 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFIGO: Enhanced Fingerprint Identification Approach Using GAN and One Shot Learning Techniques
Aug 11, 2022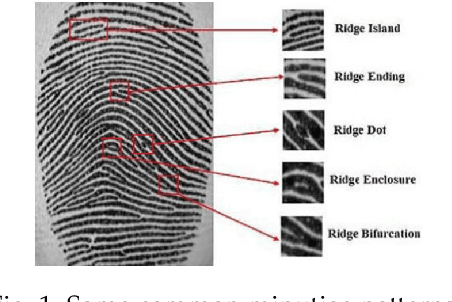

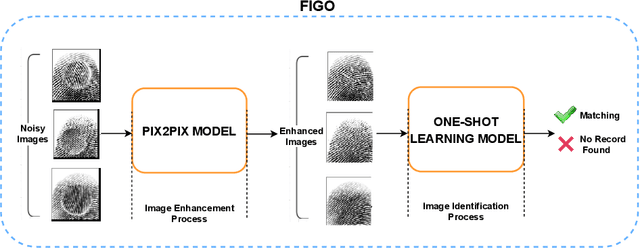
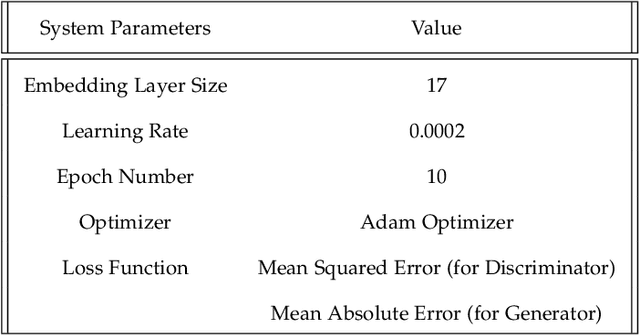
Fingerprint evidence plays an important role in a criminal investigation for the identification of individuals. Although various techniques have been proposed for fingerprint classification and feature extraction, automated fingerprint identification of fingerprints is still in its earliest stage. The performance of traditional \textit{Automatic Fingerprint Identification System} (AFIS) depends on the presence of valid minutiae points and still requires human expert assistance in feature extraction and identification stages. Based on this motivation, we propose a Fingerprint Identification approach based on Generative adversarial network and One-shot learning techniques (FIGO). Our solution contains two components: fingerprint enhancement tier and fingerprint identification tier. First, we propose a Pix2Pix model to transform low-quality fingerprint images to a higher level of fingerprint images pixel by pixel directly in the fingerprint enhancement tier. With the proposed enhancement algorithm, the fingerprint identification model's performance is significantly improved. Furthermore, we develop another existing solution based on Gabor filters as a benchmark to compare with the proposed model by observing the fingerprint device's recognition accuracy. Experimental results show that our proposed Pix2pix model has better support than the baseline approach for fingerprint identification. Second, we construct a fully automated fingerprint feature extraction model using a one-shot learning approach to differentiate each fingerprint from the others in the fingerprint identification process. Two twin convolutional neural networks (CNNs) with shared weights and parameters are used to obtain the feature vectors in this process. Using the proposed method, we demonstrate that it is possible to learn necessary information from only one training sample with high accuracy.
