 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomaly Detection in Dynamic Graphs: A Comprehensive Survey
May 31, 2024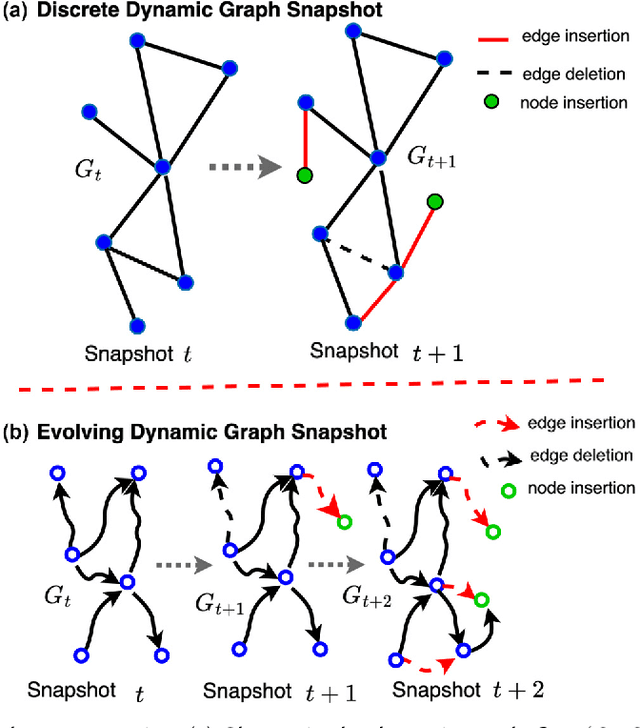
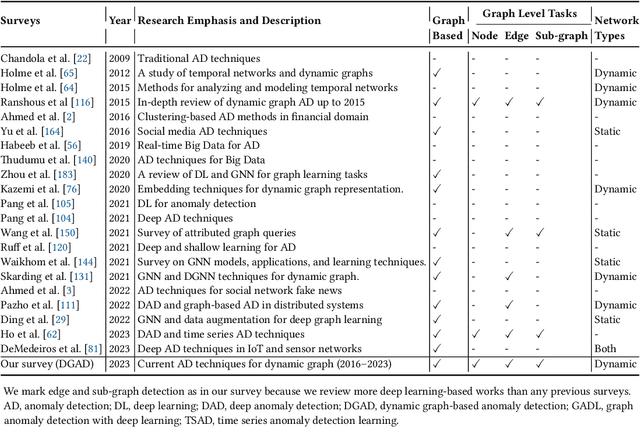
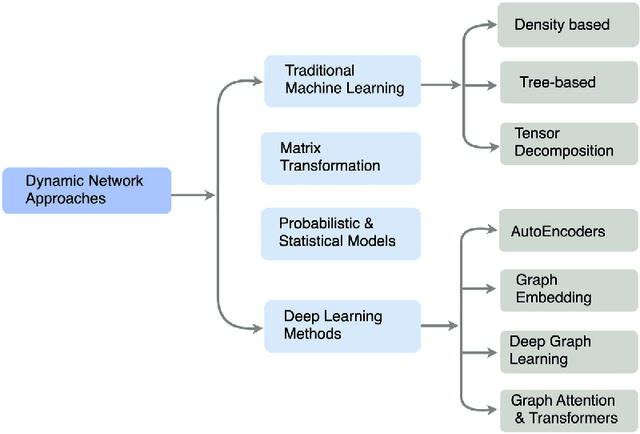

This survey paper presents a comprehensive and conceptual overview of anomaly detection using dynamic graphs. We focus on existing graph-based anomaly detection (AD) techniques and their applications to dynamic networks. The contributions of this survey paper include the following: i) a comparative study of existing surveys on anomaly detection; ii) a Dynamic Graph-based Anomaly Detection (DGAD) review framework in which approaches for detecting anomalies in dynamic graphs are grouped based on traditional machine-learning models, matrix transformations, probabilistic approaches, and deep-learning approaches; iii) a discussion of graphically representing both discrete and dynamic networks; and iv) a discussion of the advantages of graph-based techniques for capturing the relational structure and complex interactions in dynamic graph data. Finally, this work identifies the potential challenges and future directions for detecting anomalies in dynamic networks. This DGAD survey approach aims to provide a valuable resource for researchers and practitioners by summarizing the strengths and limitations of each approach, highlighting current research trends, and identifying open challenges. In doing so, it can guide future research efforts and promote advancements in anomaly detection in dynamic graphs. Keywords: Graphs, Anomaly Detection, dynamic networks,Graph Neural Networks (GNN), Node anomaly, Graph mining.
