 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReverse Personalization
Dec 28, 2025Recent text-to-image diffusion models have demonstrated remarkable generation of realistic facial images conditioned on textual prompts and human identities, enabling creating personalized facial imagery. However, existing prompt-based methods for removing or modifying identity-specific features rely either on the subject being well-represented in the pre-trained model or require model fine-tuning for specific identities. In this work, we analyze the identity generation process and introduce a reverse personalization framework for face anonymization. Our approach leverages conditional diffusion inversion, allowing direct manipulation of images without using text prompts. To generalize beyond subjects in the model's training data, we incorporate an identity-guided conditioning branch. Unlike prior anonymization methods, which lack control over facial attributes, our framework supports attribute-controllable anonymization. We demonstrate that our method achieves a state-of-the-art balance between identity removal, attribute preservation, and image quality. Source code and data are available at https://github.com/hanweikung/reverse-personalization .
NullFace: Training-Free Localized Face Anonymization
Mar 11, 2025
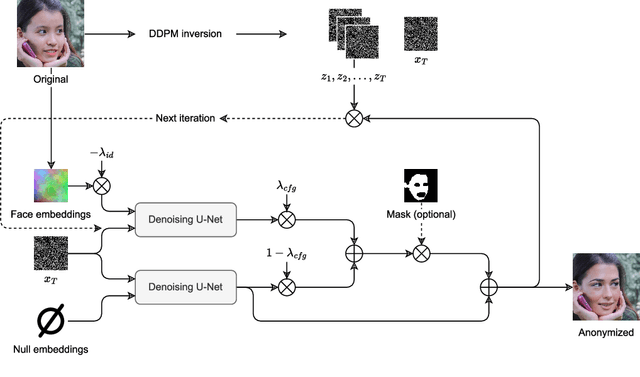


Privacy concerns around ever increasing number of cameras are increasing in today's digital age. Although existing anonymization methods are able to obscure identity information, they often struggle to preserve the utility of the images. In this work, we introduce a training-free method for face anonymization that preserves key non-identity-related attributes. Our approach utilizes a pre-trained text-to-image diffusion model without requiring optimization or training. It begins by inverting the input image to recover its initial noise. The noise is then denoised through an identity-conditioned diffusion process, where modified identity embeddings ensure the anonymized face is distinct from the original identity. Our approach also supports localized anonymization, giving users control over which facial regions are anonymized or kept intact. Comprehensive evaluations against state-of-the-art methods show our approach excels in anonymization, attribute preservation, and image quality. Its flexibility, robustness, and practicality make it well-suited for real-world applications. Code and data can be found at https://github.com/hanweikung/nullface .
Face Anonymization Made Simple
Nov 01, 2024



Current face anonymization techniques often depend on identity loss calculated by face recognition models, which can be inaccurate and unreliable. Additionally, many methods require supplementary data such as facial landmarks and masks to guide the synthesis process. In contrast, our approach uses diffusion models with only a reconstruction loss, eliminating the need for facial landmarks or masks while still producing images with intricate, fine-grained details. We validated our results on two public benchmarks through both quantitative and qualitative evaluations. Our model achieves state-of-the-art performance in three key areas: identity anonymization, facial attribute preservation, and image quality. Beyond its primary function of anonymization, our model can also perform face swapping tasks by incorporating an additional facial image as input, demonstrating its versatility and potential for diverse applications. Our code and models are available at https://github.com/hanweikung/face_anon_simple .
Normalized Avatar Synthesis Using StyleGAN and Perceptual Refinement
Jun 21, 2021


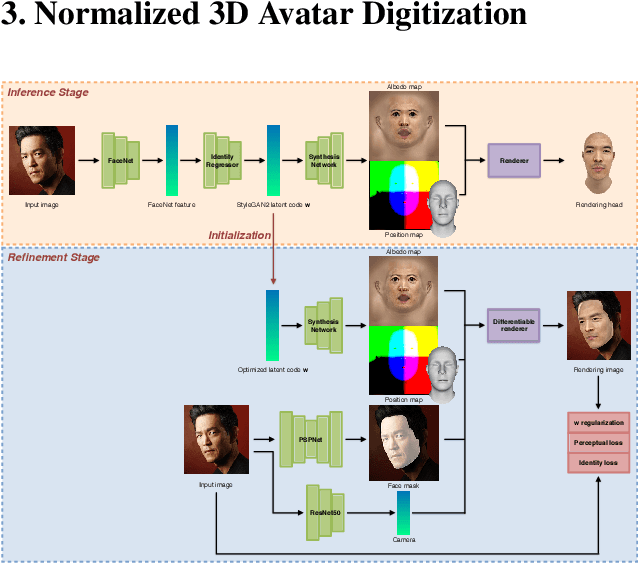
We introduce a highly robust GAN-based framework for digitizing a normalized 3D avatar of a person from a single unconstrained photo. While the input image can be of a smiling person or taken in extreme lighting conditions, our method can reliably produce a high-quality textured model of a person's face in neutral expression and skin textures under diffuse lighting condition. Cutting-edge 3D face reconstruction methods use non-linear morphable face models combined with GAN-based decoders to capture the likeness and details of a person but fail to produce neutral head models with unshaded albedo textures which is critical for creating relightable and animation-friendly avatars for integration in virtual environments. The key challenges for existing methods to work is the lack of training and ground truth data containing normalized 3D faces. We propose a two-stage approach to address this problem. First, we adopt a highly robust normalized 3D face generator by embedding a non-linear morphable face model into a StyleGAN2 network. This allows us to generate detailed but normalized facial assets. This inference is then followed by a perceptual refinement step that uses the generated assets as regularization to cope with the limited available training samples of normalized faces. We further introduce a Normalized Face Dataset, which consists of a combination photogrammetry scans, carefully selected photographs, and generated fake people with neutral expressions in diffuse lighting conditions. While our prepared dataset contains two orders of magnitude less subjects than cutting edge GAN-based 3D facial reconstruction methods, we show that it is possible to produce high-quality normalized face models for very challenging unconstrained input images, and demonstrate superior performance to the current state-of-the-art.