 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Artificial Intelligence-based Framework to Achieve the Sustainable Development Goals in the Context of Bangladesh
Apr 23, 2023



Sustainable development is a framework for achieving human development goals. It provides natural systems' ability to deliver natural resources and ecosystem services. Sustainable development is crucial for the economy and society. Artificial intelligence (AI) has attracted increasing attention in recent years, with the potential to have a positive influence across many domains. AI is a commonly employed component in the quest for long-term sustainability. In this study, we explore the impact of AI on three pillars of sustainable development: society, environment, and economy, as well as numerous case studies from which we may deduce the impact of AI in a variety of areas, i.e., agriculture, classifying waste, smart water management, and Heating, Ventilation, and Air Conditioning (HVAC) systems. Furthermore, we present AI-based strategies for achieving Sustainable Development Goals (SDGs) which are effective for developing countries like Bangladesh. The framework that we propose may reduce the negative impact of AI and promote the proactiveness of this technology.
A Dynamic Weighted Tabular Method for Convolutional Neural Networks
May 20, 2022
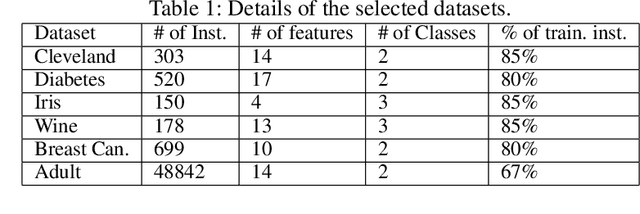
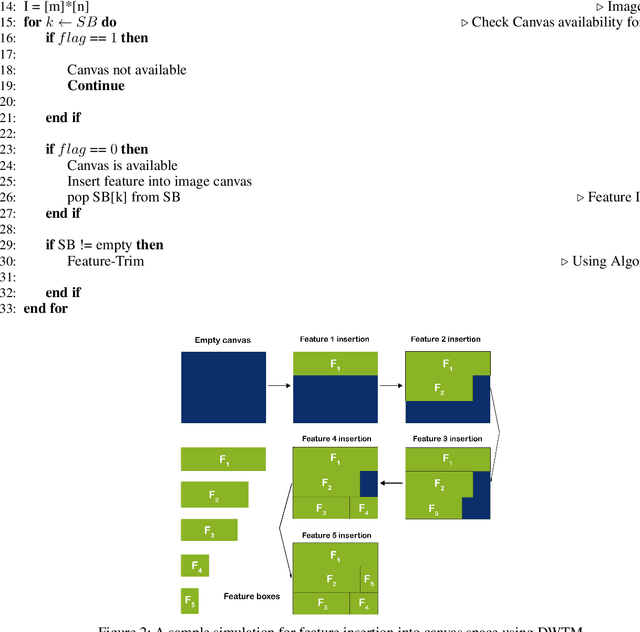
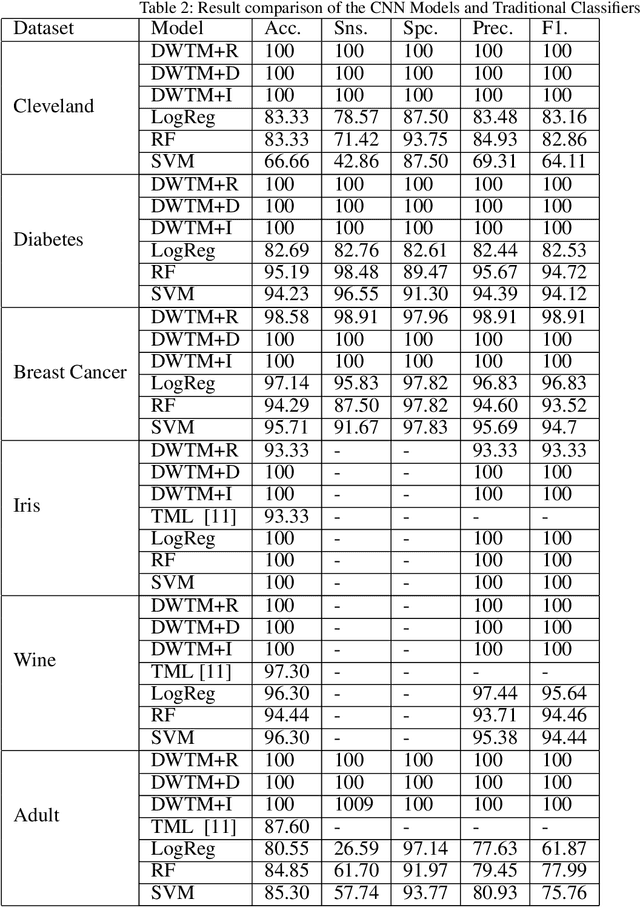
Traditional Machine Learning (ML) models like Support Vector Machine, Random Forest, and Logistic Regression are generally preferred for classification tasks on tabular datasets. Tabular data consists of rows and columns corresponding to instances and features, respectively. Past studies indicate that traditional classifiers often produce unsatisfactory results in complex tabular datasets. Hence, researchers attempt to use the powerful Convolutional Neural Networks (CNN) for tabular datasets. Recent studies propose several techniques like SuperTML, Conditional GAN (CTGAN), and