Anomaly Detection in Graph Structured Data: A Survey
May 10, 2024Real-world graphs are complex to process for performing effective analysis, such as anomaly detection. However, recently, there have been several research efforts addressing the issues surrounding graph-based anomaly detection. In this paper, we discuss a comprehensive overview of anomaly detection techniques on graph data. We also discuss the various application domains which use those anomaly detection techniques. We present a new taxonomy that categorizes the different state-of-the-art anomaly detection methods based on assumptions and techniques. Within each category, we discuss the fundamental research ideas that have been done to improve anomaly detection. We further discuss the advantages and disadvantages of current anomaly detection techniques. Finally, we present potential future research directions in anomaly detection on graph-structured data.
Explainable Artificial Intelligence Approaches: A Survey
Jan 23, 2021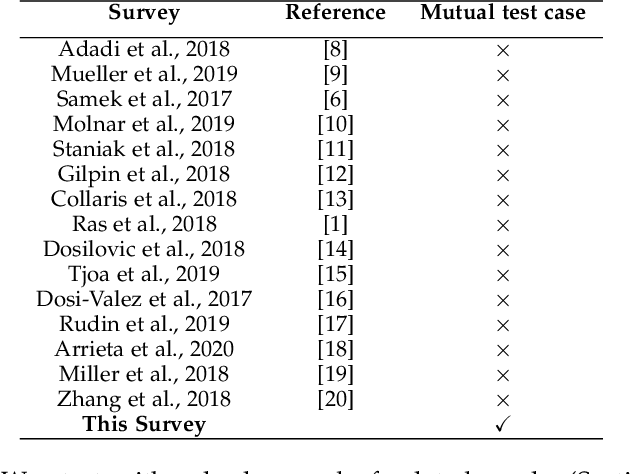
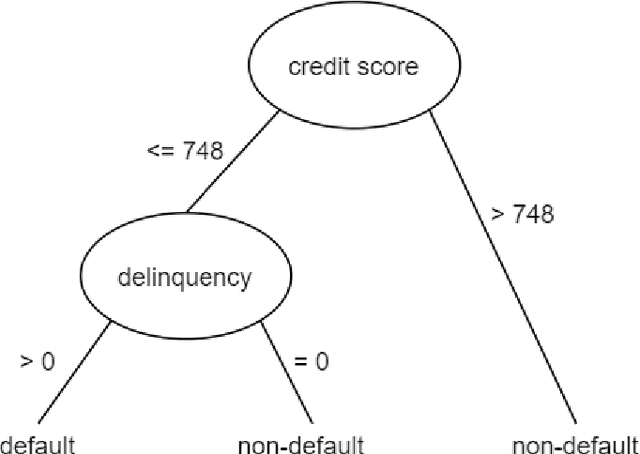

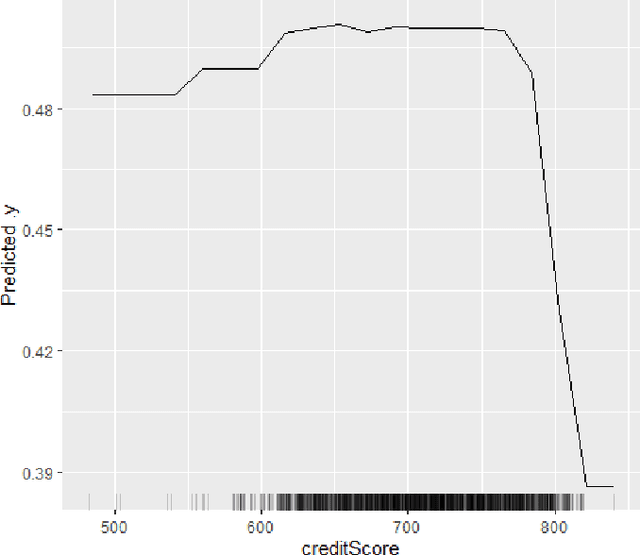
The lack of explainability of a decision from an Artificial Intelligence (AI) based "black box" system/model, despite its superiority in many real-world applications, is a key stumbling block for adopting AI in many high stakes applications of different domain or industry. While many popular Explainable Artificial Intelligence (XAI) methods or approaches are available to facilitate a human-friendly explanation of the decision, each has its own merits and demerits, with a plethora of open challenges. We