 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Process-Outcome Credit in Multi-Step LLM Reasoning
Feb 01, 2026Reinforcement Learning (RL) serves as a potent paradigm for enhancing reasoning capabilities in Large Language Models (LLMs), yet standard outcome-based approaches often suffer from reward sparsity and inefficient credit assignment. In this paper, we propose a novel framework designed to provide continuous reward signals, which introduces a Step-wise Marginal Information Gain (MIG) mechanism that quantifies the intrinsic value of reasoning steps against a Monotonic Historical Watermark, effectively filtering out training noise. To ensure disentangled credit distribution, we implement a Decoupled Masking Strategy, applying process-oriented rewards specifically to the chain-of-thought (CoT) and outcome-oriented rewards to the full completion. Additionally, we incorporate a Dual-Gated SFT objective to stabilize training with high-quality structural and factual signals. Extensive experiments across textual and multi-modal benchmarks (e.g., MATH, Super-CLEVR) demonstrate that our approach consistently outperforms baselines such as GRPO in both sample efficiency and final accuracy. Furthermore, our model exhibits superior out-of-distribution robustness, demonstrating promising zero-shot transfer capabilities to unseen and challenging reasoning tasks.
Graph-Eq: Discovering Mathematical Equations using Graph Generative Models
Mar 30, 2025The ability to discover meaningful, accurate, and concise mathematical equations that describe datasets is valuable across various domains. Equations offer explicit relationships between variables, enabling deeper insights into underlying data patterns. Most existing equation discovery methods rely on genetic programming, which iteratively searches the equation space but is often slow and prone to overfitting. By representing equations as directed acyclic graphs, we leverage the use of graph neural networks to learn the underlying semantics of equations, and generate new, previously unseen equations. Although graph generative models have been shown to be successful in discovering new types of graphs in many fields, there application in discovering equations remains largely unexplored. In this work, we propose Graph-EQ, a deep graph generative model designed for efficient equation discovery. Graph-EQ uses a conditional variational autoencoder (CVAE) to learn a rich latent representation of the equation space by training it on a large corpus of equations in an unsupervised manner. Instead of directly searching the equation space, we employ Bayesian optimization to efficiently explore this learned latent space. We show that the encoder-decoder architecture of Graph-Eq is able to accurately reconstruct input equations. Moreover, we show that the learned latent representation can be sampled and decoded into valid equations, including new and previously unseen equations in the training data. Finally, we assess Graph-Eq's ability to discover equations that best fit a dataset by exploring the latent space using Bayesian optimization. Latent space exploration is done on 20 dataset with known ground-truth equations, and Graph-Eq is shown to successfully discover the grountruth equation in the majority of datasets.
Arch-LLM: Taming LLMs for Neural Architecture Generation via Unsupervised Discrete Representation Learning
Mar 28, 2025Unsupervised representation learning has been widely explored across various modalities, including neural architectures, where it plays a key role in downstream applications like Neural Architecture Search (NAS). These methods typically learn an unsupervised representation space before generating/ sampling architectures for the downstream search. A common approach involves the use of Variational Autoencoders (VAEs) to map discrete architectures onto a continuous representation space, however, sampling from these spaces often leads to a high percentage of invalid or duplicate neural architectures. This could be due to the unnatural mapping of inherently discrete architectural space onto a continuous space, which emphasizes the need for a robust discrete representation of these architectures. To address this, we introduce a Vector Quantized Variational Autoencoder (VQ-VAE) to learn a discrete latent space more naturally aligned with the discrete neural architectures. In contrast to VAEs, VQ-VAEs (i) map each architecture into a discrete code sequence and (ii) allow the prior to be learned by any generative model rather than assuming a normal distribution. We then represent these architecture latent codes as numerical sequences and train a text-to-text model leveraging a Large Language Model to learn and generate sequences representing architectures. We experiment our method with Inception/ ResNet-like cell-based search spaces, namely NAS-Bench-101 and NAS-Bench-201. Compared to VAE-based methods, our approach improves the generation of valid and unique architectures by over 80% on NASBench-101 and over 8% on NASBench-201. Finally, we demonstrate the applicability of our method in NAS employing a sequence-modeling-based NAS algorithm.
