 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Quantification of Explainability in Explainable Artificial Intelligence Methods
Nov 22, 2019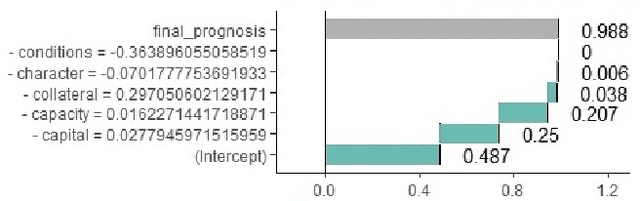

Artificial Intelligence (AI) has become an integral part of domains such as security, finance, healthcare, medicine, and criminal justice. Explaining the decisions of AI systems in human terms is a key challenge--due to the high complexity of the model, as well as the potential implications on human interests, rights, and lives . While Explainable AI is an emerging field of research, there is no consensus on the definition, quantification, and formalization of explainability. In fact, the quantification of explainability is an open challenge. In our previous work, we incorporated domain knowledge for better explainability, however, we were unable to quantify the extent of explainability. In this work, we (1) briefly analyze the definitions of explainability from the perspective of different disciplines (e.g., psychology, social science), properties of explanation, explanation methods, and human-friendly explanations; and (2) propose and formulate an approach to quantify the extent of explainability. Our experimental result suggests a reasonable and model-agnostic way to quantify explainability
Investigating bankruptcy prediction models in the presence of extreme class imbalance and multiple stages of economy
Nov 22, 2019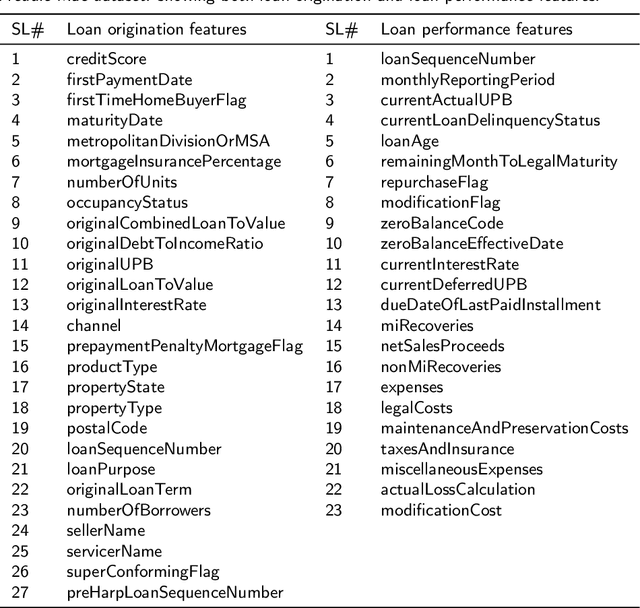
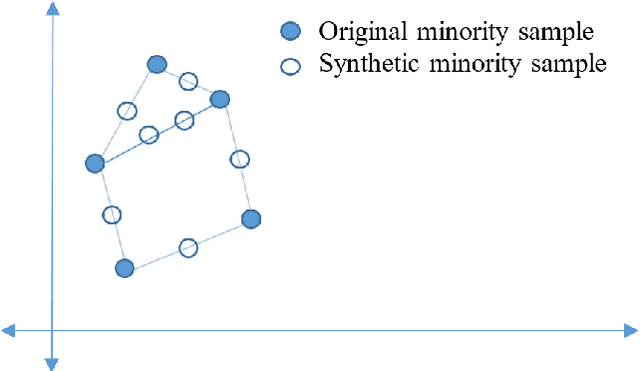
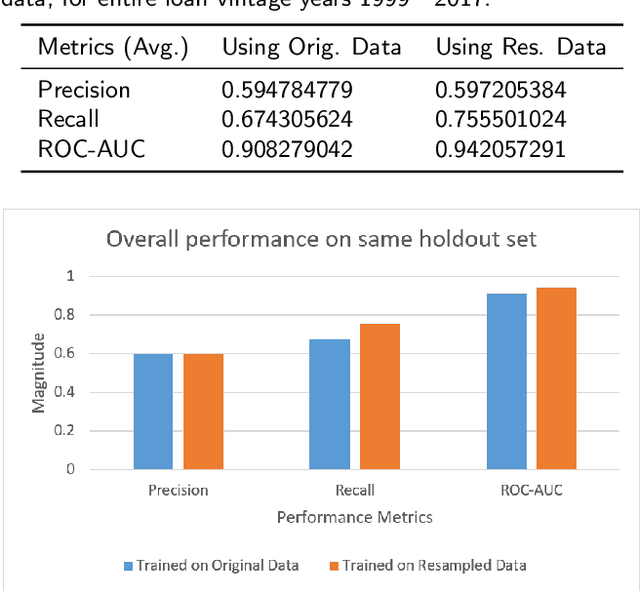
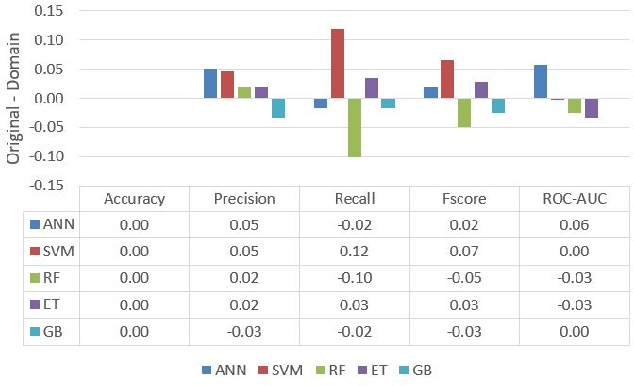
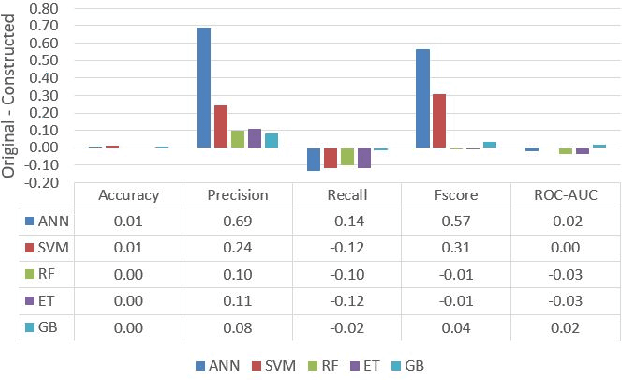
In the area of credit risk analytics, current Bankruptcy Prediction Models (BPMs) struggle with (a) the availability of comprehensive and real-world data sets and (b) the presence of extreme class imbalance in the data (i.e., very few samples for the minority class) that degrades the performance of the prediction model. Moreover, little research has compared the relative performance of well-known BPM's on public datasets addressing the class imbalance problem. In this work, we apply eight classes of well-known BPMs, as suggested by a