demonstrate popular XAI methods with a mutual case study/task (i.e., credit default prediction), analyze for competitive advantages from multiple perspectives (e.g., local, global), provide meaningful insight on quantifying explainability, and recommend paths towards responsible or human-centered AI using XAI as a medium. Practitioners can use this work as a catalog to understand, compare, and correlate competitive advantages of popular XAI methods. In addition, this survey elicits future research directions towards responsible or human-centric AI systems, which is crucial to adopt AI in high stakes applications.
Towards Quantification of Explainability in Explainable Artificial Intelligence Methods
Nov 22, 2019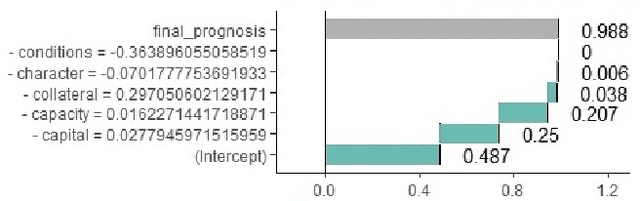

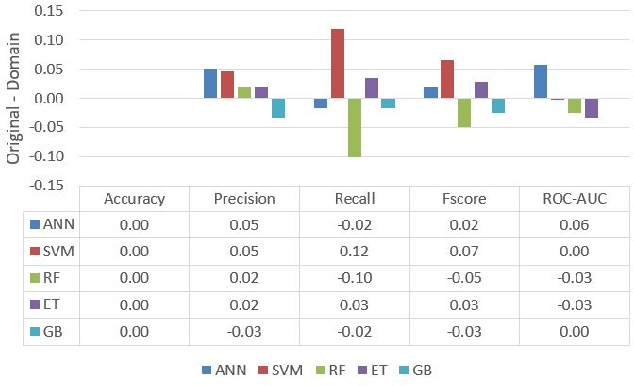
Artificial Intelligence (AI) has become an integral part of domains such as security, finance, healthcare, medicine, and criminal justice. Explaining the decisions of AI systems in human terms is a key challenge--due to the high complexity of the model, as well as the potential implications on human interests, rights, and lives . While Explainable AI is an emerging field of research, there is no consensus on the definition, quantification, and formalization of explainability. In fact, the quantification of explainability is an open challenge. In our previous work, we incorporated domain knowledge for better explainability, however, we were unable to quantify the extent of explainability. In this work, we (1) briefly analyze the definitions of explainability from the perspective of different disciplines (e.g., psychology, social