 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMany Dialects, Many Languages, One Cultural Lens: Evaluating Multilingual VLMs for Bengali Culture Understanding Across Historically Linked Languages and Regional Dialects
Mar 22, 2026Bangla culture is richly expressed through region, dialect, history, food, politics, media, and everyday visual life, yet it remains underrepresented in multimodal evaluation. To address this gap, we introduce BanglaVerse, a culturally grounded benchmark for evaluating multilingual vision-language models (VLMs) on Bengali culture across historically linked languages and regional dialects. Built from 1,152 manually curated images across nine domains, the benchmark supports visual question answering and captioning, and is expanded into four languages and five Bangla dialects, yielding ~32.3K artifacts. Our experiments show that evaluating only standard Bangla overestimates true model capability: performance drops under dialectal variation, especially for caption generation, while historically linked languages such as Hindi and Urdu retain some cultural meaning but remain weaker for structured reasoning. Across domains, the main bottleneck is missing cultural knowledge rather than visual grounding alone, with knowledge-intensive categories. These findings position BanglaVerse as a more realistic test bed for measuring culturally grounded multimodal understanding under linguistic variation.
Deepfake Synthesis vs. Detection: An Uneven Contest
Feb 08, 2026The rapid advancement of deepfake technology has significantly elevated the realism and accessibility of synthetic media. Emerging techniques, such as diffusion-based models and Neural Radiance Fields (NeRF), alongside enhancements in traditional Generative Adversarial Networks (GANs), have contributed to the sophisticated generation of deepfake videos. Concurrently, deepfake detection methods have seen notable progress, driven by innovations in Transformer architectures, contrastive learning, and other machine learning approaches. In this study, we conduct a comprehensive empirical analysis of state-of-the-art deepfake detection techniques, including human evaluation experiments against cutting-edge synthesis methods. Our findings highlight a concerning trend: many state-of-the-art detection models exhibit markedly poor performance when challenged with deepfakes produced by modern synthesis techniques, including poor performance by human participants against the best quality deepfakes. Through extensive experimentation, we provide evidence that underscores the urgent need for continued refinement of detection models to keep pace with the evolving capabilities of deepfake generation technologies. This research emphasizes the critical gap between current detection methodologies and the sophistication of new generation techniques, calling for intensified efforts in this crucial area of study.
Adaptive Tabu Dropout for Regularization of Deep Neural Network
Dec 31, 2024Dropout is an effective strategy for the regularization of deep neural networks. Applying tabu to the units that have been dropped in the recent epoch and retaining them for training ensures diversification in dropout. In this paper, we improve the Tabu Dropout mechanism for training deep neural networks in two ways. Firstly, we propose to use tabu tenure, or the number of epochs a particular unit will not be dropped. Different tabu tenures provide diversification to boost the training of deep neural networks based on the search landscape. Secondly, we propose an adaptive tabu algorithm that automatically selects the tabu tenure based on the training performances through epochs. On several standard benchmark datasets, the experimental results show that the adaptive tabu dropout and tabu tenure dropout diversify and perform significantly better compared to the standard dropout and basic tabu dropout mechanisms.
HyperQ-Opt: Q-learning for Hyperparameter Optimization
Dec 23, 2024Hyperparameter optimization (HPO) is critical for enhancing the performance of machine learning models, yet it often involves a computationally intensive search across a large parameter space. Traditional approaches such as Grid Search and Random Search suffer from inefficiency and limited scalability, while surrogate models like Sequential Model-based Bayesian Optimization (SMBO) rely heavily on heuristic predictions that can lead to suboptimal results. This paper presents a novel perspective on HPO by formulating it as a sequential decision-making problem and leveraging Q-learning, a reinforcement learning technique, to optimize hyperparameters. The study explores the works of H.S. Jomaa et al. and Qi et al., which model HPO as a Markov Decision Process (MDP) and utilize Q-learning to iteratively refine hyperparameter settings. The approaches are evaluated for their ability to find optimal or near-optimal configurations within a limited number of trials, demonstrating the potential of reinforcement learning to outperform conventional methods. Additionally, this paper identifies research gaps in existing formulations, including the limitations of discrete search spaces and reliance on heuristic policies, and suggests avenues for future exploration. By shifting the paradigm toward policy-based optimization, this work contributes to advancing HPO methods for scalable and efficient machine learning applications.
Deep Transfer Learning Based Peer Review Aggregation and Meta-review Generation for Scientific Articles
Oct 05, 2024



