 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE-TIDE: Fast, Structure-Preserving Motion Forecasting from Event Sequences
Mar 29, 2026Event-based cameras capture visual information as asynchronous streams of per-pixel brightness changes, generating sparse, temporally precise data. Compared to conventional frame-based sensors, they offer significant advantages in capturing high-speed dynamics while consuming substantially less power. Predicting future event representations from past observations is an important problem, enabling downstream tasks such as future semantic segmentation or object tracking without requiring access to future sensor measurements. While recent state-of-the-art approaches achieve strong performance, they often rely on computationally heavy backbones and, in some cases, large-scale pretraining, limiting their applicability in resource-constrained scenarios. In this work, we introduce E-TIDE, a lightweight, end-to-end trainable architecture for event-tensor prediction that is designed to operate efficiently without large-scale pretraining. Our approach employs the TIDE module (Temporal Interaction for Dynamic Events), motivated by efficient spatiotemporal interaction design for sparse event tensors, to capture temporal dependencies via large-kernel mixing and activity-aware gating while maintaining low computational complexity. Experiments on standard event-based datasets demonstrate that our method achieves competitive performance with significantly reduced model size and training requirements, making it well-suited for real-time deployment under tight latency and memory budgets.
Deepfake Synthesis vs. Detection: An Uneven Contest
Feb 08, 2026The rapid advancement of deepfake technology has significantly elevated the realism and accessibility of synthetic media. Emerging techniques, such as diffusion-based models and Neural Radiance Fields (NeRF), alongside enhancements in traditional Generative Adversarial Networks (GANs), have contributed to the sophisticated generation of deepfake videos. Concurrently, deepfake detection methods have seen notable progress, driven by innovations in Transformer architectures, contrastive learning, and other machine learning approaches. In this study, we conduct a comprehensive empirical analysis of state-of-the-art deepfake detection techniques, including human evaluation experiments against cutting-edge synthesis methods. Our findings highlight a concerning trend: many state-of-the-art detection models exhibit markedly poor performance when challenged with deepfakes produced by modern synthesis techniques, including poor performance by human participants against the best quality deepfakes. Through extensive experimentation, we provide evidence that underscores the urgent need for continued refinement of detection models to keep pace with the evolving capabilities of deepfake generation technologies. This research emphasizes the critical gap between current detection methodologies and the sophistication of new generation techniques, calling for intensified efforts in this crucial area of study.
NullFace: Training-Free Localized Face Anonymization
Mar 11, 2025
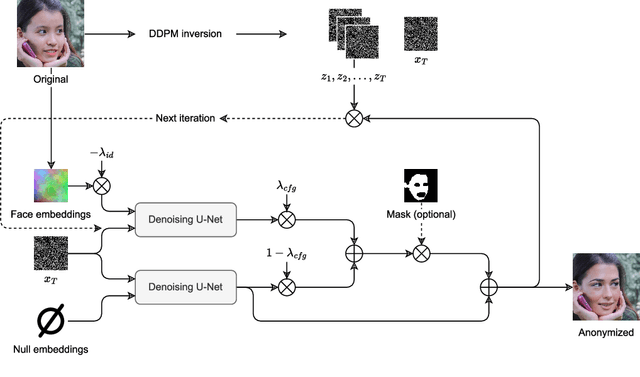


Privacy concerns around ever increasing number of cameras are increasing in today's digital age. Although existing anonymization methods are able to obscure identity information, they often struggle to preserve the utility of the images. In this work, we introduce a training-free method for face anonymization that preserves key non-identity-related attributes. Our approach utilizes a pre-trained text-to-image diffusion model without requiring optimization or training. It begins by inverting the input image to recover its initial noise. The noise is then denoised through an identity-conditioned diffusion process, where modified identity embeddings ensure the anonymized face is distinct from the original identity. Our approach also supports localized anonymization, giving users control over which facial regions are anonymized or kept intact. Comprehensive evaluations against state-of-the-art methods show our approach excels in anonymization, attribute preservation, and image quality. Its flexibility, robustness, and practicality make it well-suited for real-world applications. Code and data can be found at https://github.com/hanweikung/nullface .
KVC-onGoing: Keystroke Verification Challenge
Dec 29, 2024



