 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTT-MPD: Test Time Model Pruning and Distillation
Paper and Code
Dec 10, 2024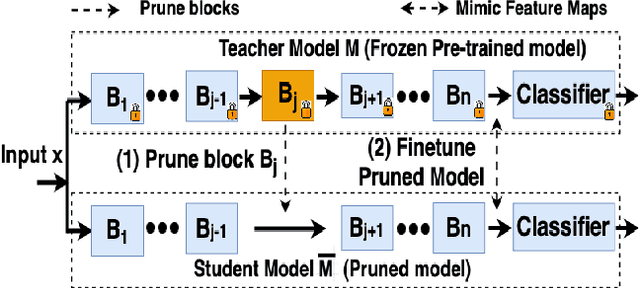

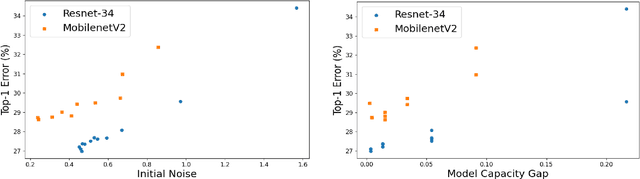
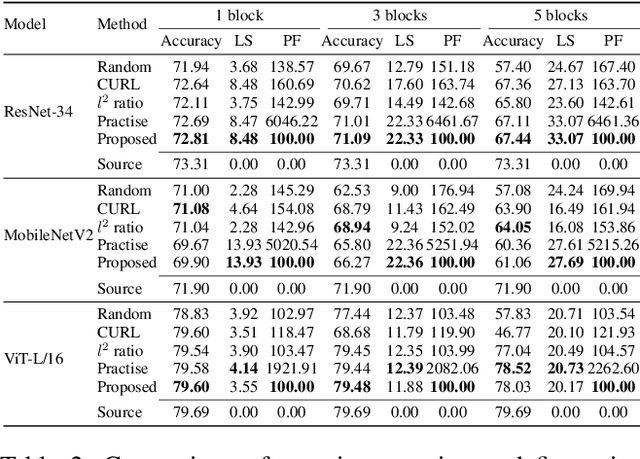
Pruning can be an effective method of compressing large pre-trained models for inference speed acceleration. Previous pruning approaches rely on access to the original training dataset for both pruning and subsequent fine-tuning. However, access to the training data can be limited due to concerns such as data privacy and commercial confidentiality. Furthermore, with covariate shift (disparities between test and training data distributions), pruning and finetuning with training datasets can hinder the generalization of the pruned model to test data. To address these issues, pruning and finetuning the model with test time samples becomes essential. However, test-time model pruning and fine-tuning incur additional computation costs and slow down the model's prediction speed, thus posing efficiency issues. Existing pruning methods are not efficient enough for test time model pruning setting, since finetuning the pruned model is needed to evaluate the importance of removable components. To address this, we propose two variables to approximate the fine-tuned accuracy. We then introduce an efficient pruning method that considers the approximated finetuned accuracy and potential inference latency saving. To enhance fine-tuning efficiency, we propose an efficient knowledge distillation method that only needs to generate pseudo labels for a small set of finetuning samples one time, thereby reducing the expensive pseudo-label generation cost. Experimental results demonstrate that our method achieves a comparable or superior tradeoff between test accuracy and inference latency, with a 32% relative reduction in pruning and finetuning time compared to the best existing method.