 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAiming to Minimize Alcohol-Impaired Road Fatalities: Utilizing Fairness-Aware and Domain Knowledge-Infused Artificial Intelligence
Nov 25, 2023Approximately 30% of all traffic fatalities in the United States are attributed to alcohol-impaired driving. This means that, despite stringent laws against this offense in every state, the frequency of drunk driving accidents is alarming, resulting in approximately one person being killed every 45 minutes. The process of charging individuals with Driving Under the Influence (DUI) is intricate and can sometimes be subjective, involving multiple stages such as observing the vehicle in motion, interacting with the driver, and conducting Standardized Field Sobriety Tests (SFSTs). Biases have been observed through racial profiling, leading to some groups and geographical areas facing fewer DUI tests, resulting in many actual DUI incidents going undetected, ultimately leading to a higher number of fatalities. To tackle this issue, our research introduces an Artificial Intelligence-based predictor that is both fairness-aware and incorporates domain knowledge to analyze DUI-related fatalities in different geographic locations. Through this model, we gain intriguing insights into the interplay between various demographic groups, including age, race, and income. By utilizing the provided information to allocate policing resources in a more equitable and efficient manner, there is potential to reduce DUI-related fatalities and have a significant impact on road safety.
A Survey on State-of-the-art Techniques for Knowledge Graphs Construction and Challenges ahead
Oct 15, 2021Global datasphere is increasing fast, and it is expected to reach 175 Zettabytes by 20251 . However, most of the content is unstructured and is not understandable by machines. Structuring this data into a knowledge graph enables multitudes of intelligent applications such as deep question answering, recommendation systems, semantic search, etc. The knowledge graph is an emerging technology that allows logical reasoning and uncovers new insights using content along with the context. Thereby, it provides necessary syntax and reasoning semantics that enable machines to solve