 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTT-MPD: Test Time Model Pruning and Distillation
Dec 10, 2024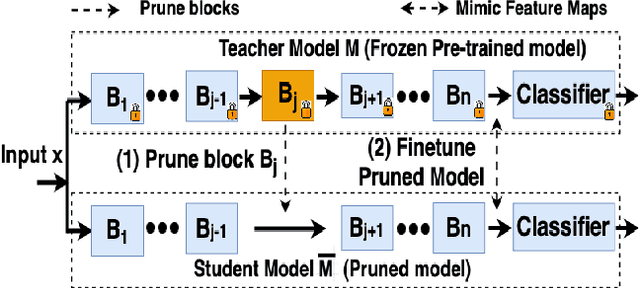

Pruning can be an effective method of compressing large pre-trained models for inference speed acceleration. Previous pruning approaches rely on access to the original training dataset for both pruning and subsequent fine-tuning. However, access to the training data can be limited due to concerns such as data privacy and commercial confidentiality. Furthermore, with covariate shift (disparities between test and training data distributions), pruning and finetuning with training datasets can hinder the generalization of the pruned model to test data. To address these issues, pruning and finetuning the model with test time samples becomes essential. However, test-time model pruning and fine-tuning incur additional computation costs and slow down the model's prediction speed, thus posing efficiency issues. Existing pruning methods are not efficient enough for test time model pruning setting, since finetuning the pruned model is needed to evaluate the importance of removable components. To address this, we propose two variables to approximate the fine-tuned accuracy. We then introduce an efficient pruning method that considers the approximated finetuned accuracy and potential inference latency saving. To enhance fine-tuning efficiency, we propose an efficient knowledge distillation method that only needs to generate pseudo labels for a small set of finetuning samples one time, thereby reducing the expensive pseudo-label generation cost. Experimental results demonstrate that our method achieves a comparable or superior tradeoff between test accuracy and inference latency, with a 32% relative reduction in pruning and finetuning time compared to the best existing method.
LLM-BIP: Structured Pruning for Large Language Models with Block-Wise Forward Importance Propagation
Dec 09, 2024



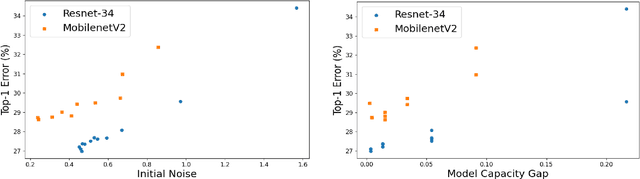
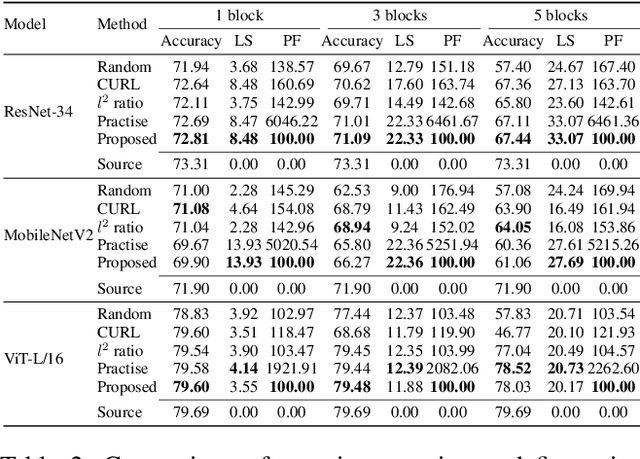
Large language models (LLMs) have demonstrated remarkable performance across various language tasks, but their widespread deployment is impeded by their large size and high computational costs. Structural pruning is a prevailing technique used to introduce sparsity into pre-trained models and facilitate direct hardware acceleration during inference by removing redundant connections (structurally-grouped parameters), such as channels and attention heads. Existing structural pruning approaches often employ either global or layer-wise pruning criteria; however, they are hindered by ineffectiveness stemming from inaccurate evaluation of connection importance. Global pruning methods typically assess component importance using near-zero and unreliable gradients, while layer-wise pruning approaches encounter significant pruning error accumulation issues. To this end, we propose a more accurate pruning metric based on the block-wise importance score propagation, termed LLM-BIP. Specifically, LLM-BIP precisely evaluates connection importance by gauging its influence on the respective transformer block output, which can be efficiently approximated in a single forward pass through an upper bound derived from the assumption of Lipschitz continuity. We evaluate the proposed method using LLaMA-7B, Vicuna-7B, and LLaMA-13B across common zero-shot tasks. The results demonstrate that our approach achieves an average of 3.26% increase in accuracy for common reasoning tasks compared to previous best baselines. It also reduces perplexity by 14.09 and 68.76 on average for the WikiText2 dataset and PTB dataset, respectively.
