 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrecise Feature Selection and Case Study of Intrusion Detection in an Industrial Control System Environment
Jul 01, 2021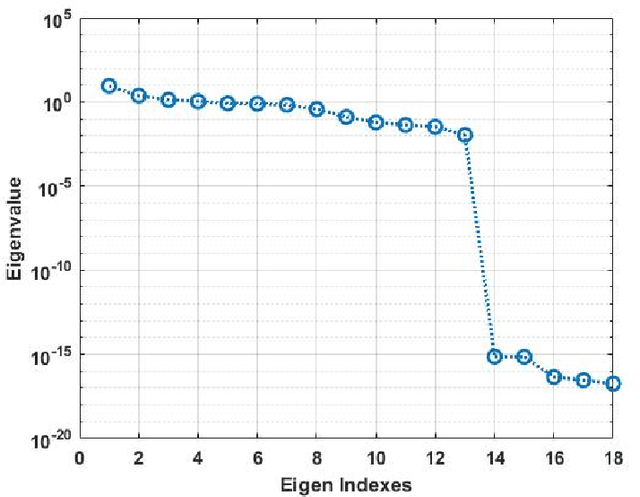
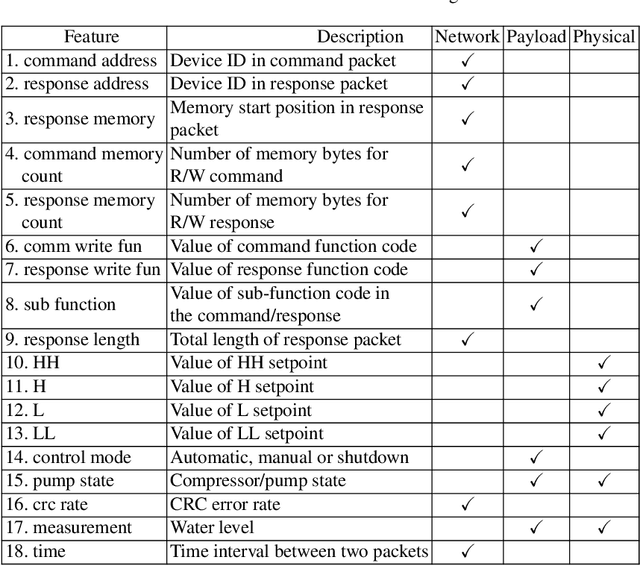
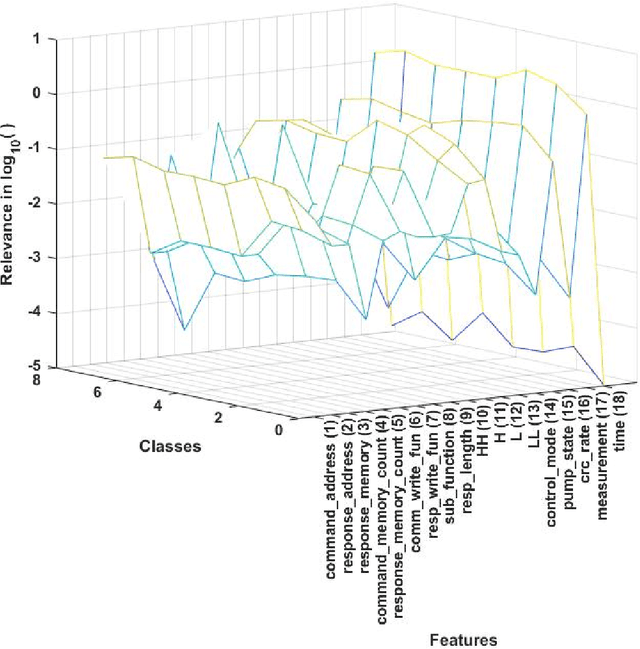
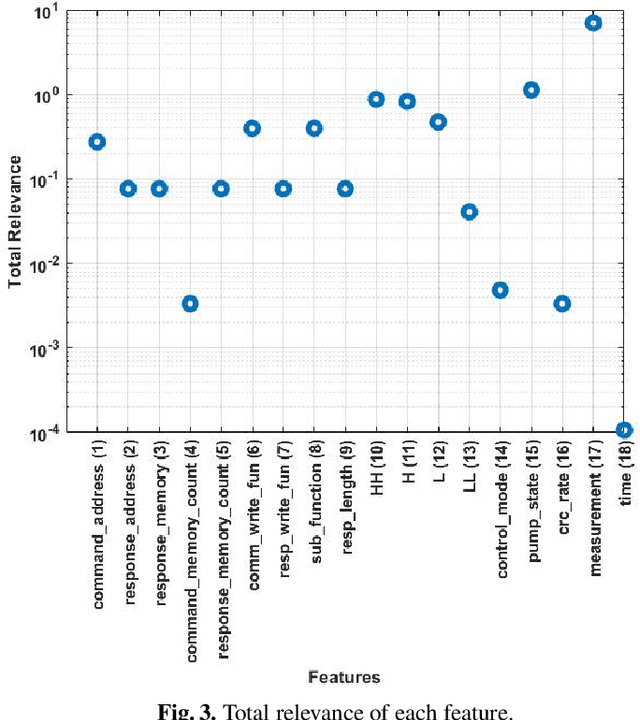
This paper presents analytical techniques to improve redundancy and relevance assessment for precise selection of features in practical multi-class raw datasets. We propose a matrix-rank based $k$-medoids algorithm that guarantees to output all independent medoids. The new algorithm uses matrix rank as a robust indicator, while a traditional $k$-medoids algorithm depends on specific datasets and how the distance between any of two features is defined. Another advantage is that the total number of operations in the nested loops is bounded, different from some $k$-medoids algorithms that involve random search. Sparse regression is an efficient tool for feature relevance analysis, but its outcome can depend on what labeled datasets are employed. A compensation method is introduced in this paper to handle the unequality of class-occurrence in a practical raw dataset. To assess the proposed techniques quantitatively, an existing Industrial Control System (ICS) dataset is used to perform intrusion detection. The numerical results generated from this case study validate the effectiveness and necessity of the proposed analytical framework.
Privacy Protection of Grid Users Data with Blockchain and Adversarial Machine Learning
Jan 15, 2021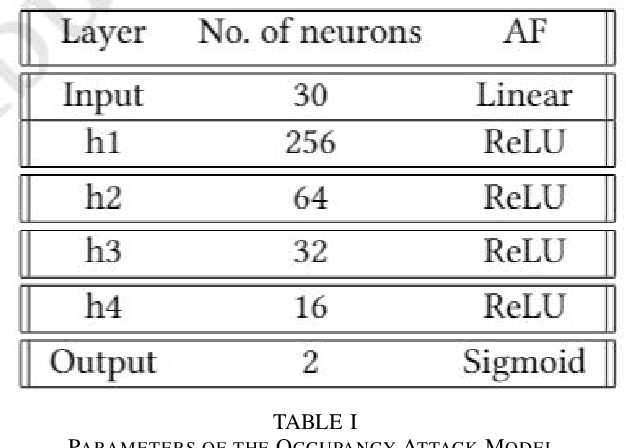
