 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTT-MPD: Test Time Model Pruning and Distillation
Dec 10, 2024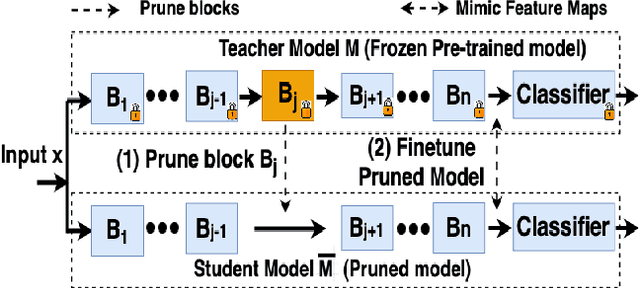

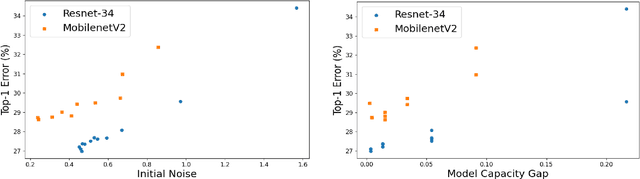
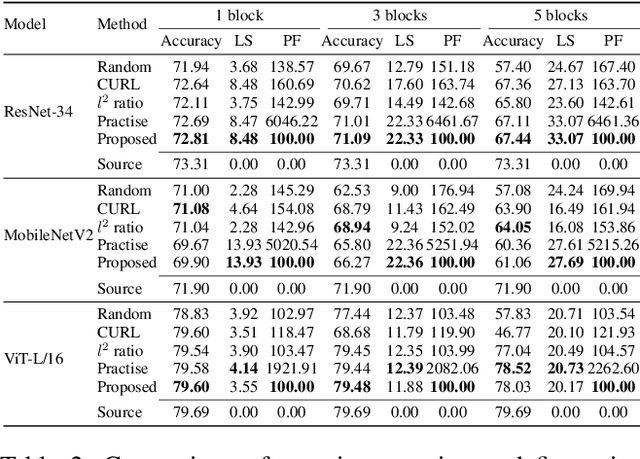
Pruning can be an effective method of compressing large pre-trained models for inference speed acceleration. Previous pruning approaches rely on access to the original training dataset for both pruning and subsequent fine-tuning. However, access to the training data can be limited due to concerns such as data privacy and commercial confidentiality. Furthermore, with covariate shift (disparities between test and training data distributions), pruning and finetuning with training datasets can hinder the generalization of the pruned model to test data. To address these issues, pruning and finetuning the model with test time samples becomes essential. However, test-time model pruning and fine-tuning incur additional computation costs and slow down the model's prediction speed, thus posing efficiency issues. Existing pruning methods are not efficient enough for test time model pruning setting, since finetuning the pruned model is needed to evaluate the importance of removable components. To address this, we propose two variables to approximate the fine-tuned accuracy. We then introduce an efficient pruning method that considers the approximated finetuned accuracy and potential inference latency saving. To enhance fine-tuning efficiency, we propose an efficient knowledge distillation method that only needs to generate pseudo labels for a small set of finetuning samples one time, thereby reducing the expensive pseudo-label generation cost. Experimental results demonstrate that our method achieves a comparable or superior tradeoff between test accuracy and inference latency, with a 32% relative reduction in pruning and finetuning time compared to the best existing method.