complex healthcare, security, financial institutions, economics, and business problems. As an outcome, enterprises are putting their effort into constructing and maintaining knowledge graphs to support various downstream applications. Manual approaches are too expensive. Automated schemes can reduce the cost of building knowledge graphs up to 15-250 times. This paper critiques state-of-the-art automated techniques to produce knowledge graphs of near-human quality autonomously. Additionally, it highlights different research issues that need to be addressed to deliver high-quality knowledge graphs
Predicting Users' Value Changes by the Friends' Influence from Social Media Usage
Sep 12, 2021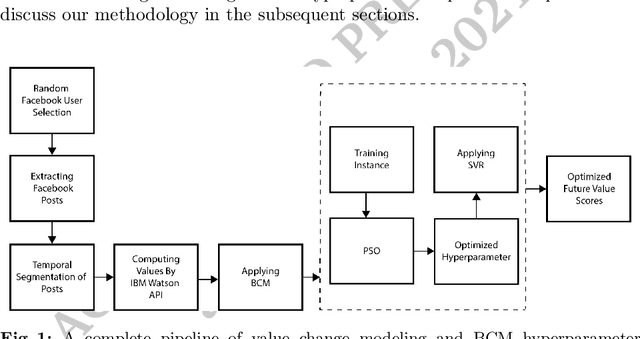
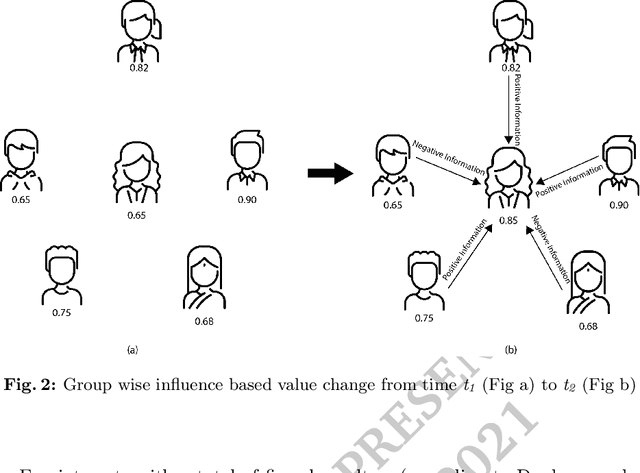
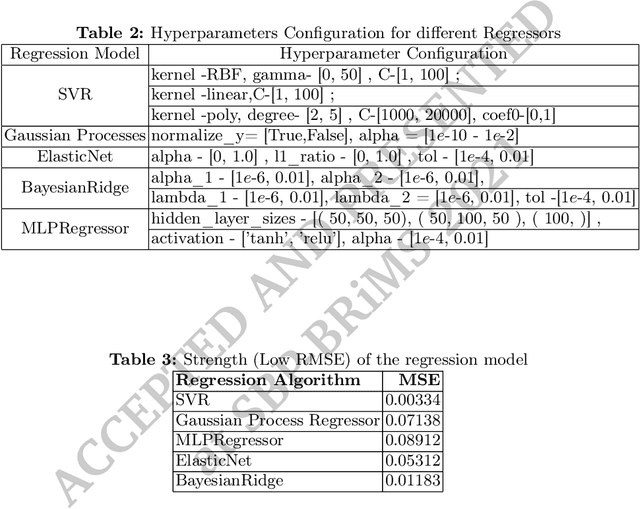
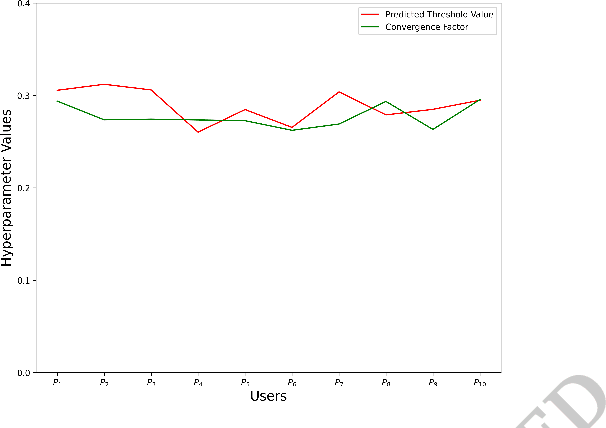
Basic human values represent a set of values such as security, independence, success, kindness, and pleasure, which we deem important to our lives. Each of us holds different values with different degrees of significance. Existing studies show that values of a person can be identified from their social network usage. However, the value priority of a person may change over time due to different factors such as life experiences, influence, social structure and technology. Existing studies do not conduct any analysis regarding the change of users' value from the social influence, i.e., group persuasion, form the social media usage. In our research, first, we predict users' value score by the influence of friends from their social media usage. We propose a Bounded Confidence Model (BCM) based value dynamics model from 275 different ego networks in Facebook that predicts how social influence may persuade a person to change their value over time. Then, to predict better, we use particle swarm optimization based hyperparameter tuning technique. We observe that these optimized hyperparameters produce accurate future value score. We also run our approach with different machine learning based methods and find support vector regression (SVR) outperforms other regressor models. By using SVR with the best hyperparameters of BCM model, we find the lowest Mean Squared Error (MSE) score 0.00347.
