 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Artificial Intelligence Approaches: A Survey
Jan 23, 2021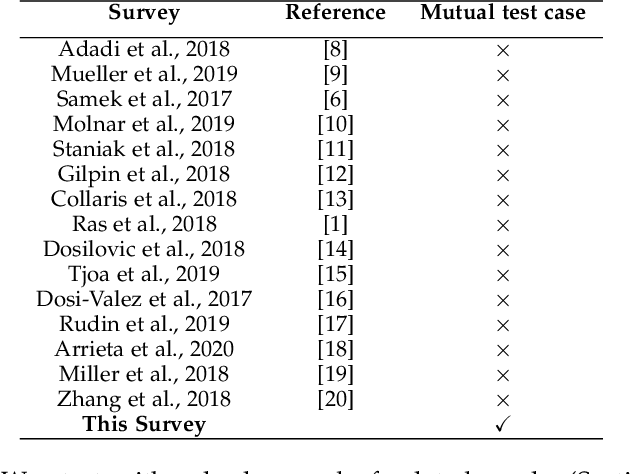
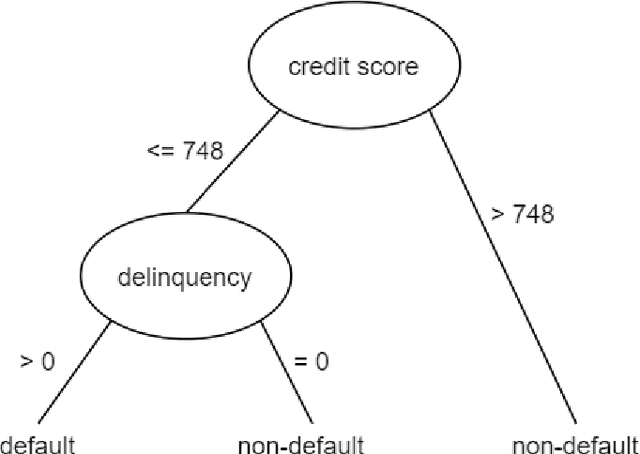

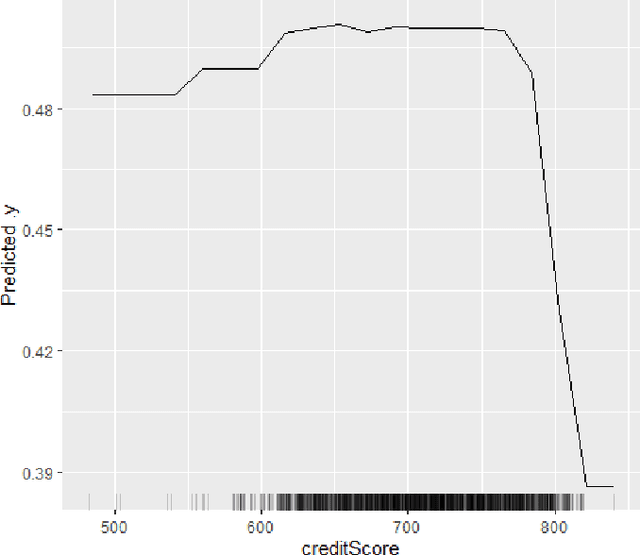
The lack of explainability of a decision from an Artificial Intelligence (AI) based "black box" system/model, despite its superiority in many real-world applications, is a key stumbling block for adopting AI in many high stakes applications of different domain or industry. While many popular Explainable Artificial Intelligence (XAI) methods or approaches are available to facilitate a human-friendly explanation of the decision, each has its own merits and demerits, with a plethora of open challenges. We demonstrate popular XAI methods with a mutual case study/task (i.e., credit default prediction), analyze for competitive advantages from multiple perspectives (e.g., local, global), provide meaningful insight on quantifying explainability, and recommend paths towards responsible or human-centered AI using XAI as a medium. Practitioners can use this work as a catalog to understand, compare, and correlate competitive advantages of popular XAI methods. In addition, this survey elicits future research directions towards responsible or human-centric AI systems, which is crucial to adopt AI in high stakes applications.