When To Grow? A Fitting Risk-Aware Policy for Layer Growing in Deep Neural Networks
Jan 06, 2024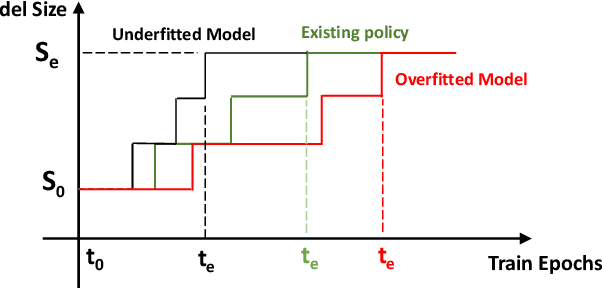
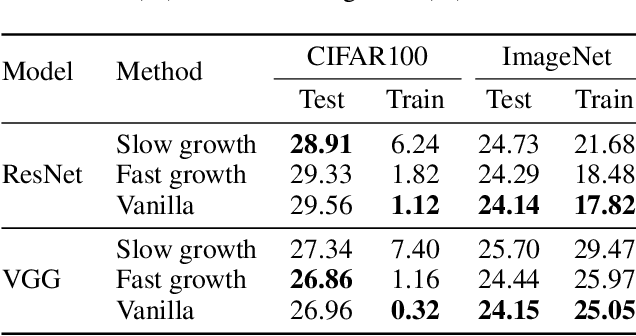
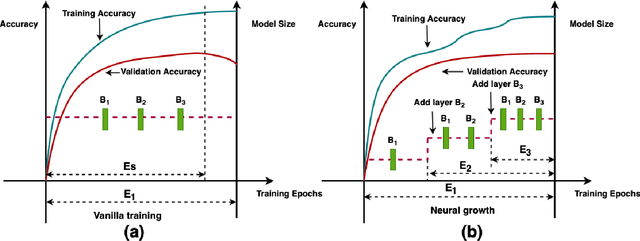
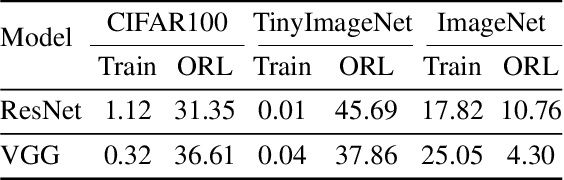
Neural growth is the process of growing a small neural network to a large network and has been utilized to accelerate the training of deep neural networks. One crucial aspect of neural growth is determining the optimal growth timing. However, few studies investigate this systematically. Our study reveals that neural growth inherently exhibits a regularization effect, whose intensity is influenced by the chosen policy for growth timing. While this regularization effect may mitigate the overfitting risk of the model, it may lead to a notable accuracy drop when the model underfits. Yet, current approaches have not addressed this issue due to their lack of consideration of the regularization effect from neural growth. Motivated by these findings, we propose an under/over fitting risk-aware growth timing policy, which automatically adjusts the growth timing informed by the level of potential under/overfitting risks to address both risks. Comprehensive experiments conducted using CIFAR-10/100 and ImageNet datasets show that the proposed policy achieves accuracy improvements of up to 1.3% in models prone to underfitting while achieving similar accuracies in models suffering from overfitting compared to the existing methods.