AniFaceDiff: High-Fidelity Face Reenactment via Facial Parametric Conditioned Diffusion Models
Jun 19, 2024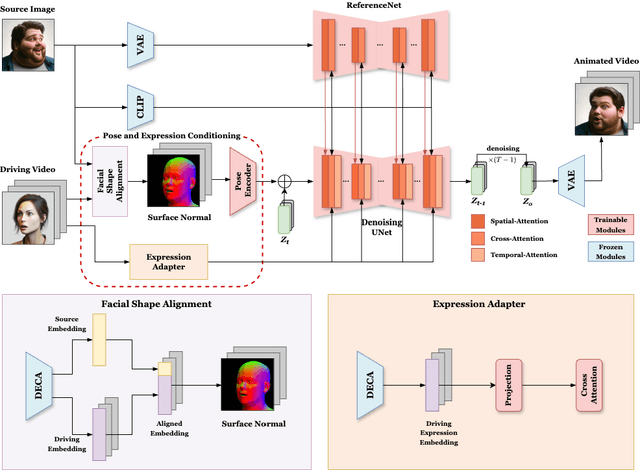
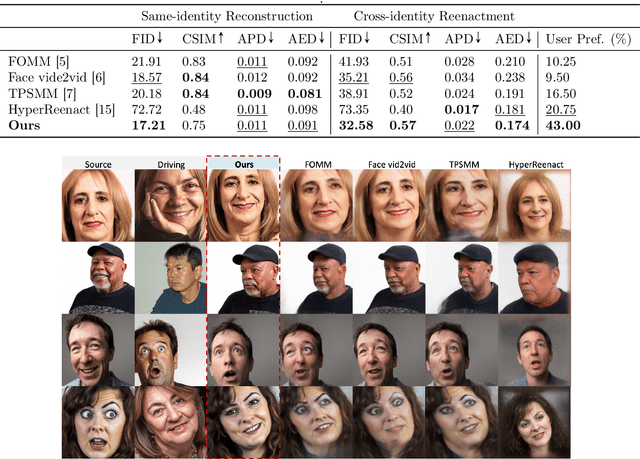
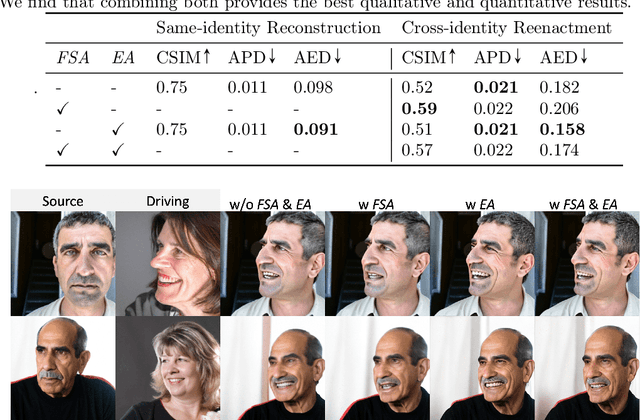

Face reenactment refers to the process of transferring the pose and facial expressions from a reference (driving) video onto a static facial (source) image while maintaining the original identity of the source image. Previous research in this domain has made significant progress by training controllable deep generative models to generate faces based on specific identity, pose and expression conditions. However, the mechanisms used in these methods to control pose and expression often inadvertently introduce identity information from the driving video, while also causing a loss of expression-related details. This paper proposes a new method based on Stable Diffusion, called AniFaceDiff, incorporating a new conditioning module for high-fidelity face reenactment. First, we propose an enhanced 2D facial snapshot conditioning approach by facial shape alignment to prevent the inclusion of identity information from the driving video. Then, we introduce an expression adapter conditioning mechanism to address the potential loss of expression-related information. Our approach effectively preserves pose and expression fidelity from the driving video while retaining the identity and fine details of the source image. Through experiments on the VoxCeleb dataset, we demonstrate that our method achieves state-of-the-art results in face reenactment, showcasing superior image quality, identity preservation, and expression accuracy, especially for cross-identity scenarios. Considering the ethical concerns surrounding potential misuse, we analyze the implications of our method, evaluate current state-of-the-art deepfake detectors, and identify their shortcomings to guide future research.