science), properties of explanation, explanation methods, and human-friendly explanations; and (2) propose and formulate an approach to quantify the extent of explainability. Our experimental result suggests a reasonable and model-agnostic way to quantify explainability
Investigating bankruptcy prediction models in the presence of extreme class imbalance and multiple stages of economy
Nov 22, 2019
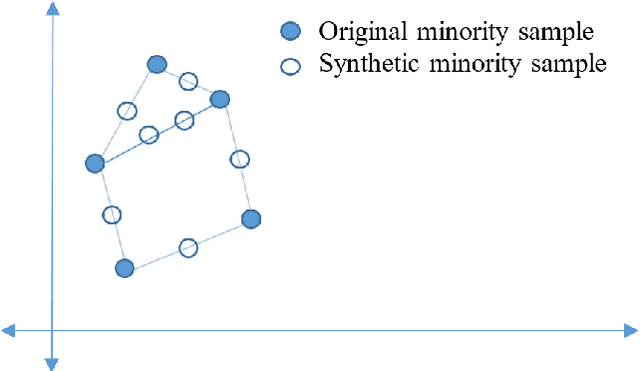
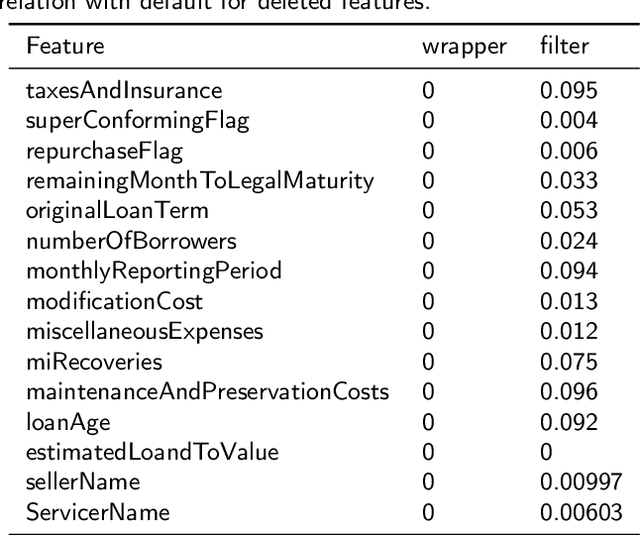
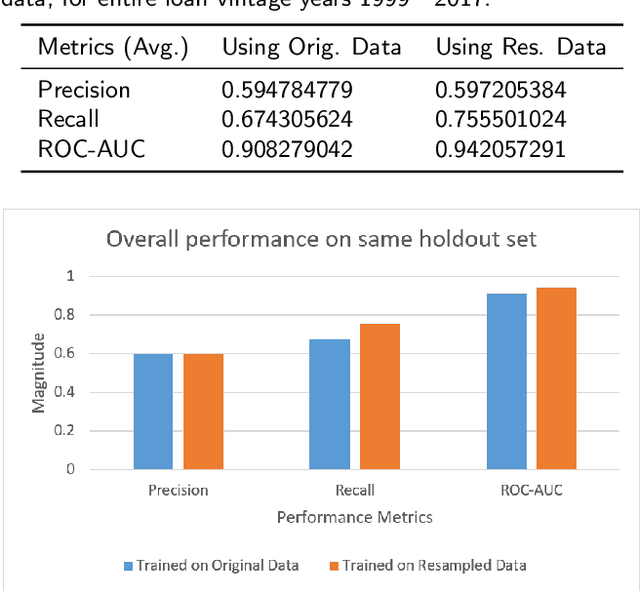
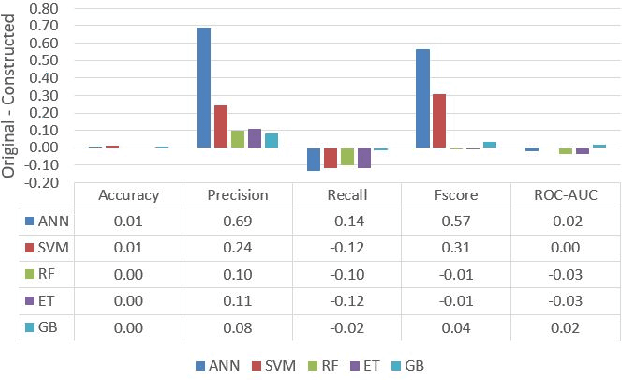
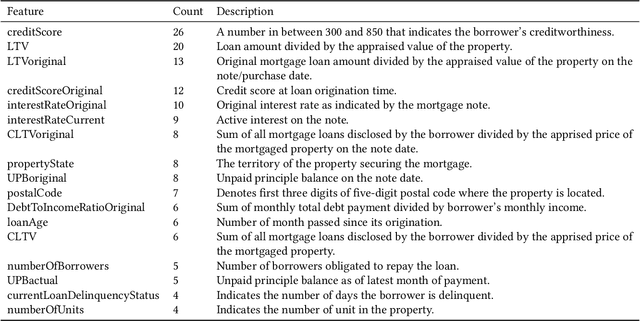
In the area of credit risk analytics, current Bankruptcy Prediction Models (BPMs) struggle with (a) the availability of comprehensive and real-world data sets and (b) the presence of extreme class imbalance in the data (i.e., very few samples for the minority class) that degrades the performance of the prediction model. Moreover, little research has compared the relative performance of well-known BPM's on public datasets addressing the class imbalance problem. In this work, we apply eight classes of well-known BPMs, as suggested by a review of decades of literature, on a new public dataset named Freddie Mac Single-Family Loan-Level Dataset with resampling (i.e., adding synthetic minority samples) of the minority class to tackle class imbalance. Additionally, we apply some recent AI techniques (e.g., tree-based ensemble techniques) that demonstrate potentially better results on models trained with resampled data. In addition, from the analysis of 19 years (1999-2017) of data, we discover that models behave differently