Utilities around the world are reported to invest a total of around 30 billion over the next few years for installation of more than 300 million smart meters, replacing traditional analog meters [1]. By mid-decade, with full country wide deployment, there will be almost 1.3 billion smart meters in place [1]. Collection of fine grained energy usage data by these smart meters provides numerous advantages such as energy savings for customers with use of demand optimization, a billing system of higher accuracy with dynamic pricing programs, bidirectional information exchange ability between end-users for better consumer-operator interaction, and so on. However, all these perks associated with fine grained energy usage data collection threaten the privacy of users. With this technology, customers' personal data such as sleeping cycle, number of occupants, and even type and number of appliances stream into the hands of the utility companies and can be subject to misuse. This research paper addresses privacy violation of consumers' energy usage data collected from smart meters and provides a novel solution for the privacy protection while allowing benefits of energy data analytics. First, we demonstrate the successful application of occupancy detection attacks using a deep neural network method that yields high accuracy results. We then introduce Adversarial Machine Learning Occupancy Detection Avoidance with Blockchain (AMLODA-B) framework as a counter-attack by deploying an algorithm based on the Long Short Term Memory (LSTM) model into the standardized smart metering infrastructure to prevent leakage of consumers personal information. Our privacy-aware approach protects consumers' privacy without compromising the correctness of billing and preserves operational efficiency without use of authoritative intermediaries.
