 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscriminative Sample-Guided and Parameter-Efficient Feature Space Adaptation for Cross-Domain Few-Shot Learning
Mar 08, 2024In this paper, we look at cross-domain few-shot classification which presents the challenging task of learning new classes in unseen domains with few labelled examples. Existing methods, though somewhat effective, encounter several limitations, which we address in this work through two significant improvements. First, to address overfitting associated with fine-tuning a large number of parameters on small datasets, we introduce a lightweight parameter-efficient adaptation strategy. This strategy employs a linear transformation of pre-trained features, significantly reducing the trainable parameter count. Second, we replace the traditional nearest centroid classifier with a variance-aware loss function, enhancing the model's sensitivity to the inter- and intra-class variances within the training set for improved clustering in feature space. Empirical evaluations on the Meta-Dataset benchmark showcase that our approach not only improves accuracy up to 7.7% and 5.3% on seen and unseen datasets respectively but also achieves this performance while being at least ~3x more parameter-efficient than existing methods, establishing a new state-of-the-art in cross-domain few-shot learning. Our code can be found at https://github.com/rashindrie/DIPA.
Undercover Deepfakes: Detecting Fake Segments in Videos
May 16, 2023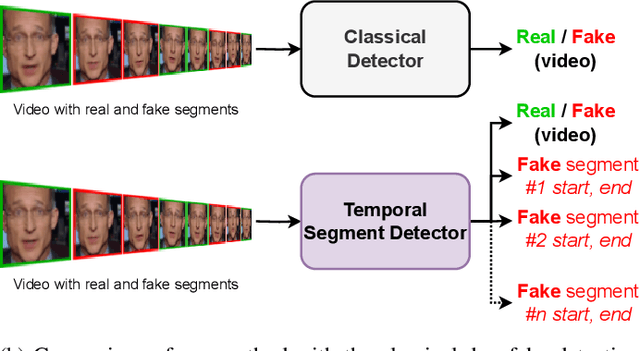
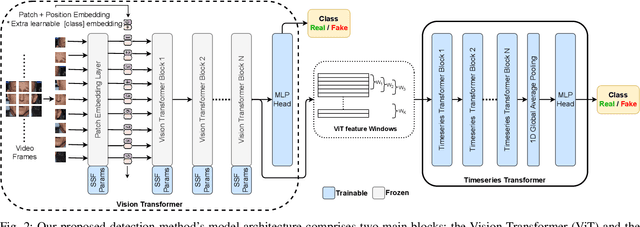

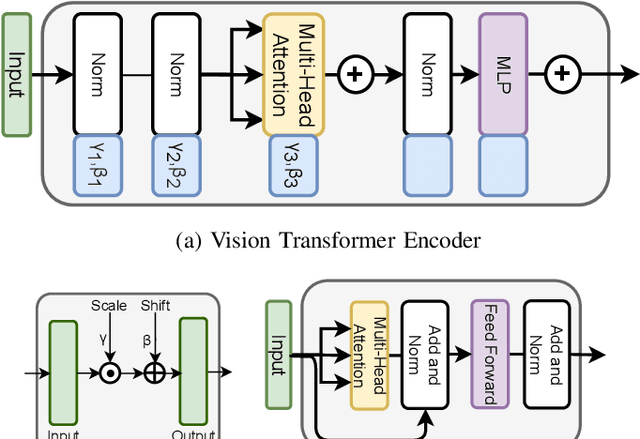
The recent renaissance in generative models, driven primarily by the advent of diffusion models and iterative improvement in GAN methods, has enabled many creative applications. However, each advancement is also accompanied by a rise in the potential for misuse. In the arena of deepfake generation this is a key societal issue. In particular, the ability to modify segments of videos using such generative techniques creates a new paradigm of deepfakes which are mostly real videos altered slightly to distort the truth. Current deepfake detection methods in the academic literature are not evaluated on this paradigm. In this paper, we present a deepfake detection method able to address this issue by performing both frame and video level deepfake prediction. To facilitate testing our method we create a new benchmark dataset where videos have both real and fake frame sequences. Our method utilizes the Vision Transformer, Scaling and Shifting pretraining and Timeseries Transformer to temporally segment videos to help facilitate the interpretation of possible deepfakes. Extensive experiments on a variety of deepfake generation methods show excellent results on temporal segmentation and classical video level predictions as well. In particular, the paradigm we introduce will form a powerful tool for the moderation of deepfakes, where human oversight can be better targeted to the parts of videos suspected of being deepfakes. All experiments can be reproduced at: https://github.com/sanjaysaha1311/temporal-deepfake-segmentation.