when presented with sudden changes in the economy (e.g., a global financial crisis) resulting in abrupt fluctuations in the national default rate. In summary, this study should aid practitioners/researchers in determining the appropriate model with respect to data that contains a class imbalance and various economic stages.
Domain Knowledge Aided Explainable Artificial Intelligence for Intrusion Detection and Response
Nov 22, 2019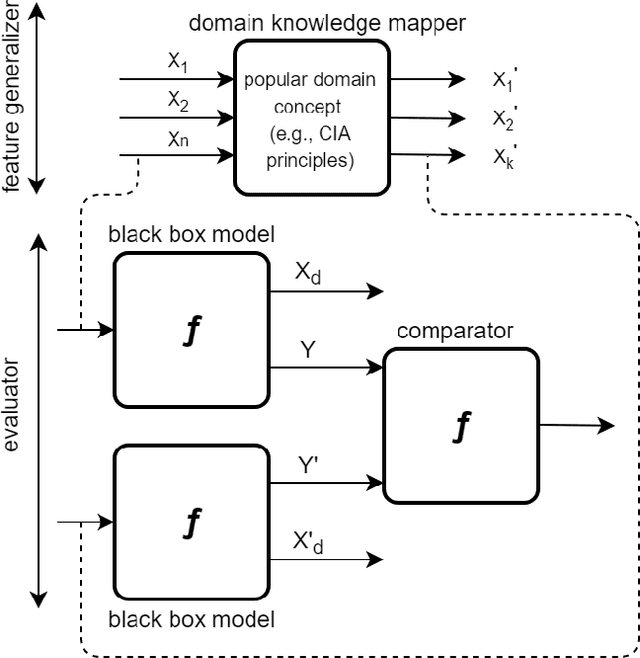


Artificial Intelligence (AI) has become an integral part of modern-day security solutions for its capability of learning very complex functions and handling "Big Data". However, the lack of explainability and interpretability of successful AI models is a key stumbling block when trust in a model's prediction is critical. This leads to human intervention, which in turn results in a delayed response or decision. While there have been major advancements in the speed and performance of AI-based intrusion detection systems, the response is still at human speed when it comes to explaining and interpreting a specific prediction or decision. In this work, we infuse popular domain knowledge (i.e., CIA principles) in our model for better explainability and validate the approach on a network intrusion detection test case. Our experimental results suggest that the infusion of domain knowledge provides better explainability as well as a faster decision or response. In addition, the infused domain knowledge generalizes the model to work well with unknown attacks, as well as open the path to adapt to a large stream of network traffic from numerous IoT devices.
