linear morphable face model into a StyleGAN2 network. This allows us to generate detailed but normalized facial assets. This inference is then followed by a perceptual refinement step that uses the generated assets as regularization to cope with the limited available training samples of normalized faces. We further introduce a Normalized Face Dataset, which consists of a combination photogrammetry scans, carefully selected photographs, and generated fake people with neutral expressions in diffuse lighting conditions. While our prepared dataset contains two orders of magnitude less subjects than cutting edge GAN-based 3D facial reconstruction methods, we show that it is possible to produce high-quality normalized face models for very challenging unconstrained input images, and demonstrate superior performance to the current state-of-the-art.
Mask-off: Synthesizing Face Images in the Presence of Head-mounted Displays
Oct 27, 2016

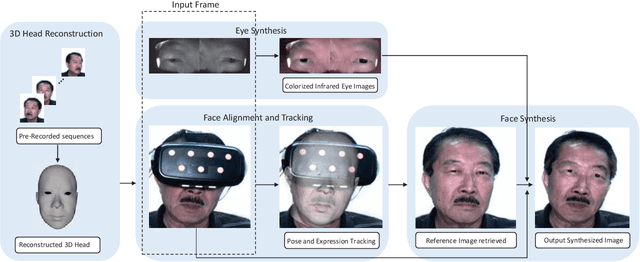

A head-mounted display (HMD) could be an important component of augmented reality system. However, as the upper face region is seriously occluded by the device, the user experience could be affected in applications such as telecommunication and multi-player video games. In this paper, we first present a novel experimental setup that consists of two near-infrared (NIR) cameras to point to the eye regions and one visible-light RGB camera to capture the visible face region. The main purpose of this paper is to synthesize realistic face images without occlusions based on the images captured by these cameras. To this end, we propose a novel synthesis framework that contains four modules: 3D head reconstruction, face alignment and tracking, face synthesis, and eye synthesis. In face synthesis, we propose a novel algorithm that can robustly align and track a personalized 3D head model given a face that is severely occluded by the HMD. In eye synthesis, in order to generate accurate eye movements and dynamic wrinkle variations around eye regions, we propose another novel algorithm to colorize the NIR eye images and further remove the "red eye" effects caused by the colorization. Results show that both hardware setup and system framework are robust to synthesize realistic face images in video sequences.