Unmasking the Unknown: Facial Deepfake Detection in the Open-Set Paradigm
Mar 11, 2025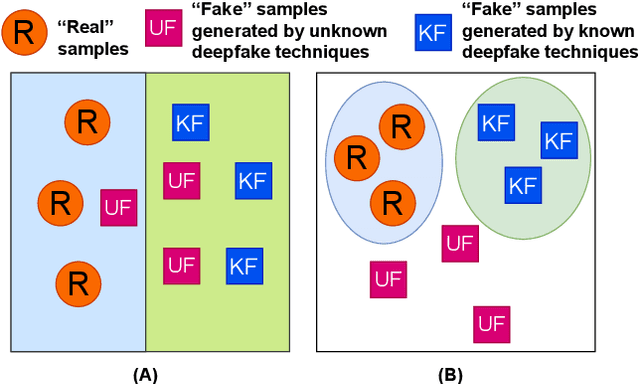
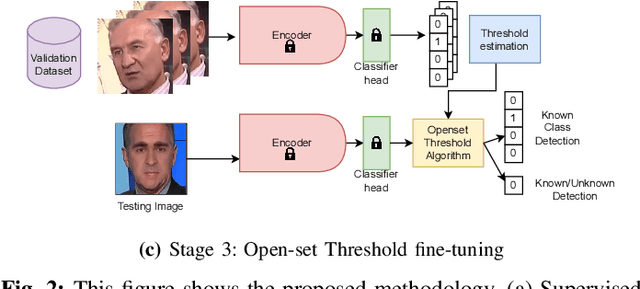
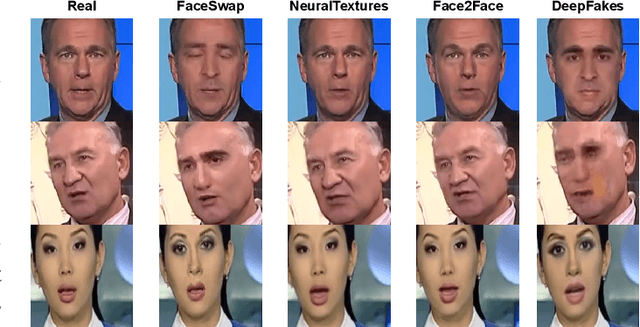
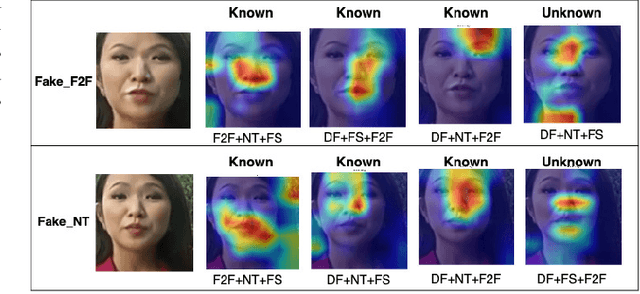
Facial forgery methods such as deepfakes can be misused for identity manipulation and spreading misinformation. They have evolved alongside advancements in generative AI, leading to new and more sophisticated forgery techniques that diverge from existing 'known' methods. Conventional deepfake detection methods use the closedset paradigm, thus limiting their applicability to detecting forgeries created using methods that are not part of the training dataset. In this paper, we propose a shift from the closed-set paradigm for deepfake detection. In the open-set paradigm, models are designed not only to identify images created by known facial forgery methods but also to identify and flag those produced by previously unknown methods as 'unknown' and not as unforged/real/unmanipulated. In this paper, we propose an open-set deepfake classification algorithm based on supervised contrastive learning. The open-set paradigm used in our model allows it to function as a more robust tool capable of handling emerging and unseen deepfake techniques, enhancing reliability and confidence, and complementing forensic analysis. In open-set paradigm, we identify three groups including the "unknown group that is neither considered known deepfake nor real. We investigate deepfake open-set classification across three scenarios, classifying deepfakes from unknown methods not as real, distinguishing real images from deepfakes, and classifying deepfakes from known methods, using the FaceForensics++ dataset as a benchmark. Our method achieves state of the art results in the first two tasks and competitive results in the third task.