Tabular Convolution (TAC) for applying Convolutional Neural Networks (CNN) on tabular data. These models outperform the traditional classifiers and substantially improve the performance on tabular data. This study introduces a novel technique, namely, Dynamic Weighted Tabular Method (DWTM), that uses feature weights dynamically based on statistical techniques to apply CNNs on tabular datasets. The method assigns weights dynamically to each feature based on their strength of associativity to the class labels. Each data point is converted into images and fed to a CNN model. The features are allocated image canvas space based on their weights. The DWTM is an improvement on the previously mentioned methods as it dynamically implements the entire experimental setting rather than using the static configuration provided in the previous methods. Furthermore, it uses the novel idea of using feature weights to create image canvas space. In this paper, the DWTM is applied to six benchmarked tabular datasets and it achieves outstanding performance (i.e., average accuracy = 95%) on all of them.
Predicting Users' Value Changes by the Friends' Influence from Social Media Usage
Sep 12, 2021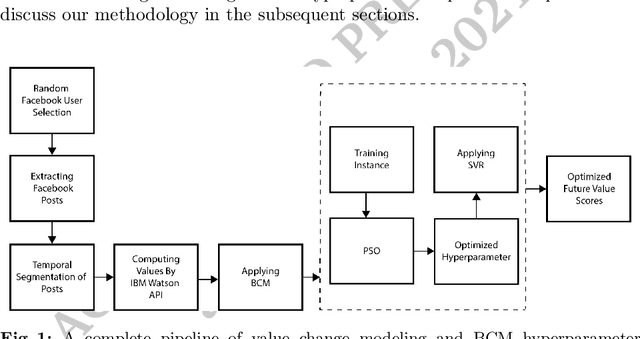
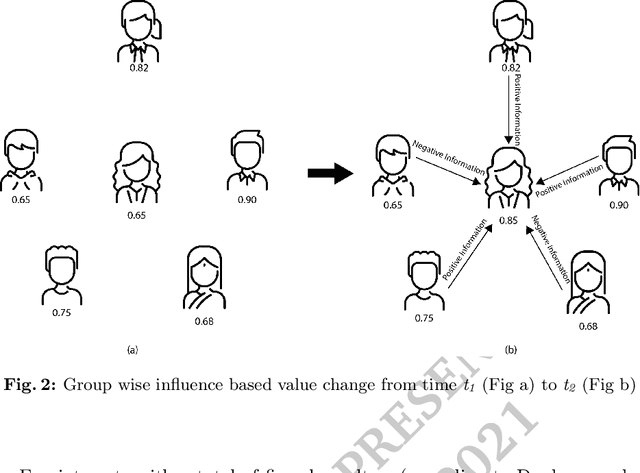
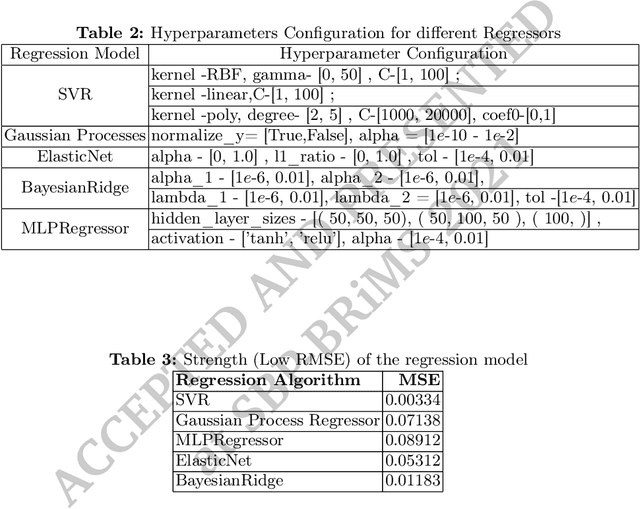
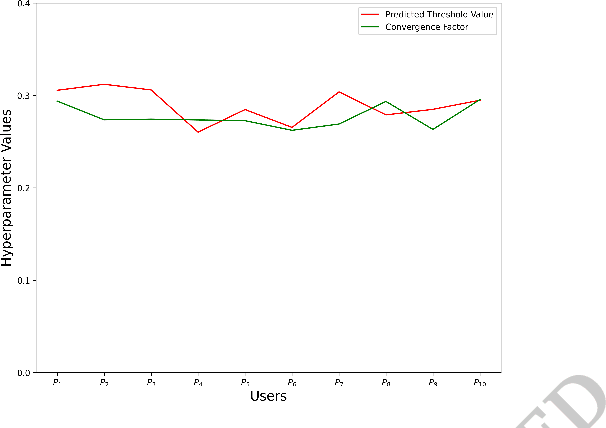
Basic human values represent a set of values such as security, independence, success, kindness, and pleasure, which we deem important to our lives. Each of us holds different values with different degrees of significance. Existing studies show that values of a person can be identified from their social network usage. However, the value priority of a person may change over time due to different factors such as life experiences, influence, social structure and technology. Existing studies do not conduct any analysis regarding the change of users' value from the social influence, i.e., group persuasion, form the social media usage. In our research, first, we predict users' value score by