When To Grow? A Fitting Risk-Aware Policy for Layer Growing in Deep Neural Networks
Jan 06, 2024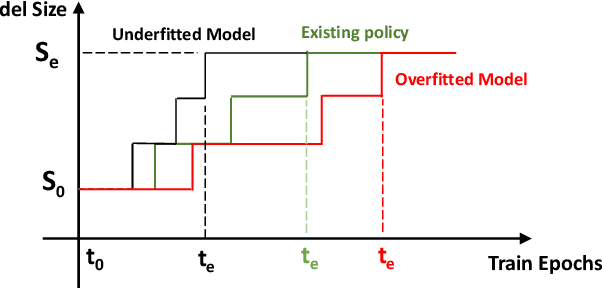
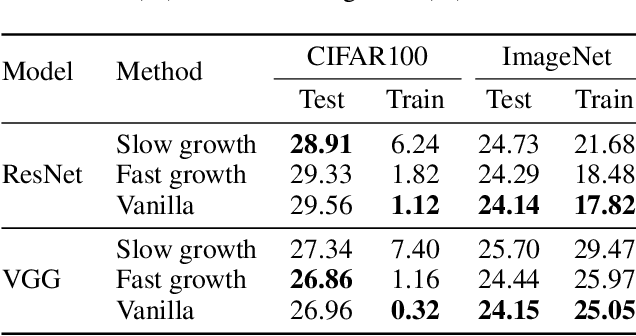
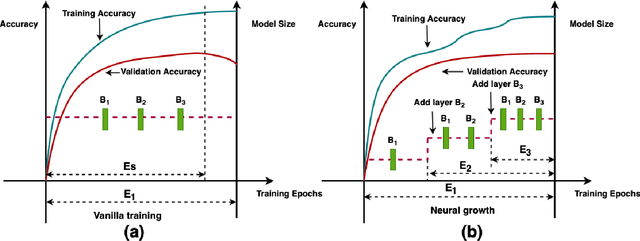
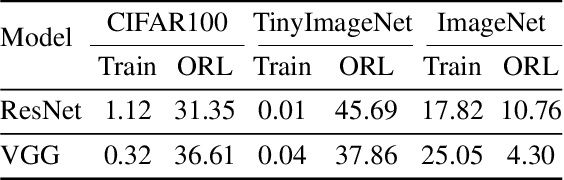
Neural growth is the process of growing a small neural network to a large network and has been utilized to accelerate the training of deep neural networks. One crucial aspect of neural growth is determining the optimal growth timing. However, few studies investigate this systematically. Our study reveals that neural growth inherently exhibits a regularization effect, whose intensity is influenced by the chosen policy for growth timing. While this regularization effect may mitigate the overfitting risk of the model, it may lead to a notable accuracy drop when the model underfits. Yet, current approaches have not addressed this issue due to their lack of consideration of the regularization effect from neural growth. Motivated by these findings, we propose an under/over fitting risk-aware growth timing policy, which automatically adjusts the growth timing informed by the level of potential under/overfitting risks to address both risks. Comprehensive experiments conducted using CIFAR-10/100 and ImageNet datasets show that the proposed policy achieves accuracy improvements of up to 1.3% in models prone to underfitting while achieving similar accuracies in models suffering from overfitting compared to the existing methods.
NAPA-VQ: Neighborhood Aware Prototype Augmentation with Vector Quantization for Continual Learning
Aug 18, 2023



Catastrophic forgetting; the loss of old knowledge upon acquiring new knowledge, is a pitfall faced by deep neural networks in real-world applications. Many prevailing solutions to this problem rely on storing exemplars (previously encountered data), which may not be feasible in applications with memory limitations or privacy constraints. Therefore, the recent focus has been on Non-Exemplar based Class Incremental Learning (NECIL) where a model incrementally learns about new classes without using any past exemplars. However, due to the lack of old data, NECIL methods struggle to discriminate between old and new classes causing their feature representations to overlap. We propose NAPA-VQ: Neighborhood Aware Prototype Augmentation with Vector Quantization, a framework that reduces this class overlap in NECIL. We draw inspiration from Neural Gas to learn the topological relationships in the feature space, identifying the neighboring classes that are most likely to get confused with each other. This neighborhood information is utilized to enforce strong separation between the neighboring classes as well as to generate old class representative prototypes that can better aid in obtaining a discriminative decision boundary between old and new classes. Our comprehensive experiments on CIFAR-100, TinyImageNet, and ImageNet-Subset demonstrate that NAPA-VQ outperforms the State-of-the-art NECIL methods by an average improvement of 5%, 2%, and 4% in accuracy and 10%, 3%, and 9% in forgetting respectively. Our code can be found in https://github.com/TamashaM/NAPA-VQ.git.