SphOR: A Representation Learning Perspective on Open-set Recognition for Identifying Unknown Classes in Deep Learning Models
Mar 11, 2025The widespread use of deep learning classifiers necessitates Open-set recognition (OSR), which enables the identification of input data not only from classes known during training but also from unknown classes that might be present in test data. Many existing OSR methods are computationally expensive due to the reliance on complex generative models or suffer from high training costs. We investigate OSR from a representation-learning perspective, specifically through spherical embeddings. We introduce SphOR, a computationally efficient representation learning method that models the feature space as a mixture of von Mises-Fisher distributions. This approach enables the use of semantically ambiguous samples during training, to improve the detection of samples from unknown classes. We further explore the relationship between OSR performance and key representation learning properties which influence how well features are structured in high-dimensional space. Extensive experiments on multiple OSR benchmarks demonstrate the effectiveness of our method, producing state-of-the-art results, with improvements up-to 6% that validate its performance.
TT-MPD: Test Time Model Pruning and Distillation
Dec 10, 2024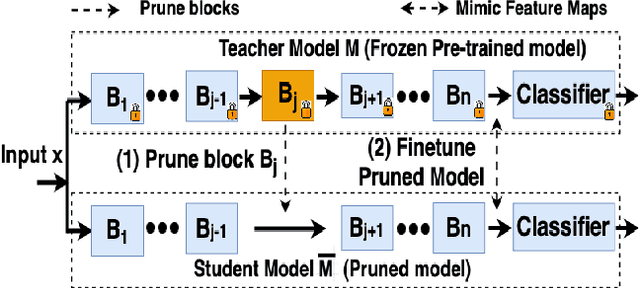

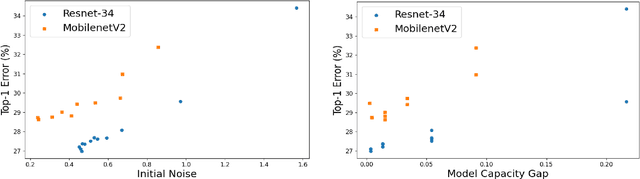
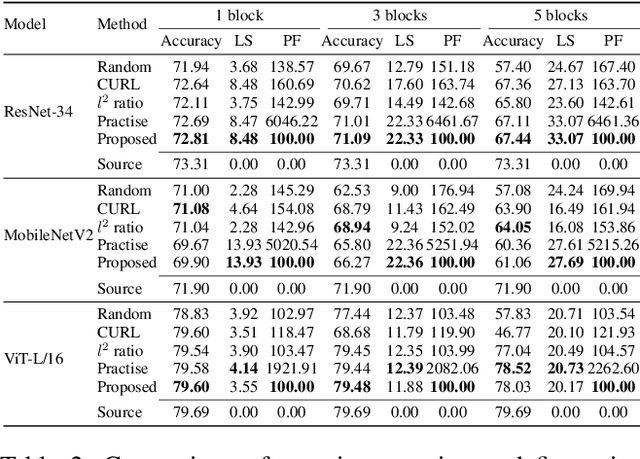
Pruning can be an effective method of compressing large pre-trained models for inference speed acceleration. Previous pruning approaches rely on access to the original training dataset for both pruning and subsequent fine-tuning. However, access to the training data can be limited due to concerns such as data privacy and commercial confidentiality. Furthermore, with covariate shift (disparities between test and training data distributions), pruning and finetuning with training datasets can hinder the generalization of the pruned model to test data. To address these issues, pruning and finetuning the model with test time samples becomes essential. However, test-time model pruning and fine-tuning incur additional computation costs and slow down the model's prediction speed, thus posing efficiency issues. Existing pruning methods are not efficient enough for test time model pruning setting, since finetuning the pruned model is needed to evaluate the importance of removable components. To address this, we propose two variables to approximate the fine-tuned accuracy. We then introduce an efficient pruning method that considers the approximated finetuned accuracy and potential inference latency saving. To enhance fine-tuning efficiency, we propose an efficient knowledge distillation method that only needs to generate pseudo labels for a small set of finetuning samples one time, thereby reducing the expensive pseudo-label generation cost. Experimental results demonstrate that our method achieves a comparable or superior tradeoff between test accuracy and inference latency, with a 32% relative reduction in pruning and finetuning time compared to the best existing method.