Privacy Protection of Grid Users Data with Blockchain and Adversarial Machine Learning
Jan 15, 2021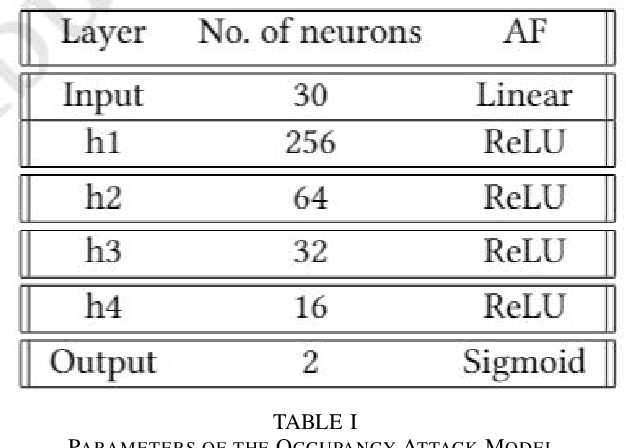
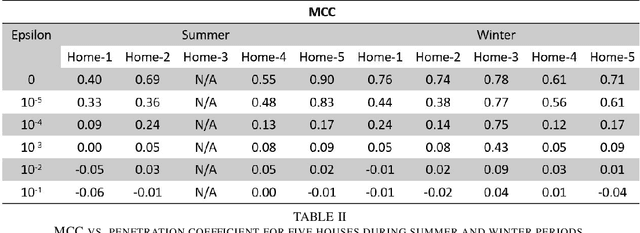
Utilities around the world are reported to invest a total of around 30 billion over the next few years for installation of more than 300 million smart meters, replacing traditional analog meters [1]. By mid-decade, with full country wide deployment, there will be almost 1.3 billion smart meters in place [1]. Collection of fine grained energy usage data by these smart meters provides numerous advantages such as energy savings for customers with use of demand optimization, a billing system of higher accuracy with dynamic pricing programs, bidirectional information exchange ability between end-users for better consumer-operator interaction, and so on. However, all these perks associated with fine grained energy usage data collection threaten the privacy of users. With this technology, customers' personal data such as sleeping cycle, number of occupants, and even type and number of appliances stream into the hands of the utility companies and can be subject to misuse. This research paper addresses privacy violation of consumers' energy usage data collected from smart meters and provides a novel solution for the privacy protection while allowing benefits of energy data analytics. First, we demonstrate the successful application of occupancy detection attacks using a deep neural network method that yields high accuracy results. We then introduce Adversarial Machine Learning Occupancy Detection Avoidance with Blockchain (AMLODA-B) framework as a counter-attack by deploying an algorithm based on the Long Short Term Memory (LSTM) model into the standardized smart metering infrastructure to prevent leakage of consumers personal information. Our privacy-aware approach protects consumers' privacy without compromising the correctness of billing and preserves operational efficiency without use of authoritative intermediaries.
Improving DGA-Based Malicious Domain Classifiers for Malware Defense with Adversarial Machine Learning
Jan 02, 2021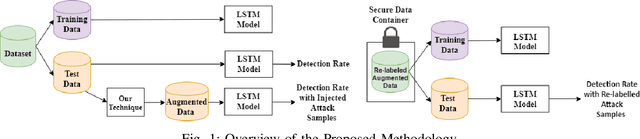
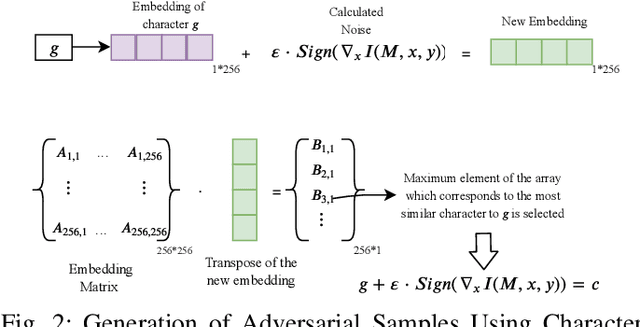
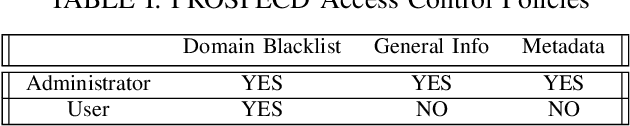
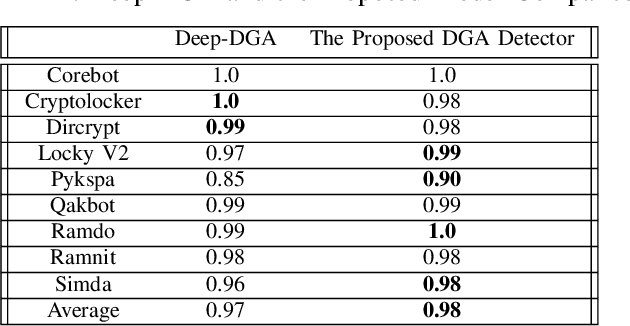
Domain Generation Algorithms (DGAs) are used by adversaries to establish Command and Control (C\&C) server communications during cyber attacks. Blacklists of known/identified C\&C domains are often used as one of the defense mechanisms. However, since blacklists are static and generated by signature-based approaches, they can neither keep up nor detect never-seen-before malicious domain names. Due to this shortcoming of blacklist domain checking, machine learning algorithms have been used to address the problem to some extent. However, when training is performed with limited datasets, the algorithms are likely to fail in detecting new DGA variants. To mitigate this weakness, we successfully applied a DGA-based malicious domain classifier using the Long Short-Term Memory (LSTM) method with a novel feature engineering technique. Our model's performance shows a higher level of accuracy compared to a previously reported model from prior research. Additionally, we propose a new method using adversarial machine learning to generate never-before-seen malware-related domain families that can be used to illustrate the shortcomings of machine learning algorithms in this regard. Next, we augment the training dataset with new samples such that it makes training of the machine learning models more effective in detecting never-before-seen malicious domain name variants. Finally, to protect blacklists of malicious domain names from disclosure and tampering, we devise secure data containers that store blacklists and guarantee their protection against adversarial access and modifications.
