 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAniFaceDiff: High-Fidelity Face Reenactment via Facial Parametric Conditioned Diffusion Models
Paper and Code
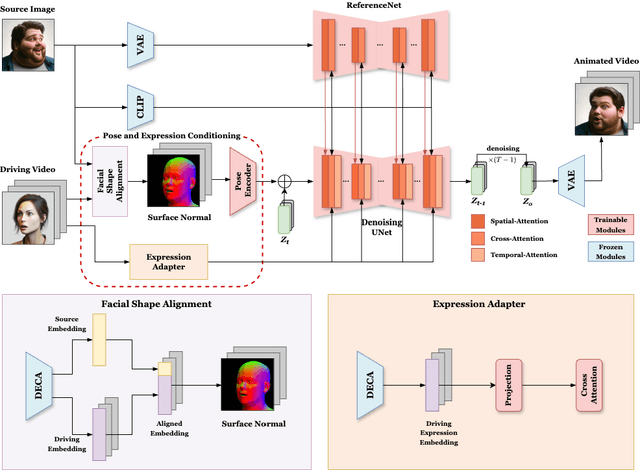
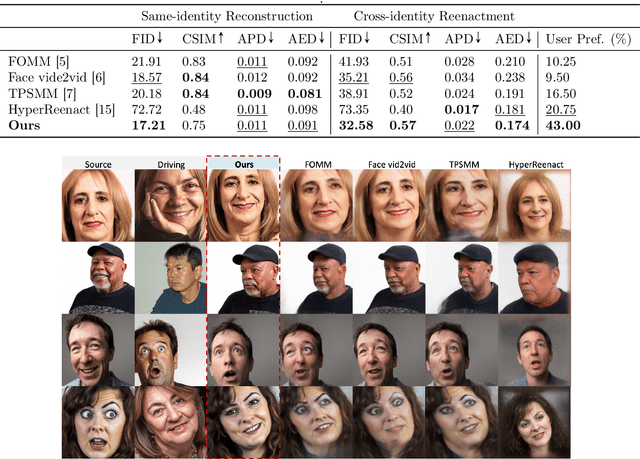
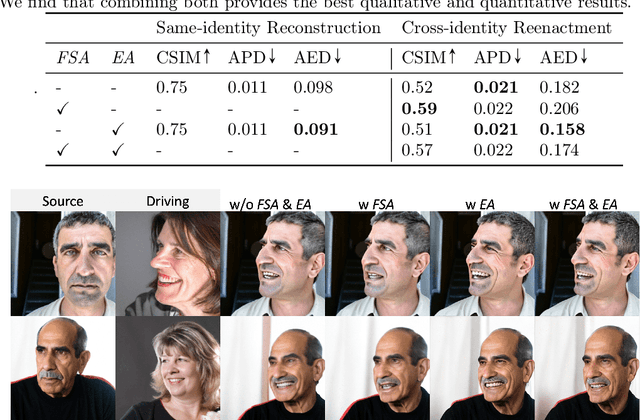

Face reenactment refers to the process of transferring the pose and facial expressions from a reference (driving) video onto a static facial (source) image while maintaining the original identity of the source image. Previous research in this domain has made significant progress by training controllable deep generative models to generate faces based on specific identity, pose and expression conditions. However, the mechanisms used in these methods to control pose and expression often inadvertently introduce identity information from the driving video, while also causing a loss of expression-related details. This paper proposes a new method based on Stable Diffusion, called AniFaceDiff, incorporating a new conditioning module for high-fidelity face reenactment. First, we propose an enhanced 2D facial snapshot conditioning approach by facial shape alignment to prevent the inclusion of identity information from the driving video. Then, we introduce an expression adapter conditioning mechanism to address the potential loss of expression-related information. Our approach effectively preserves pose and expression fidelity from the driving video while retaining the identity and fine details of the source image. Through experiments on the VoxCeleb dataset, we demonstrate that our method achieves state-of-the-art results in face reenactment, showcasing superior image quality, identity preservation, and expression accuracy, especially for cross-identity scenarios. Considering the ethical concerns surrounding potential misuse, we analyze the implications of our method, evaluate current state-of-the-art deepfake detectors, and identify their shortcomings to guide future research.