Rethinking Time Series Forecasting with LLMs via Nearest Neighbor Contrastive Learning
Dec 06, 2024



Adapting Large Language Models (LLMs) that are extensively trained on abundant text data, and customizing the input prompt to enable time series forecasting has received considerable attention. While recent work has shown great potential for adapting the learned prior of LLMs, the formulation of the prompt to finetune LLMs remains challenging as prompt should be aligned with time series data. Additionally, current approaches do not effectively leverage word token embeddings which embody the rich representation space learned by LLMs. This emphasizes the need for a robust approach to formulate the prompt which utilizes the word token embeddings while effectively representing the characteristics of the time series. To address these challenges, we propose NNCL-TLLM: Nearest Neighbor Contrastive Learning for Time series forecasting via LLMs. First, we generate time series compatible text prototypes such that each text prototype represents both word token embeddings in its neighborhood and time series characteristics via end-to-end finetuning. Next, we draw inspiration from Nearest Neighbor Contrastive Learning to formulate the prompt while obtaining the top-$k$ nearest neighbor time series compatible text prototypes. We then fine-tune the layer normalization and positional embeddings of the LLM, keeping the other layers intact, reducing the trainable parameters and decreasing the computational cost. Our comprehensive experiments demonstrate that NNCL-TLLM outperforms in few-shot forecasting while achieving competitive or superior performance over the state-of-the-art methods in long-term and short-term forecasting tasks.
Distributed solar generation forecasting using attention-based deep neural networks for cloud movement prediction
Nov 17, 2024



Accurate forecasts of distributed solar generation are necessary to reduce negative impacts resulting from the increased uptake of distributed solar photovoltaic (PV) systems. However, the high variability of solar generation over short time intervals (seconds to minutes) caused by cloud movement makes this forecasting task difficult. To address this, using cloud images, which capture the second-to-second changes in cloud cover affecting solar generation, has shown promise. Recently, deep neural networks with "attention" that focus on important regions of an image have been applied with success in many computer vision applications. However, their use for forecasting cloud movement has not yet been extensively explored. In this work, we propose an attention-based convolutional long short-term memory network to forecast cloud movement and apply an existing self-attention-based method previously proposed for video prediction to forecast cloud movement. We investigate and discuss the impact of cloud forecasts from attention-based methods towards forecasting distributed solar generation, compared to cloud forecasts from non-attention-based methods. We further provide insights into the different solar forecast performances that can be achieved for high and low altitude clouds. We find that for clouds at high altitudes, the cloud predictions obtained using attention-based methods result in solar forecast skill score improvements of 5.86% or more compared to non-attention-based methods.
GINN-KAN: Interpretability pipelining with applications in Physics Informed Neural Networks
Aug 27, 2024Neural networks are powerful function approximators, yet their ``black-box" nature often renders them opaque and difficult to interpret. While many post-hoc explanation methods exist, they typically fail to capture the underlying reasoning processes of the networks. A truly interpretable neural network would be trained similarly to conventional models using techniques such as backpropagation, but additionally provide insights into the learned input-output relationships. In this work, we introduce the concept of interpretability pipelineing, to incorporate multiple interpretability techniques to outperform each individual technique. To this end, we first evaluate several architectures that promise such interpretability, with a particular focus on two recent models selected for their potential to incorporate interpretability into standard neural network architectures while still leveraging backpropagation: the Growing Interpretable Neural Network (GINN) and Kolmogorov Arnold Networks (KAN). We analyze the limitations and strengths of each and introduce a novel interpretable neural network GINN-KAN that synthesizes the advantages of both models. When tested on the Feynman symbolic regression benchmark datasets, GINN-KAN outperforms both GINN and KAN. To highlight the capabilities and the generalizability of this approach, we position GINN-KAN as an alternative to conventional black-box networks in Physics-Informed Neural Networks (PINNs). We expect this to have far-reaching implications in the application of deep learning pipelines in the natural sciences. Our experiments with this interpretable PINN on 15 different partial differential equations demonstrate that GINN-KAN augmented PINNs outperform PINNs with black-box networks in solving differential equations and surpass the capabilities of both GINN and KAN.