Practical Fast Gradient Sign Attack against Mammographic Image Classifier
Jan 27, 2020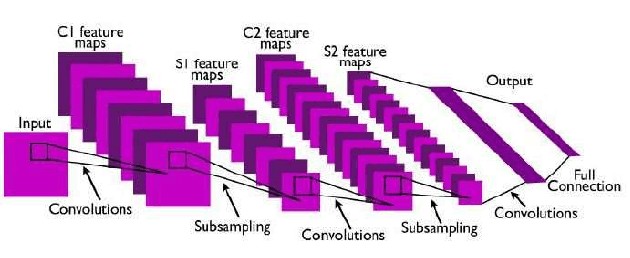
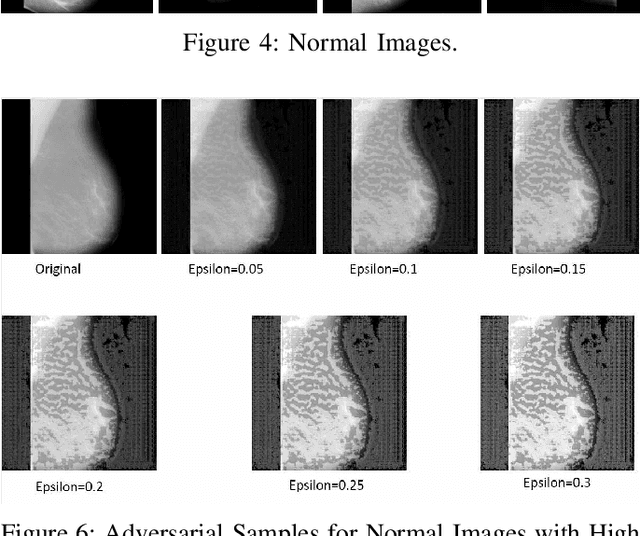
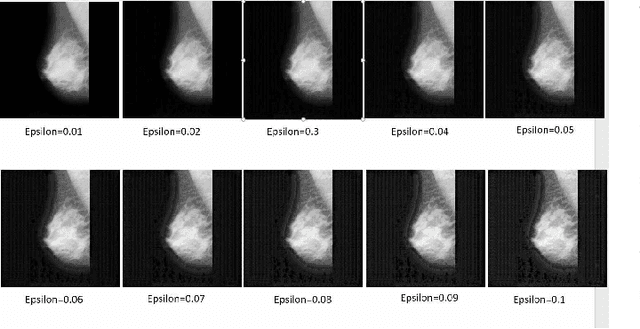
Artificial intelligence (AI) has been a topic of major research for many years. Especially, with the emergence of deep neural network (DNN), these studies have been tremendously successful. Today machines are capable of making faster, more accurate decision than human. Thanks to the great development of machine learning (ML) techniques, ML have been used many different fields such as education, medicine, malware detection, autonomous car etc. In spite of having this degree of interest and much successful research, ML models are still vulnerable to adversarial attacks. Attackers can manipulate clean data in order to fool the ML classifiers to achieve their desire target. For instance; a benign sample can be modified as a malicious sample or a malicious one can be altered as benign while this modification can not be recognized by human observer. This can lead to many financial losses, or serious injuries, even deaths. The motivation behind this paper is that we emphasize this issue and want to raise awareness. Therefore, the security gap of mammographic image classifier against adversarial attack is demonstrated. We use mamographic images to train our model then evaluate our model performance in terms of accuracy. Later on, we poison original dataset and generate adversarial samples that missclassified by the model. We then using structural similarity index (SSIM) analyze similarity between clean images and adversarial images. Finally, we show how successful we are to misuse by using different poisoning factors.