This article presents the Keystroke Verification Challenge - onGoing (KVC-onGoing), on which researchers can easily benchmark their systems in a common platform using large-scale public databases, the Aalto University Keystroke databases, and a standard experimental protocol. The keystroke data consist of tweet-long sequences of variable transcript text from over 185,000 subjects, acquired through desktop and mobile keyboards simulating real-life conditions. The results on the evaluation set of KVC-onGoing have proved the high discriminative power of keystroke dynamics, reaching values as low as 3.33% of Equal Error Rate (EER) and 11.96% of False Non-Match Rate (FNMR) @1% False Match Rate (FMR) in the desktop scenario, and 3.61% of EER and 17.44% of FNMR @1% at FMR in the mobile scenario, significantly improving previous state-of-the-art results. Concerning demographic fairness, the analyzed scores reflect the subjects' age and gender to various extents, not negligible in a few cases. The framework runs on CodaLab.
Face Anonymization Made Simple
Nov 01, 2024



Current face anonymization techniques often depend on identity loss calculated by face recognition models, which can be inaccurate and unreliable. Additionally, many methods require supplementary data such as facial landmarks and masks to guide the synthesis process. In contrast, our approach uses diffusion models with only a reconstruction loss, eliminating the need for facial landmarks or masks while still producing images with intricate, fine-grained details. We validated our results on two public benchmarks through both quantitative and qualitative evaluations. Our model achieves state-of-the-art performance in three key areas: identity anonymization, facial attribute preservation, and image quality. Beyond its primary function of anonymization, our model can also perform face swapping tasks by incorporating an additional facial image as input, demonstrating its versatility and potential for diverse applications. Our code and models are available at https://github.com/hanweikung/face_anon_simple .
IEEE BigData 2023 Keystroke Verification Challenge (KVC)
Jan 29, 2024This paper describes the results of the IEEE BigData 2023 Keystroke Verification Challenge (KVC), that considers the biometric verification performance of Keystroke Dynamics (KD), captured as tweet-long sequences of variable transcript text from over 185,000 subjects. The data are obtained from two of the largest public databases of KD up to date, the Aalto Desktop and Mobile Keystroke Databases, guaranteeing a minimum amount of data per subject, age and gender annotations, absence of corrupted data, and avoiding excessively unbalanced subject distributions with respect to the considered demographic attributes. Several neural architectures were proposed by the participants, leading to global Equal Error Rates (EERs) as low as 3.33% and 3.61% achieved by the best team respectively in the desktop and mobile scenario, outperforming the current state of the art biometric verification performance for KD. Hosted on CodaLab, the KVC will be made ongoing to represent a useful tool for the research community to compare different approaches under the same experimental conditions and to deepen the knowledge of the field.
Undercover Deepfakes: Detecting Fake Segments in Videos
May 16, 2023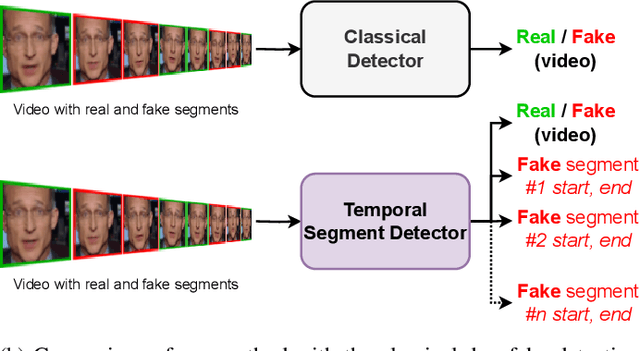
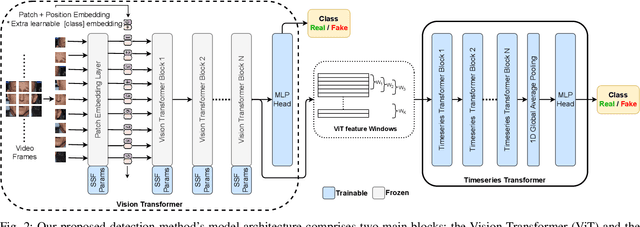