AniFaceDiff: High-Fidelity Face Reenactment via Facial Parametric Conditioned Diffusion Models
Jun 19, 2024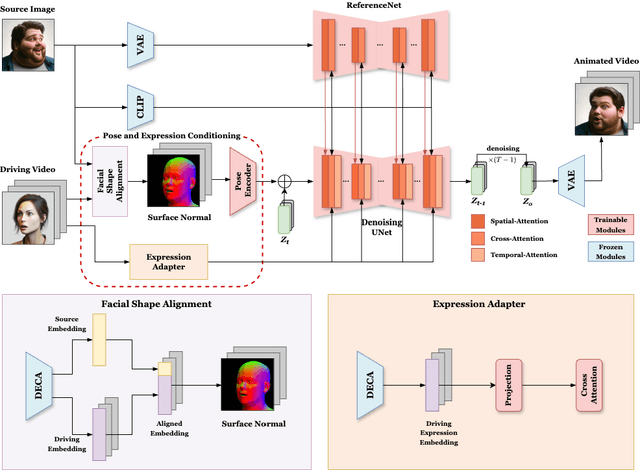
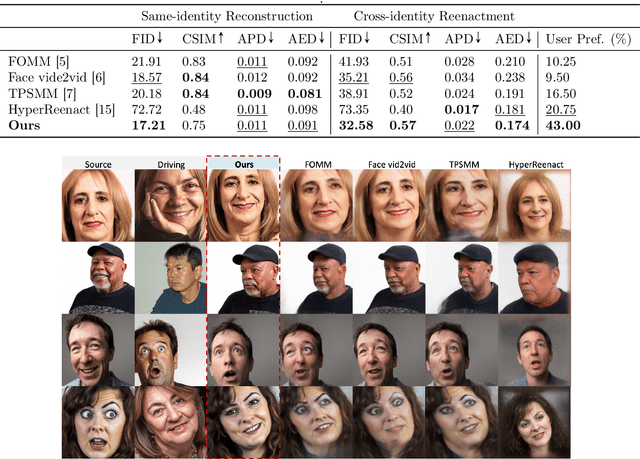
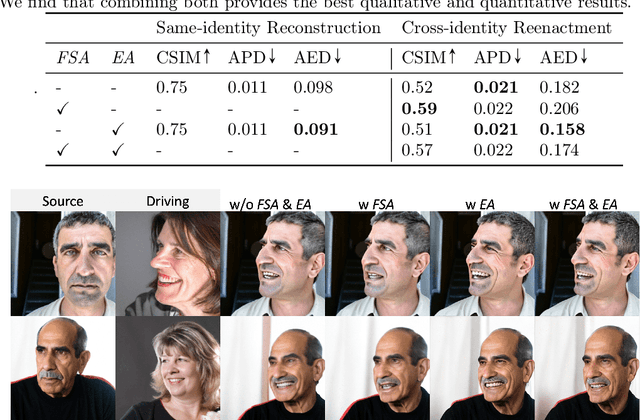

Face reenactment refers to the process of transferring the pose and facial expressions from a reference (driving) video onto a static facial (source) image while maintaining the original identity of the source image. Previous research in this domain has made significant progress by training controllable deep generative models to generate faces based on specific identity, pose and expression conditions. However, the mechanisms used in these methods to control pose and expression often inadvertently introduce identity information from the driving video, while also causing a loss of expression-related details. This paper proposes a new method based on Stable Diffusion, called AniFaceDiff, incorporating a new conditioning module for high-fidelity face reenactment. First, we propose an enhanced 2D facial snapshot conditioning approach by facial shape alignment to prevent the inclusion of identity information from the driving video. Then, we introduce an expression adapter conditioning mechanism to address the potential loss of expression-related information. Our approach effectively preserves pose and expression fidelity from the driving video while retaining the identity and fine details of the source image. Through experiments on the VoxCeleb dataset, we demonstrate that our method achieves state-of-the-art results in face reenactment, showcasing superior image quality, identity preservation, and expression accuracy, especially for cross-identity scenarios. Considering the ethical concerns surrounding potential misuse, we analyze the implications of our method, evaluate current state-of-the-art deepfake detectors, and identify their shortcomings to guide future research.