Infusing domain knowledge in AI-based "black box" models for better explainability with application in bankruptcy prediction
May 30, 2019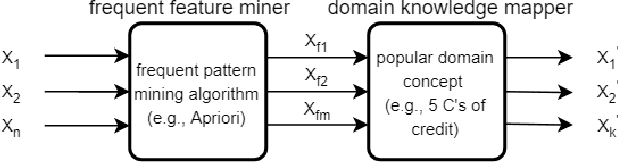
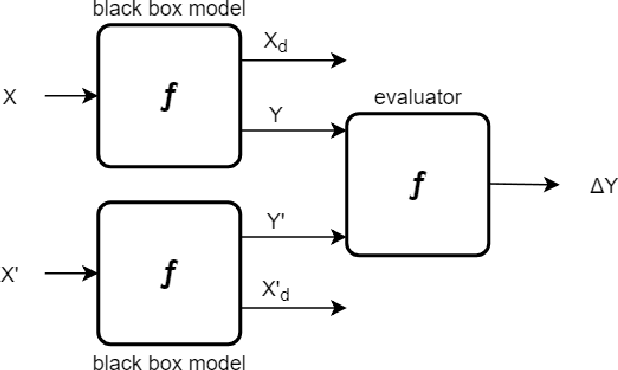

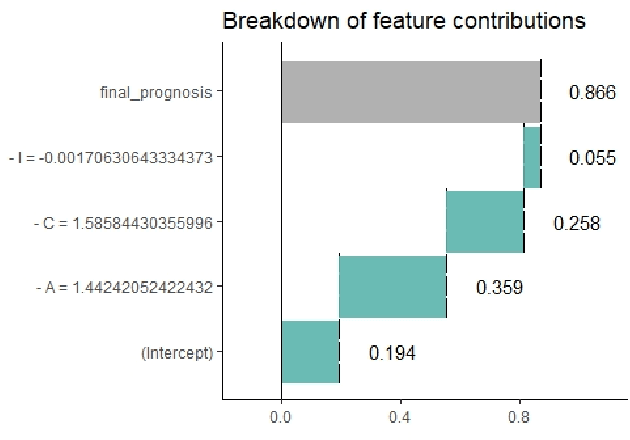
Although "black box" models such as Artificial Neural Networks, Support Vector Machines, and Ensemble Approaches continue to show superior performance in many disciplines, their adoption in the sensitive disciplines (e.g., finance, healthcare) is questionable due to the lack of interpretability and explainability of the model. In fact, future adoption of "black box" models is difficult because of the recent rule of "right of explanation" by the European Union where a user can ask for an explanation behind an algorithmic decision, and the newly proposed bill by the US government, the "Algorithmic Accountability Act", which would require companies to assess their machine learning systems for bias and discrimination and take corrective measures. Top Bankruptcy Prediction Models are A.I.-based and are in need of better explainability -the extent to which the internal working mechanisms of an AI system can be explained in human terms. Although explainable artificial intelligence is an emerging field of research, infusing domain knowledge for better explainability might be a possible solution. In this work, we demonstrate a way to collect and infuse domain knowledge into a "black box" model for bankruptcy prediction. Our understanding from the experiments reveals that infused domain knowledge makes the output from the black box model more interpretable and explainable.