RAIDER: Reinforcement-aided Spear Phishing Detector
May 17, 2021



Spear Phishing is a harmful cyber-attack facing business and individuals worldwide. Considerable research has been conducted recently into the use of Machine Learning (ML) techniques to detect spear-phishing emails. ML-based solutions may suffer from zero-day attacks; unseen attacks unaccounted for in the training data. As new attacks emerge, classifiers trained on older data are unable to detect these new varieties of attacks resulting in increasingly inaccurate predictions. Spear Phishing detection also faces scalability challenges due to the growth of the required features which is proportional to the number of the senders within a receiver mailbox. This differs from traditional phishing attacks which typically perform only a binary classification between phishing and benign emails. Therefore, we devise a possible solution to these problems, named RAIDER: Reinforcement AIded Spear Phishing DEtectoR. A reinforcement-learning based feature evaluation system that can automatically find the optimum features for detecting different types of attacks. By leveraging a reward and penalty system, RAIDER allows for autonomous features selection. RAIDER also keeps the number of features to a minimum by selecting only the significant features to represent phishing emails and detect spear-phishing attacks. After extensive evaluation of RAIDER over 11,000 emails and across 3 attack scenarios, our results suggest that using reinforcement learning to automatically identify the significant features could reduce the dimensions of the required features by 55% in comparison to existing ML-based systems. It also improves the accuracy of detecting spoofing attacks by 4% from 90% to 94%. In addition, RAIDER demonstrates reasonable detection accuracy even against a sophisticated attack named Known Sender in which spear-phishing emails greatly resemble those of the impersonated sender.
Explainable Artificial Intelligence Approaches: A Survey
Jan 23, 2021
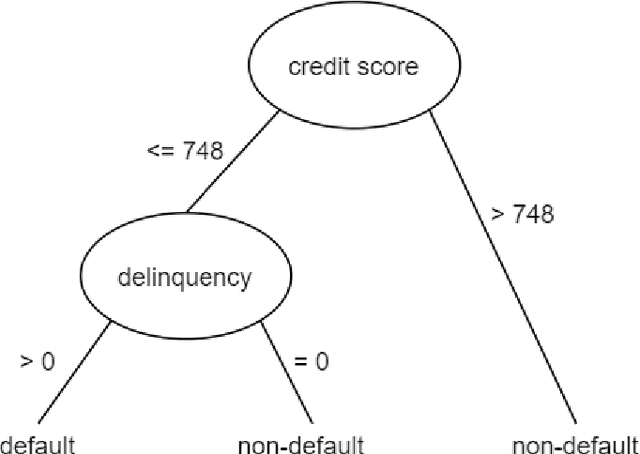

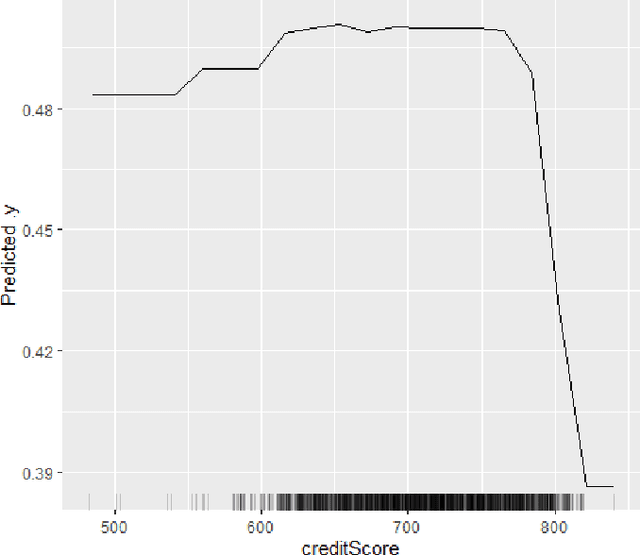
The lack of explainability of a decision from an Artificial Intelligence (AI) based "black box" system/model, despite its superiority in many real-world applications, is a key stumbling block for adopting AI in many high stakes applications of different domain or industry. While many popular Explainable Artificial Intelligence (XAI) methods or approaches are available to facilitate a human-friendly explanation of the decision, each has its own merits and demerits, with a plethora of open challenges. We demonstrate popular XAI methods with a mutual case study/task (i.e., credit default prediction), analyze for competitive advantages from multiple perspectives (e.g., local, global), provide meaningful insight on quantifying explainability, and recommend paths towards responsible or human-centered AI using XAI as a medium. Practitioners can use this work as a catalog to understand, compare, and correlate competitive advantages of popular XAI methods. In addition, this survey elicits future research directions towards responsible or human-centric AI systems, which is crucial to adopt AI in high stakes applications.