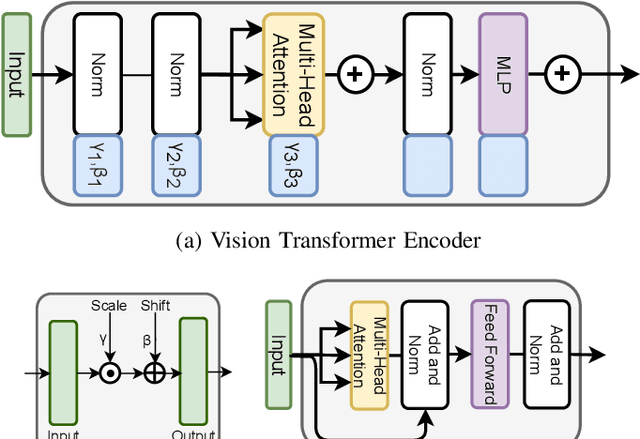
The recent renaissance in generative models, driven primarily by the advent of diffusion models and iterative improvement in GAN methods, has enabled many creative applications. However, each advancement is also accompanied by a rise in the potential for misuse. In the arena of deepfake generation this is a key societal issue. In particular, the ability to modify segments of videos using such generative techniques creates a new paradigm of deepfakes which are mostly real videos altered slightly to distort the truth. Current deepfake detection methods in the academic literature are not evaluated on this paradigm. In this paper, we present a deepfake detection method able to address this issue by performing both frame and video level deepfake prediction. To facilitate testing our method we create a new benchmark dataset where videos have both real and fake frame sequences. Our method utilizes the Vision Transformer, Scaling and Shifting pretraining and Timeseries Transformer to temporally segment videos to help facilitate the interpretation of possible deepfakes. Extensive experiments on a variety of deepfake generation methods show excellent results on temporal segmentation and classical video level predictions as well. In particular, the paradigm we introduce will form a powerful tool for the moderation of deepfakes, where human oversight can be better targeted to the parts of videos suspected of being deepfakes. All experiments can be reproduced at: https://github.com/sanjaysaha1311/temporal-deepfake-segmentation.
Is Face Recognition Safe from Realizable Attacks?
Oct 15, 2022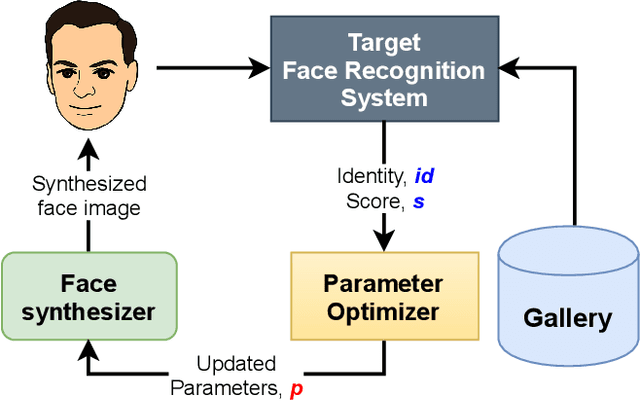



Face recognition is a popular form of biometric authentication and due to its widespread use, attacks have become more common as well. Recent studies show that Face Recognition Systems are vulnerable to attacks and can lead to erroneous identification of faces. Interestingly, most of these attacks are white-box, or they are manipulating facial images in ways that are not physically realizable. In this paper, we propose an attack scheme where the attacker can generate realistic synthesized face images with subtle perturbations and physically realize that onto his face to attack black-box face recognition systems. Comprehensive experiments and analyses show that subtle perturbations realized on attackers face can create successful attacks on state-of-the-art face recognition systems in black-box settings. Our study exposes the underlying vulnerability posed by the Face Recognition Systems against realizable black-box attacks.
Contrastive predictive coding for Anomaly Detection in Multi-variate Time Series Data
Feb 08, 2022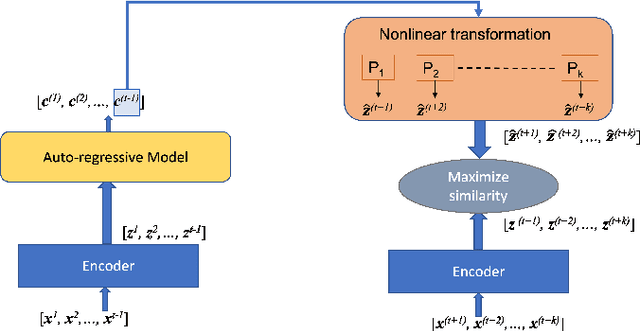