the influence of friends from their social media usage. We propose a Bounded Confidence Model (BCM) based value dynamics model from 275 different ego networks in Facebook that predicts how social influence may persuade a person to change their value over time. Then, to predict better, we use particle swarm optimization based hyperparameter tuning technique. We observe that these optimized hyperparameters produce accurate future value score. We also run our approach with different machine learning based methods and find support vector regression (SVR) outperforms other regressor models. By using SVR with the best hyperparameters of BCM model, we find the lowest Mean Squared Error (MSE) score 0.00347.
Text2Chart: A Multi-Staged Chart Generator from Natural Language Text
Apr 09, 2021

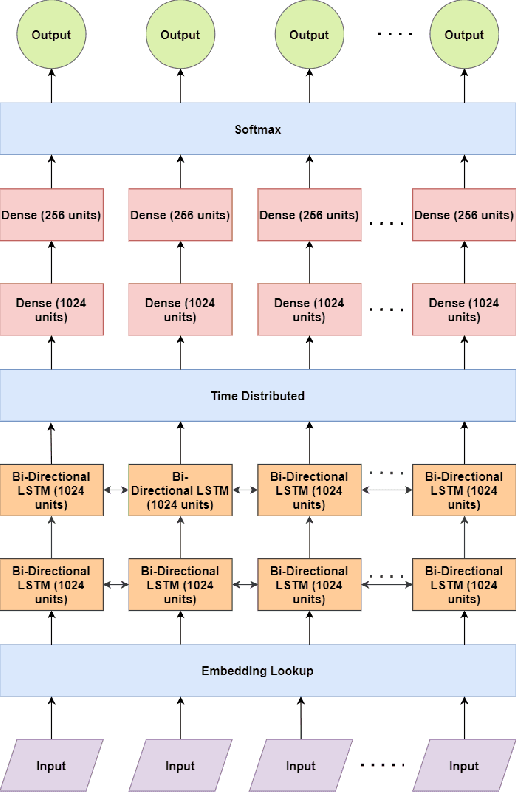
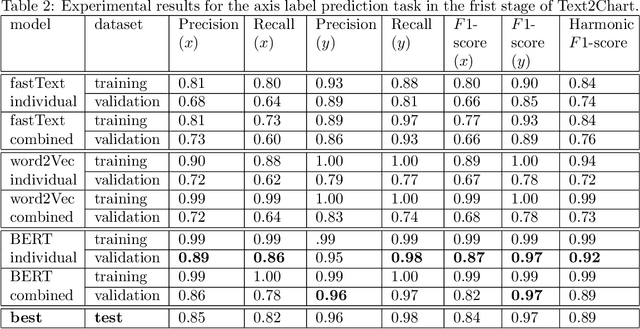
Generation of scientific visualization from analytical natural language text is a challenging task. In this paper, we propose Text2Chart, a multi-staged chart generator method. Text2Chart takes natural language text as input and produce visualization as two-dimensional charts. Text2Chart approaches the problem in three stages. Firstly, it identifies the axis elements of a chart from the given text known as x and y entities. Then it finds a mapping of x-entities with its corresponding y-entities. Next, it generates a chart type suitable for the given text: bar, line or pie. Combination of these three stages is capable of generating visualization from the given analytical text. We have also constructed a dataset for this problem. Experiments show that Text2Chart achieves best performances with BERT based encodings with LSTM models in the first stage to label x and y entities, Random Forest classifier for the mapping stage and fastText embedding with LSTM for the chart type prediction. In our experiments, all the stages show satisfactory results and effectiveness considering formation of charts from analytical text, achieving a commendable overall performance.