Mining Illegal Insider Trading of Stocks: A Proactive Approach
Aug 21, 2018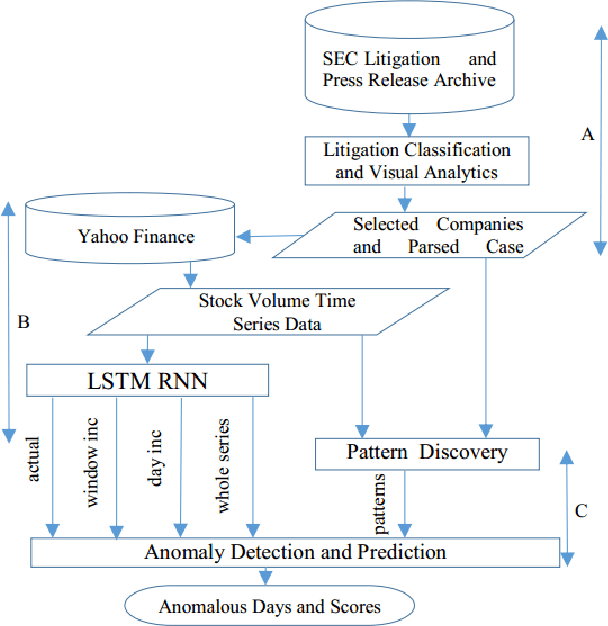
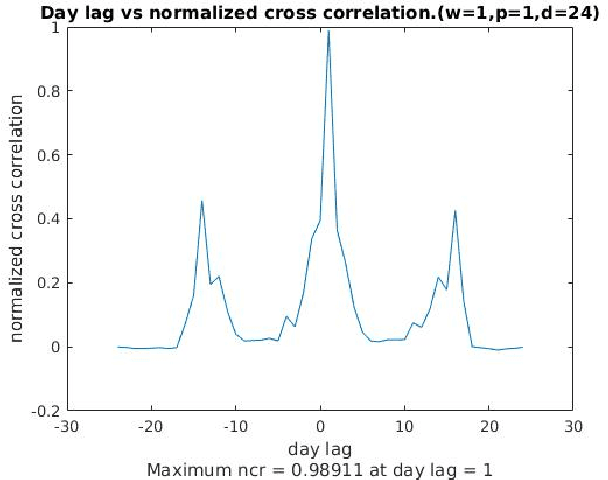
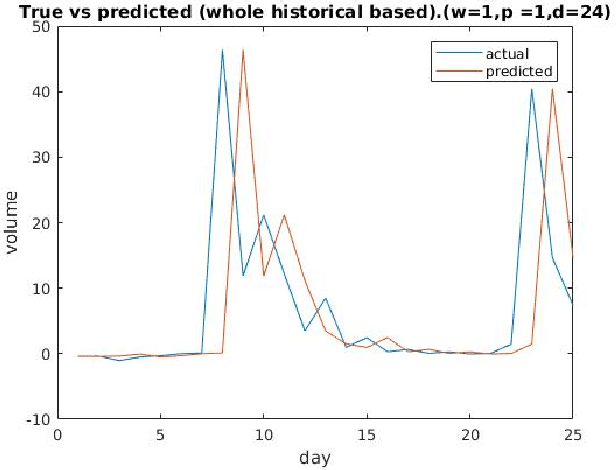
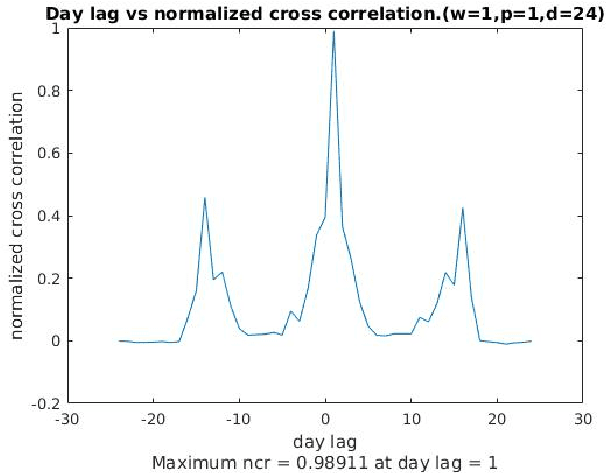
Illegal insider trading of stocks is based on releasing non-public information (e.g., new product launch, quarterly financial report, acquisition or merger plan) before the information is made public. Detecting illegal insider trading is difficult due to the complex, nonlinear, and non-stationary nature of the stock market. In this work, we present an approach that detects and predicts illegal insider trading proactively from large heterogeneous sources of structured and unstructured data using a deep-learning based approach combined with discrete signal processing on the time series data. In addition, we use a tree-based approach that visualizes events and actions to aid analysts in their understanding of large amounts of unstructured data. Using existing data, we have discovered that our approach has a good success rate in detecting illegal insider trading patterns.