Anomaly detection in multi-variate time series (MVTS) data is a huge challenge as it requires simultaneous representation of long term temporal dependencies and correlations across multiple variables. More often, this is solved by breaking the complexity through modeling one dependency at a time. In this paper, we propose a Time-series Representational Learning through Contrastive Predictive Coding (TRL-CPC) towards anomaly detection in MVTS data. First, we jointly optimize an encoder, an auto-regressor and a non-linear transformation function to effectively learn the representations of the MVTS data sets, for predicting future trends. It must be noted that the context vectors are representative of the observation window in the MTVS. Next, the latent representations for the succeeding instants obtained through non-linear transformations of these context vectors, are contrasted with the latent representations of the encoder for the multi-variables such that the density for the positive pair is maximized. Thus, the TRL-CPC helps to model the temporal dependencies and the correlations of the parameters for a healthy signal pattern. Finally, fitting the latent representations are fit into a Gaussian scoring function to detect anomalies. Evaluation of the proposed TRL-CPC on three MVTS data sets against SOTA anomaly detection methods shows the superiority of TRL-CPC.
Understanding Humans in Crowded Scenes: Deep Nested Adversarial Learning and A New Benchmark for Multi-Human Parsing
Jul 06, 2018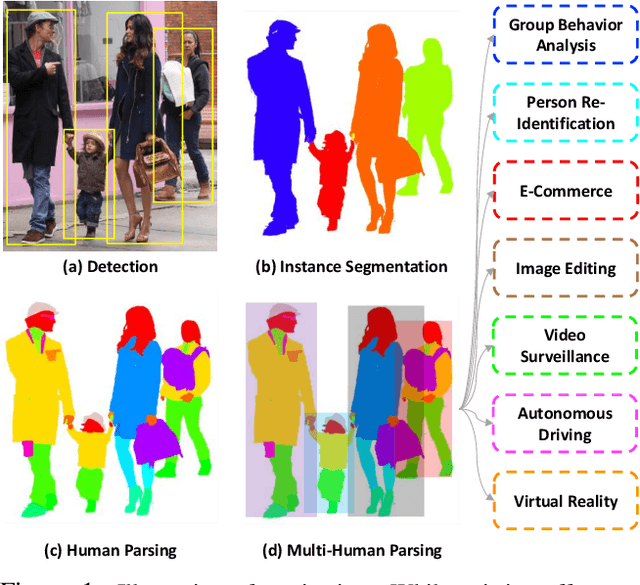
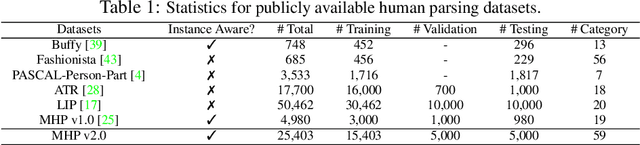

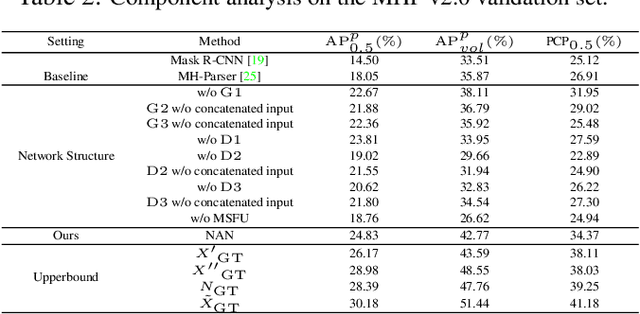
Despite the noticeable progress in perceptual tasks like detection, instance segmentation and human parsing, computers still perform unsatisfactorily on visually understanding humans in crowded scenes, such as group behavior analysis, person re-identification and autonomous driving, etc. To this end, models need to comprehensively perceive the semantic information and the differences between instances in a multi-human image, which is recently defined as the multi-human parsing task. In this paper, we present a new large-scale database "Multi-Human Parsing (MHP)" for algorithm development and evaluation, and advances the state-of-the-art in understanding humans in crowded scenes. MHP contains 25,403 elaborately annotated images with 58 fine-grained semantic category labels, involving 2-26 persons per image and captured in real-world scenes from various viewpoints, poses, occlusion, interactions and background. We further propose a novel deep Nested Adversarial Network (NAN) model for multi-human parsing. NAN consists of three Generative Adversarial Network (GAN)-like sub-nets, respectively performing semantic saliency prediction, instance-agnostic parsing and instance-aware clustering. These sub-nets form a nested structure and are carefully designed to learn jointly in an end-to-end way. NAN consistently outperforms existing state-of-the-art solutions on our MHP and several other datasets, and serves as a strong baseline to drive the future research for multi-human parsing.