Improving DGA-Based Malicious Domain Classifiers for Malware Defense with Adversarial Machine Learning
Jan 02, 2021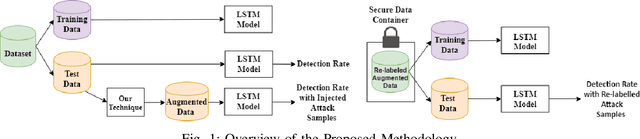
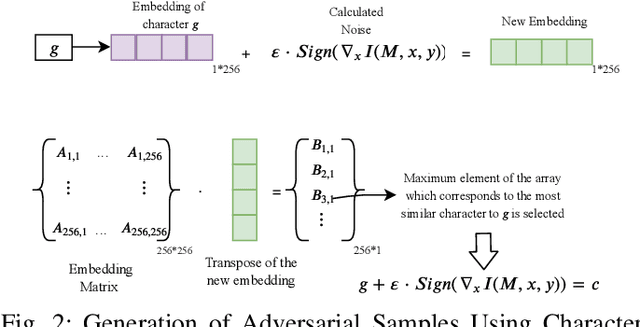
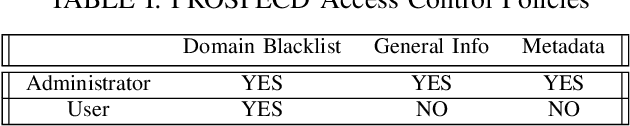
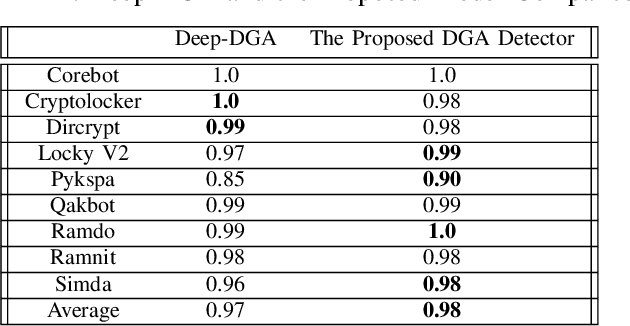
Domain Generation Algorithms (DGAs) are used by adversaries to establish Command and Control (C\&C) server communications during cyber attacks. Blacklists of known/identified C\&C domains are often used as one of the defense mechanisms. However, since blacklists are static and generated by signature-based approaches, they can neither keep up nor detect never-seen-before malicious domain names. Due to this shortcoming of blacklist domain checking, machine learning algorithms have been used to address the problem to some extent. However, when training is performed with limited datasets, the algorithms are likely to fail in detecting new DGA variants. To mitigate this weakness, we successfully applied a DGA-based malicious domain classifier using the Long Short-Term Memory (LSTM) method with a novel feature engineering technique. Our model's performance shows a higher level of accuracy compared to a previously reported model from prior research. Additionally, we propose a new method using adversarial machine learning to generate never-before-seen malware-related domain families that can be used to illustrate the shortcomings of machine learning algorithms in this regard. Next, we augment the training dataset with new samples such that it makes training of the machine learning models more effective in detecting never-before-seen malicious domain name variants. Finally, to protect blacklists of malicious domain names from disclosure and tampering, we devise secure data containers that store blacklists and guarantee their protection against adversarial access and modifications.
Avoiding Occupancy Detection from Smart Meter using Adversarial Machine Learning
Oct 23, 2020



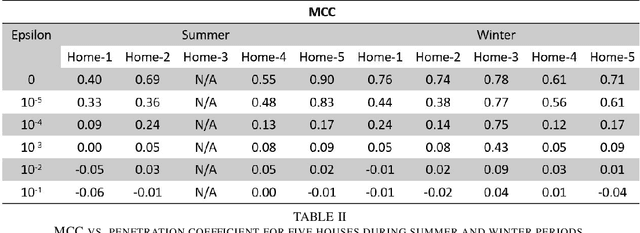
More and more conventional electromechanical meters are being replaced with smart meters because of their substantial benefits such as providing faster bi-directional communication between utility services and end users, enabling direct load control for demand response, energy saving, and so on. However, the fine-grained usage data provided by smart meter brings additional vulnerabilities from users to companies. Occupancy detection is one such example which causes privacy violation of smart meter users. Detecting the occupancy of a home is straightforward with time of use information as there is a strong correlation between occupancy and electricity usage. In this work, our major contributions are twofold. First, we validate the viability of an occupancy detection attack based on a machine learning technique called Long Short Term Memory (LSTM) method and demonstrate improved results. In addition, we introduce an Adversarial Machine Learning Occupancy Detection Avoidance (AMLODA) framework as a counter attack in order to prevent abuse of energy consumption. Essentially, the proposed privacy-preserving framework is designed to mask real-time or near real-time electricity usage information using calculated optimum noise without compromising users' billing systems functionality. Our results show that the proposed privacy-aware billing technique upholds users' privacy strongly.