Credit Default Mining Using Combined Machine Learning and Heuristic Approach
Jul 02, 2018
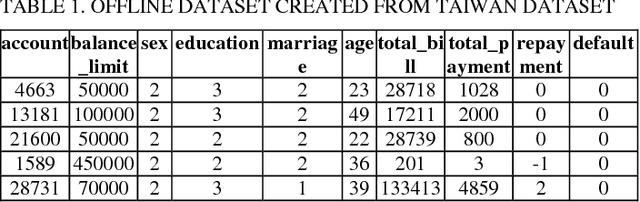
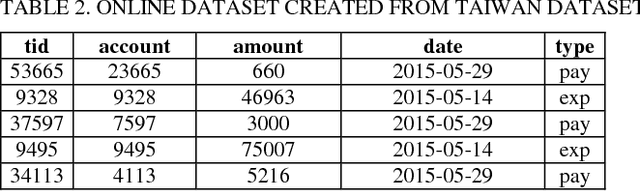
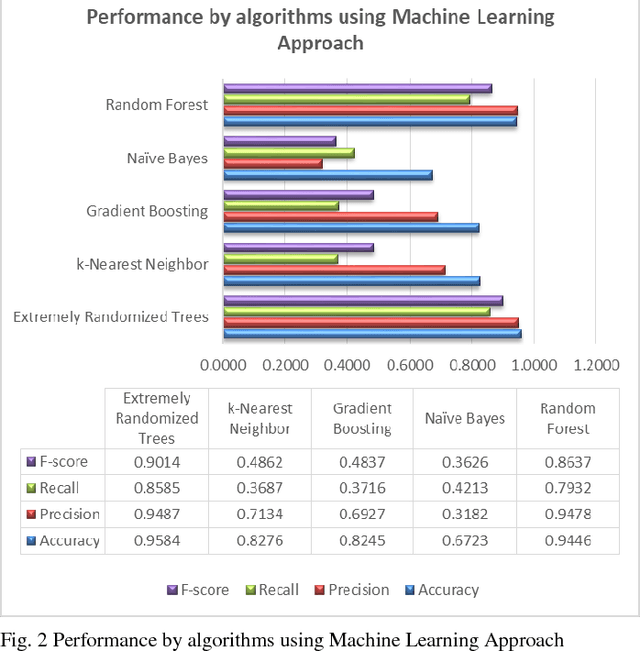
Predicting potential credit default accounts in advance is challenging. Traditional statistical techniques typically cannot handle large amounts of data and the dynamic nature of fraud and humans. To tackle this problem, recent research has focused on artificial and computational intelligence based approaches. In this work, we present and validate a heuristic approach to mine potential default accounts in advance where a risk probability is precomputed from all previous data and the risk probability for recent transactions are computed as soon they happen. Beside our heuristic approach, we also apply a recently proposed machine learning approach that has not been applied previously on our targeted dataset [15]. As a result, we find that these applied approaches outperform existing state-of-the-art approaches.