Infusing domain knowledge in AI-based "black box" models for better explainability with application in bankruptcy prediction
May 30, 2019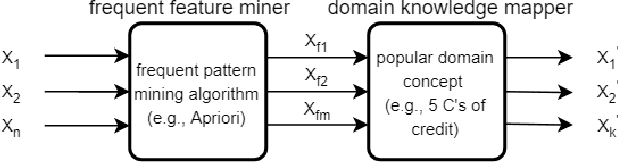
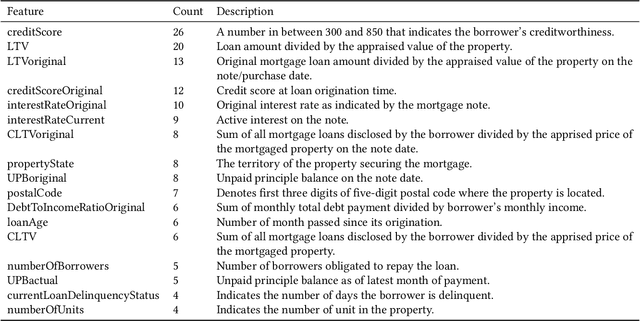
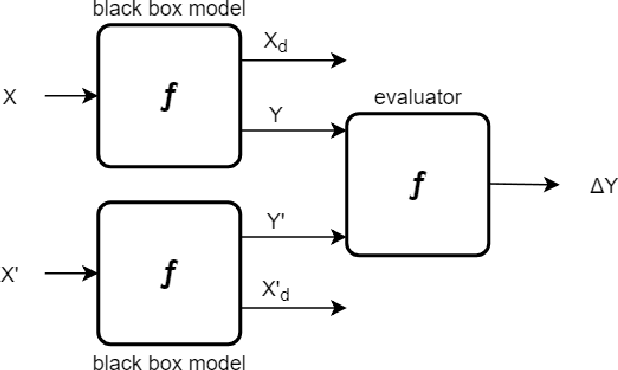

Although "black box" models such as Artificial Neural Networks, Support Vector Machines, and Ensemble Approaches continue to show superior performance in many disciplines, their adoption in the sensitive disciplines (e.g., finance, healthcare) is questionable due to the lack of interpretability and explainability of the model. In fact, future adoption of "black box" models is difficult because of the recent rule of "right of explanation" by the European Union where a user can ask for an explanation behind an algorithmic decision, and the newly proposed bill by the US government, the "Algorithmic Accountability Act", which would require companies to assess their machine learning systems for bias and discrimination and take corrective measures. Top Bankruptcy Prediction Models are A.I.-based and are in need of better explainability -the extent to which the internal working mechanisms of an AI system can be explained in human terms. Although explainable artificial intelligence is an emerging field of research, infusing domain knowledge for better explainability might be a possible solution. In this work, we demonstrate a way to collect and infuse domain knowledge into a "black box" model for bankruptcy prediction. Our understanding from the experiments reveals that infused domain knowledge makes the output from the black box model more interpretable and explainable.
Mining Illegal Insider Trading of Stocks: A Proactive Approach
Aug 21, 2018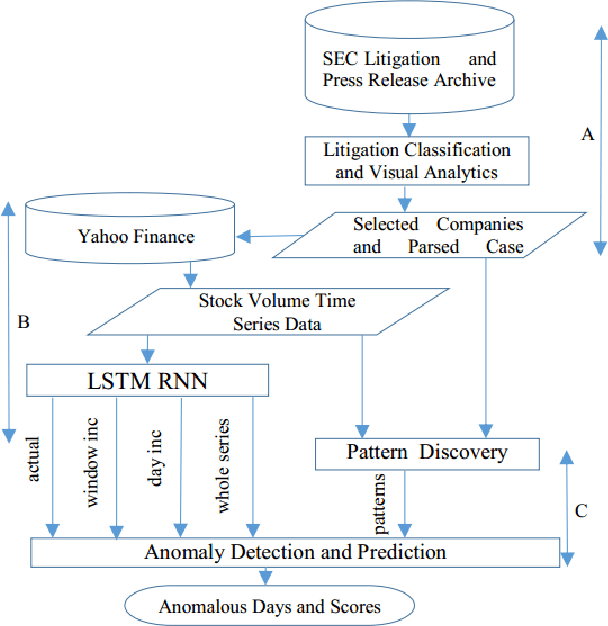
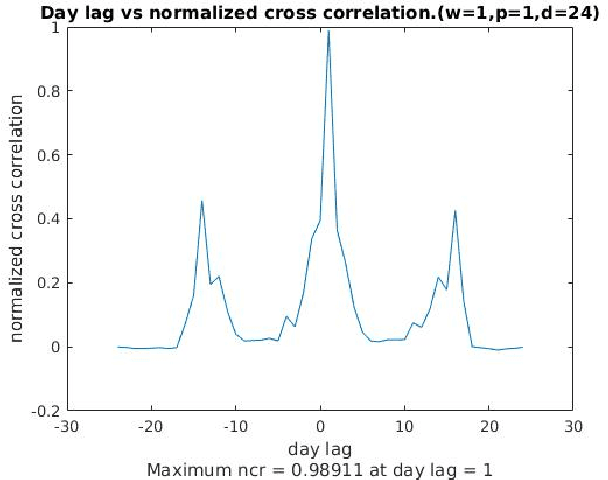
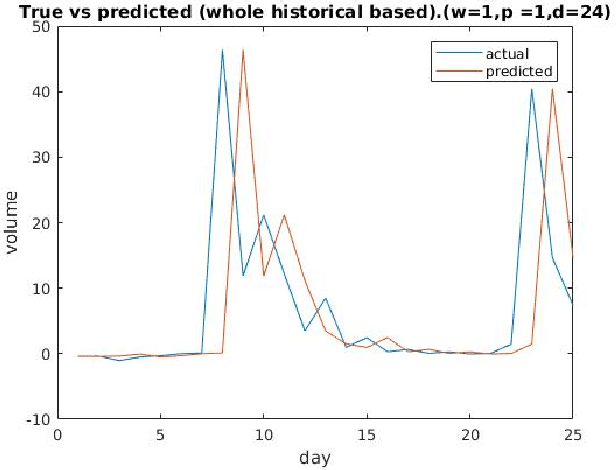
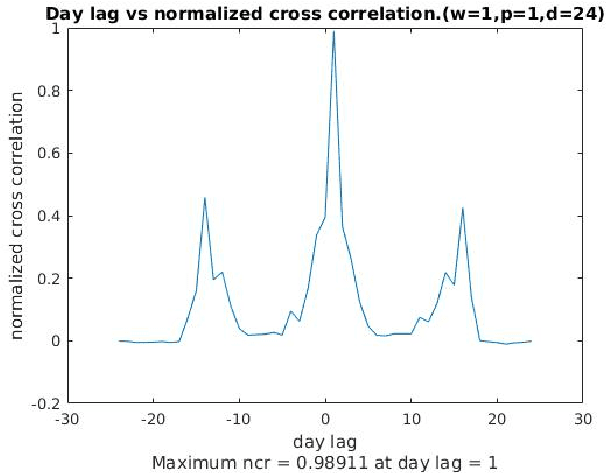