Investigating bankruptcy prediction models in the presence of extreme class imbalance and multiple stages of economy
Nov 22, 2019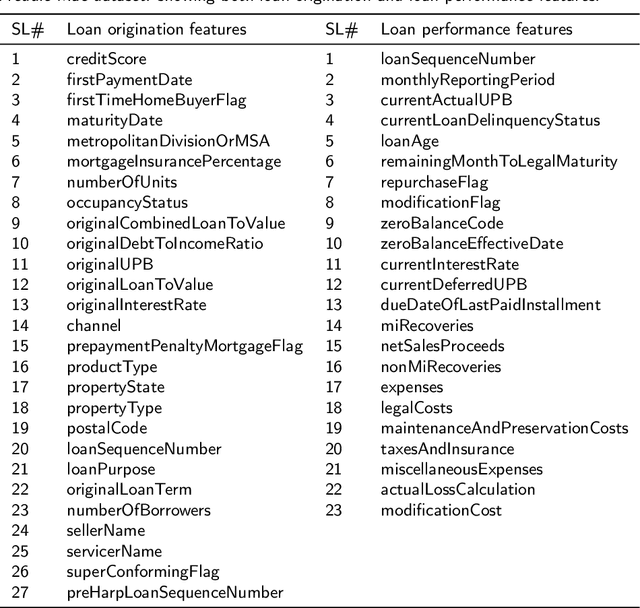
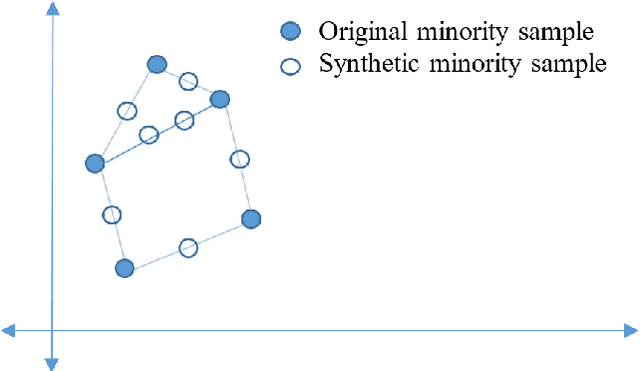
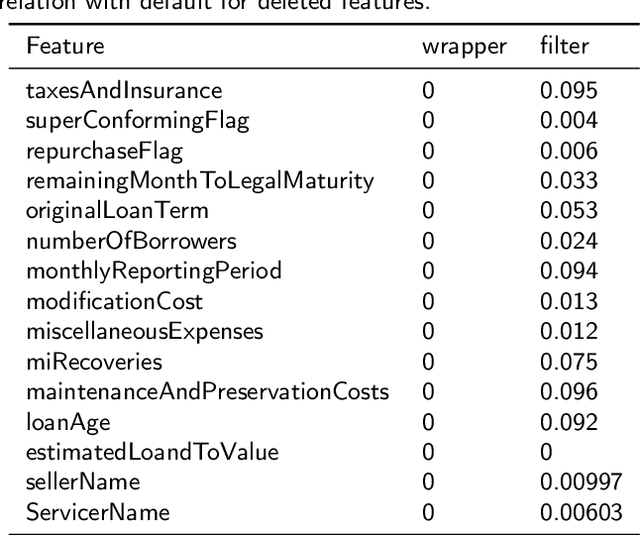
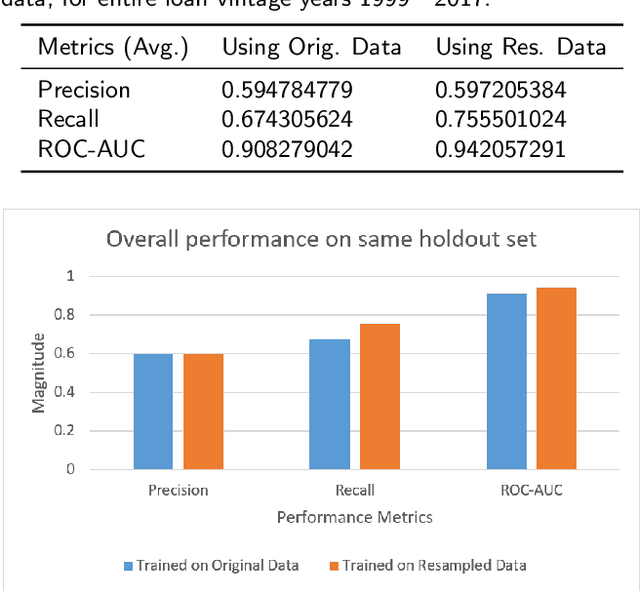
In the area of credit risk analytics, current Bankruptcy Prediction Models (BPMs) struggle with (a) the availability of comprehensive and real-world data sets and (b) the presence of extreme class imbalance in the data (i.e., very few samples for the minority class) that degrades the performance of the prediction model. Moreover, little research has compared the relative performance of well-known BPM's on public datasets addressing the class imbalance problem. In this work, we apply eight classes of well-known BPMs, as suggested by a review of decades of literature, on a new public dataset named Freddie Mac Single-Family Loan-Level Dataset with resampling (i.e., adding synthetic minority samples) of the minority class to tackle class imbalance. Additionally, we apply some recent AI techniques (e.g., tree-based ensemble techniques) that demonstrate potentially better results on models trained with resampled data. In addition, from the analysis of 19 years (1999-2017) of data, we discover that models behave differently when presented with sudden changes in the economy (e.g., a global financial crisis) resulting in abrupt fluctuations in the national default rate. In summary, this study should aid practitioners/researchers in determining the appropriate model with respect to data that contains a class imbalance and various economic stages.