review of decades of literature, on a new public dataset named Freddie Mac Single-Family Loan-Level Dataset with resampling (i.e., adding synthetic minority samples) of the minority class to tackle class imbalance. Additionally, we apply some recent AI techniques (e.g., tree-based ensemble techniques) that demonstrate potentially better results on models trained with resampled data. In addition, from the analysis of 19 years (1999-2017) of data, we discover that models behave differently when presented with sudden changes in the economy (e.g., a global financial crisis) resulting in abrupt fluctuations in the national default rate. In summary, this study should aid practitioners/researchers in determining the appropriate model with respect to data that contains a class imbalance and various economic stages.
Domain Knowledge Aided Explainable Artificial Intelligence for Intrusion Detection and Response
Nov 22, 2019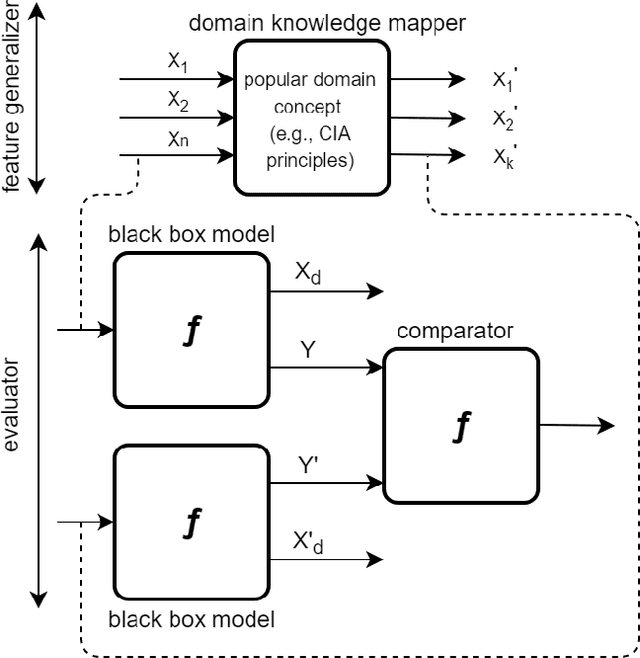


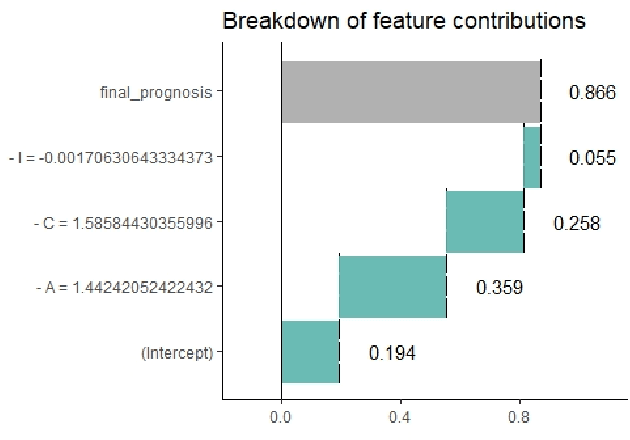
Artificial Intelligence (AI) has become an integral part of modern-day security solutions for its capability of learning very complex functions and handling "Big Data". However, the lack of explainability and interpretability of successful AI models is a key stumbling block when trust in a model's prediction is critical. This leads to human intervention, which in turn results in a delayed response or decision. While there have been major advancements in the speed and performance of AI-based intrusion detection systems, the response is still at human speed when it comes to explaining and interpreting a specific prediction or decision. In this work, we infuse popular domain knowledge (i.e., CIA principles) in our model for better explainability and validate the approach on a network intrusion detection test case. Our experimental results suggest that the infusion of domain knowledge provides better explainability as well as a faster decision or response. In addition, the infused domain knowledge generalizes the model to work well with unknown attacks, as well as open the path to adapt to a large stream of network traffic from numerous IoT devices.