Illegal insider trading of stocks is based on releasing non-public information (e.g., new product launch, quarterly financial report, acquisition or merger plan) before the information is made public. Detecting illegal insider trading is difficult due to the complex, nonlinear, and non-stationary nature of the stock market. In this work, we present an approach that detects and predicts illegal insider trading proactively from large heterogeneous sources of structured and unstructured data using a deep-learning based approach combined with discrete signal processing on the time series data. In addition, we use a tree-based approach that visualizes events and actions to aid analysts in their understanding of large amounts of unstructured data. Using existing data, we have discovered that our approach has a good success rate in detecting illegal insider trading patterns.
Credit Default Mining Using Combined Machine Learning and Heuristic Approach
Jul 02, 2018
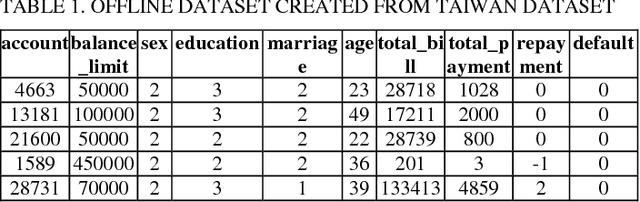
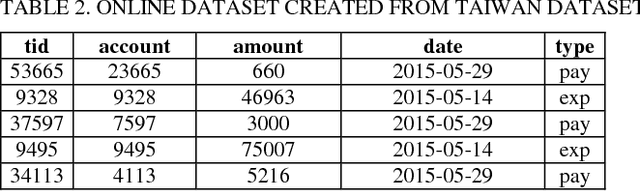
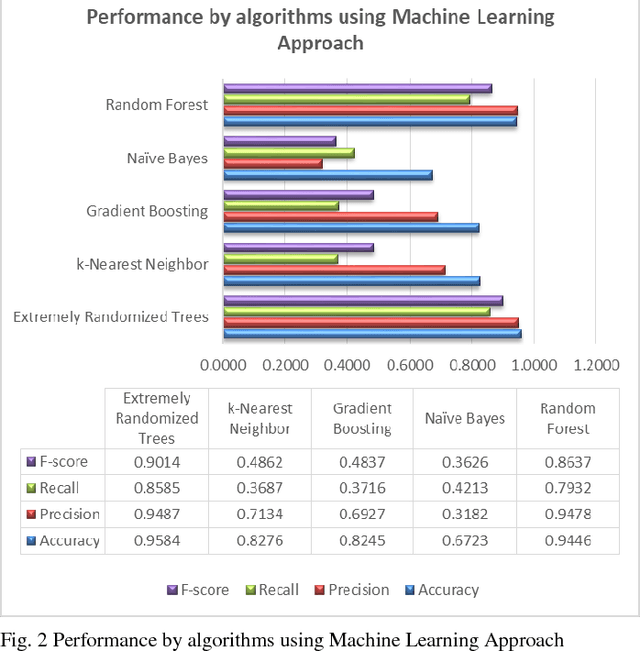
Predicting potential credit default accounts in advance is challenging. Traditional statistical techniques typically cannot handle large amounts of data and the dynamic nature of fraud and humans. To tackle this problem, recent research has focused on artificial and computational intelligence based approaches. In this work, we present and validate a heuristic approach to mine potential default accounts in advance where a risk probability is precomputed from all previous data and the risk probability for recent transactions are computed as soon they happen. Beside our heuristic approach, we also apply a recently proposed machine learning approach that has not been applied previously on our targeted dataset [15]. As a result, we find that these applied approaches outperform existing state-of-the-art approaches.