Domain Knowledge Aided Explainable Artificial Intelligence for Intrusion Detection and Response
Nov 22, 2019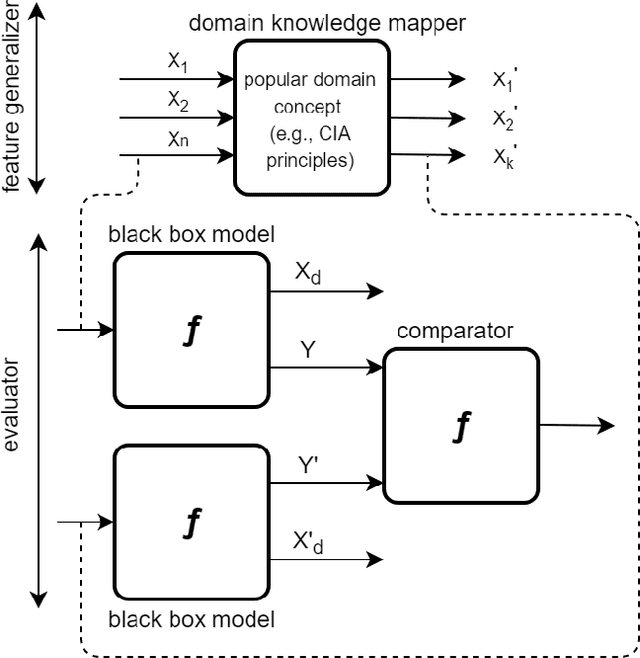


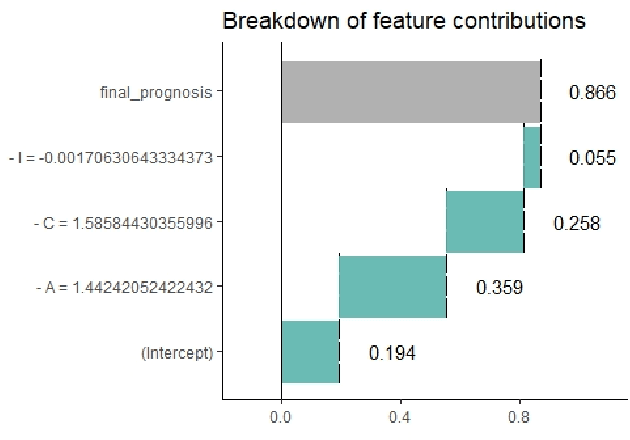
Artificial Intelligence (AI) has become an integral part of modern-day security solutions for its capability of learning very complex functions and handling "Big Data". However, the lack of explainability and interpretability of successful AI models is a key stumbling block when trust in a model's prediction is critical. This leads to human intervention, which in turn results in a delayed response or decision. While there have been major advancements in the speed and performance of AI-based intrusion detection systems, the response is still at human speed when it comes to explaining and interpreting a specific prediction or decision. In this work, we infuse popular domain knowledge (i.e., CIA principles) in our model for better explainability and validate the approach on a network intrusion detection test case. Our experimental results suggest that the infusion of domain knowledge provides better explainability as well as a faster decision or response. In addition, the infused domain knowledge generalizes the model to work well with unknown attacks, as well as open the path to adapt to a large stream of network traffic from numerous IoT devices.