Peer review is the quality assessment of a manuscript by one or more peer experts. Papers are submitted by the authors to scientific venues, and these papers must be reviewed by peers or other authors. The meta-reviewers then gather the peer reviews, assess them, and create a meta-review and decision for each manuscript. As the number of papers submitted to these venues has grown in recent years, it becomes increasingly challenging for meta-reviewers to collect these peer evaluations on time while still maintaining the quality that is the primary goal of meta-review creation. In this paper, we address two peer review aggregation challenges a meta-reviewer faces: paper acceptance decision-making and meta-review generation. Firstly, we propose to automate the process of acceptance decision prediction by applying traditional machine learning algorithms. We use pre-trained word embedding techniques BERT to process the reviews written in natural language text. For the meta-review generation, we propose a transfer learning model based on the T5 model. Experimental results show that BERT is more effective than the other word embedding techniques, and the recommendation score is an important feature for the acceptance decision prediction. In addition, we figure out that fine-tuned T5 outperforms other inference models. Our proposed system takes peer reviews and other relevant features as input to produce a meta-review and make a judgment on whether or not the paper should be accepted. In addition, experimental results show that the acceptance decision prediction system of our task outperforms the existing models, and the meta-review generation task shows significantly improved scores compared to the existing models. For the statistical test, we utilize the Wilcoxon signed-rank test to assess whether there is a statistically significant improvement between paired observations.
AniFaceDiff: High-Fidelity Face Reenactment via Facial Parametric Conditioned Diffusion Models
Jun 19, 2024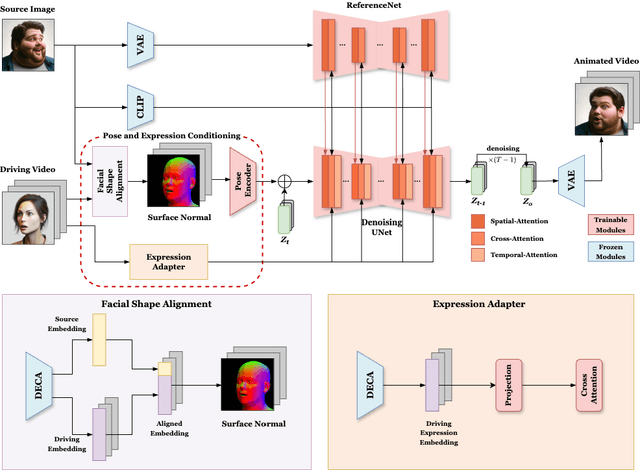
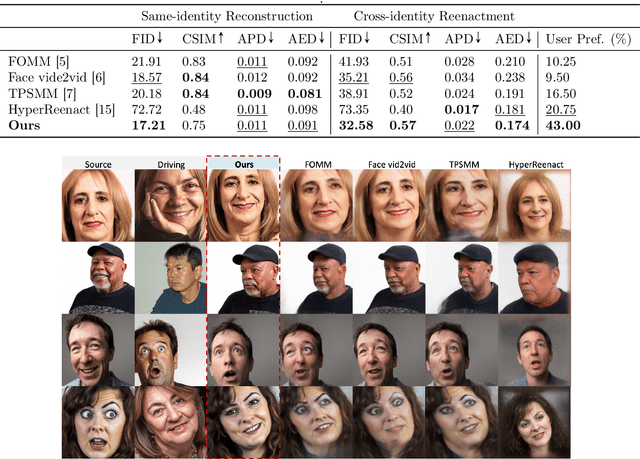
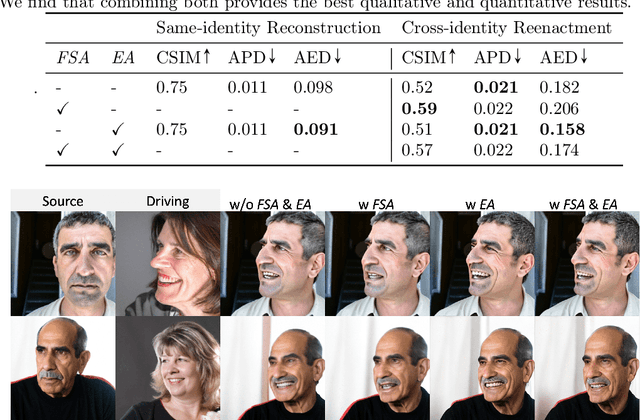

Face reenactment refers to the process of transferring the pose and facial expressions from a reference (driving) video onto a static facial (source) image while maintaining the original identity of the source image. Previous research in this domain has made significant progress by training controllable deep generative models to generate faces based on specific identity, pose and expression conditions. However, the mechanisms used in these methods to control pose and expression often inadvertently introduce identity information from the driving video, while also causing a loss of expression-related details. This paper proposes a new method based on Stable Diffusion, called AniFaceDiff, incorporating a new conditioning module for high-fidelity face reenactment. First, we propose an enhanced 2D facial snapshot conditioning approach by facial shape alignment to prevent the inclusion of identity information from the driving video. Then, we introduce an expression adapter conditioning mechanism to address the potential loss of expression-related information. Our approach effectively preserves pose and expression fidelity from the driving video while retaining the identity and fine details of the source image. Through experiments on the VoxCeleb dataset, we demonstrate that our method achieves state-of-the-art results in face reenactment, showcasing superior image quality, identity preservation, and expression accuracy, especially for cross-identity scenarios. Considering the ethical concerns surrounding potential misuse, we analyze the implications of our method, evaluate current state-of-the-art deepfake detectors, and identify their shortcomings to guide future research.
An Artificial Intelligence-based Framework to Achieve the Sustainable Development Goals in the Context of Bangladesh
Apr 23, 2023



Sustainable development is a framework for achieving human development goals. It provides natural systems' ability to deliver natural resources and ecosystem services. Sustainable development is crucial for the economy and society. Artificial intelligence (AI) has attracted increasing attention in recent years, with the potential to have a positive influence across many domains. AI is a commonly employed component in the quest for long-term sustainability. In this study, we explore the impact of AI on three pillars of sustainable development: society, environment, and economy, as well as numerous case studies from which we may deduce the impact of AI in a variety of areas, i.e., agriculture, classifying waste, smart water management, and Heating, Ventilation, and Air Conditioning (HVAC) systems. Furthermore, we present AI-based strategies for achieving Sustainable Development Goals (SDGs) which are effective for developing countries like Bangladesh. The framework that we propose may reduce the negative impact of AI and promote the proactiveness of this technology.