Undercover Deepfakes: Detecting Fake Segments in Videos
May 16, 2023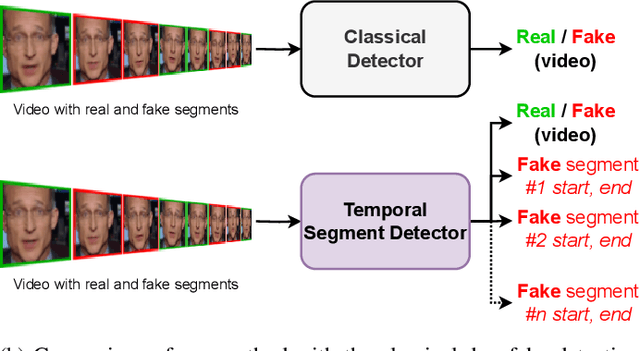
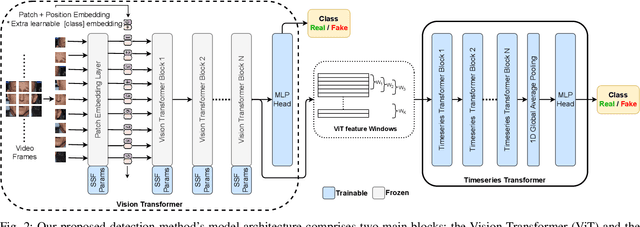

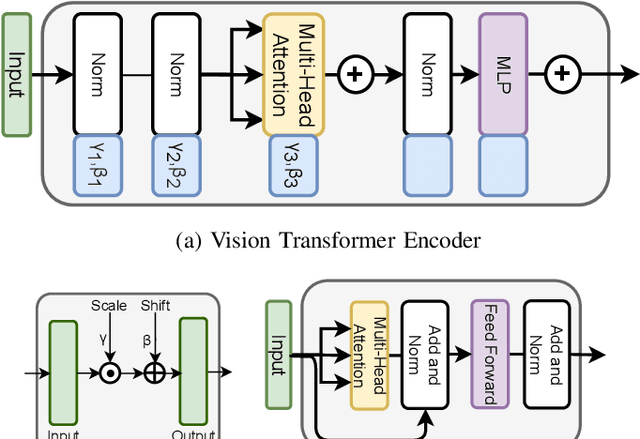
The recent renaissance in generative models, driven primarily by the advent of diffusion models and iterative improvement in GAN methods, has enabled many creative applications. However, each advancement is also accompanied by a rise in the potential for misuse. In the arena of deepfake generation this is a key societal issue. In particular, the ability to modify segments of videos using such generative techniques creates a new paradigm of deepfakes which are mostly real videos altered slightly to distort the truth. Current deepfake detection methods in the academic literature are not evaluated on this paradigm. In this paper, we present a deepfake detection method able to address this issue by performing both frame and video level deepfake prediction. To facilitate testing our method we create a new benchmark dataset where videos have both real and fake frame sequences. Our method utilizes the Vision Transformer, Scaling and Shifting pretraining and Timeseries Transformer to temporally segment videos to help facilitate the interpretation of possible deepfakes. Extensive experiments on a variety of deepfake generation methods show excellent results on temporal segmentation and classical video level predictions as well. In particular, the paradigm we introduce will form a powerful tool for the moderation of deepfakes, where human oversight can be better targeted to the parts of videos suspected of being deepfakes. All experiments can be reproduced at: https://github.com/sanjaysaha1311/temporal-deepfake-segmentation.