Expansion of Cyber Attack Data From Unbalanced Datasets Using Generative Techniques
Dec 10, 2019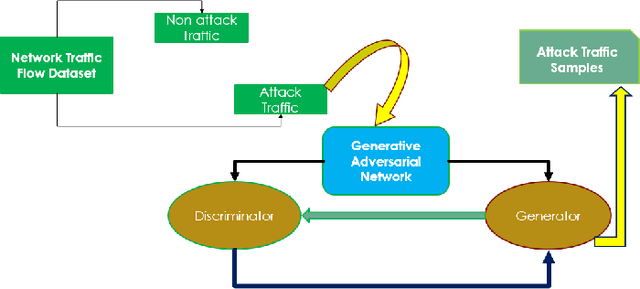
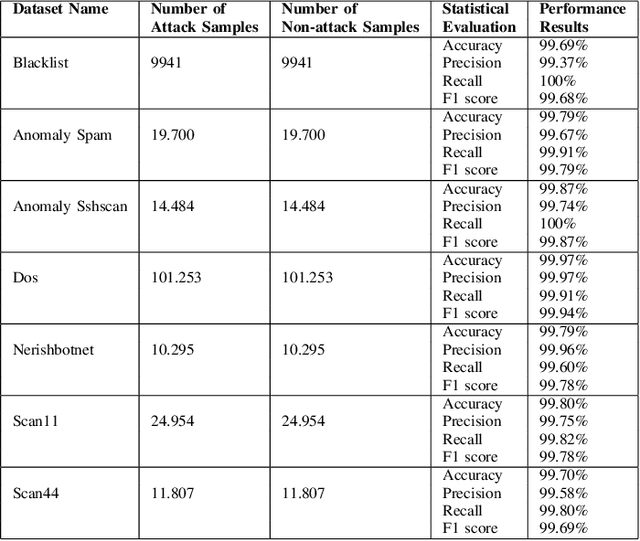
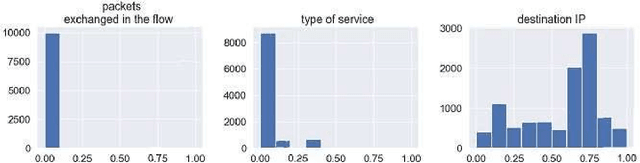
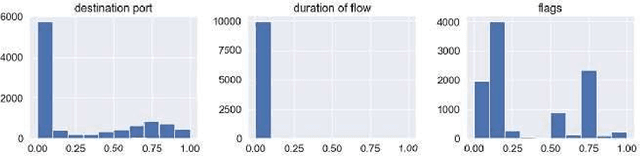
Machine learning techniques help to understand patterns of a dataset to create a defense mechanism against cyber attacks. However, it is difficult to construct a theoretical model due to the imbalances in the dataset for discriminating attacks from the overall dataset. Multilayer Perceptron (MLP) technique will provide improvement in accuracy and increase the performance of detecting the attack and benign data from a balanced dataset. We have worked on the UGR'16 dataset publicly available for this work. Data wrangling has been done due to prepare test set from in the original set. We fed the neural network classifier larger input to the neural network in an increasing manner (i.e. 10000, 50000, 1 million) to see the distribution of features over the accuracy. We have implemented a GAN model that can produce samples of different attack labels (e.g. blacklist, anomaly spam, ssh scan). We have been able to generate as many samples as necessary based on the data sample we have taken from the UGR'16. We have tested the accuracy of our model with the imbalance dataset initially and then with the increasing the attack samples and found improvement of classification performance for the latter.