 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKVC-onGoing: Keystroke Verification Challenge
Dec 29, 2024



This article presents the Keystroke Verification Challenge - onGoing (KVC-onGoing), on which researchers can easily benchmark their systems in a common platform using large-scale public databases, the Aalto University Keystroke databases, and a standard experimental protocol. The keystroke data consist of tweet-long sequences of variable transcript text from over 185,000 subjects, acquired through desktop and mobile keyboards simulating real-life conditions. The results on the evaluation set of KVC-onGoing have proved the high discriminative power of keystroke dynamics, reaching values as low as 3.33% of Equal Error Rate (EER) and 11.96% of False Non-Match Rate (FNMR) @1% False Match Rate (FMR) in the desktop scenario, and 3.61% of EER and 17.44% of FNMR @1% at FMR in the mobile scenario, significantly improving previous state-of-the-art results. Concerning demographic fairness, the analyzed scores reflect the subjects' age and gender to various extents, not negligible in a few cases. The framework runs on CodaLab.
Statistical Keystroke Synthesis for Improved Bot Detection
Jul 28, 2022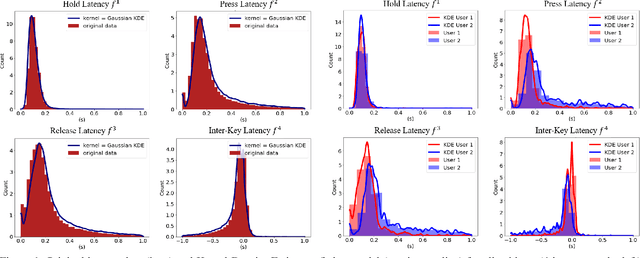

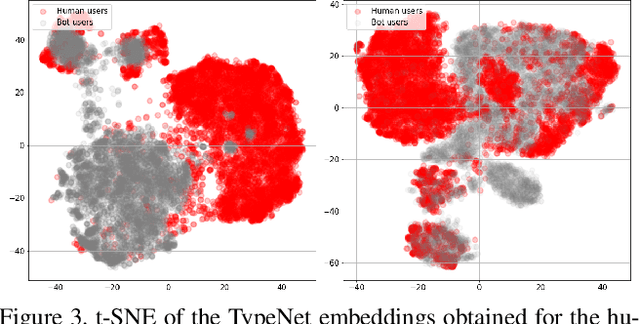
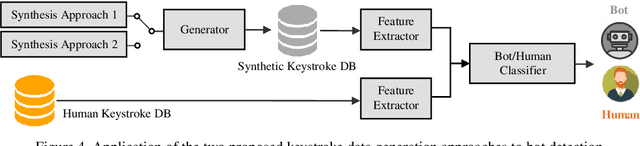
This work proposes two statistical approaches for the synthesis of keystroke biometric data based on Universal and User-dependent Models. Both approaches are validated on the bot detection task, using the keystroke synthetic data to better train the systems. Our experiments include a dataset with 136 million keystroke events from 168,000 subjects. We have analyzed the performance of the two synthesis approaches through qualitative and quantitative experiments. Different bot detectors are considered based on two supervised classifiers (Support Vector Machine and Long Short-Term Memory network) and a learning framework including human and generated samples. Our results prove that the proposed statistical approaches are able to generate realistic human-like synthetic keystroke samples. Also, the classification results suggest that in scenarios with large labeled data, these synthetic samples can be detected with high accuracy. However, in few-shot learning scenarios it represents an important challenge.
Mobile Behavioral Biometrics for Passive Authentication
Mar 14, 2022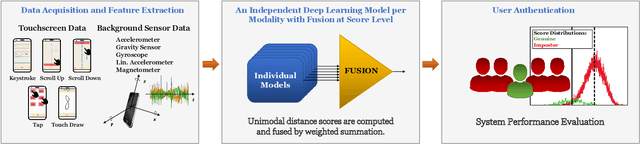
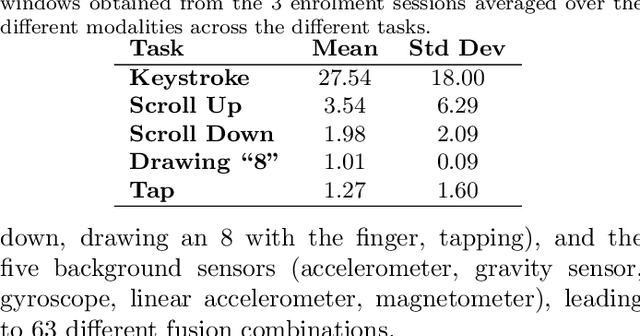

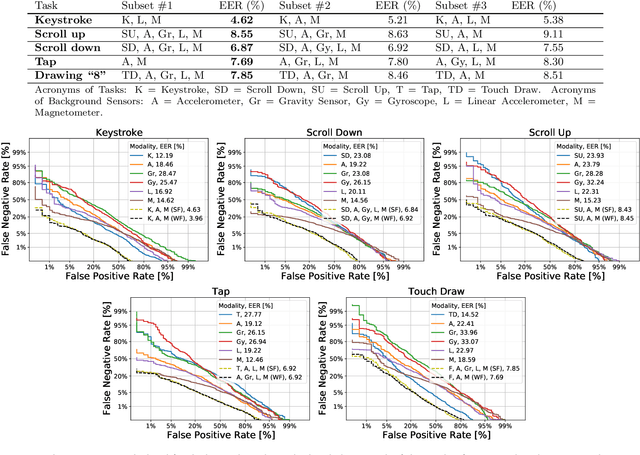
Current mobile user authentication systems based on PIN codes, fingerprint, and face recognition have several shortcomings. Such limitations have been addressed in the literature by exploring the feasibility of passive authentication on mobile devices through behavioral biometrics. In this line of research, this work carries out a comparative analysis of unimodal and multimodal behavioral biometric traits acquired while the subjects perform different activities on the phone such as typing, scrolling, drawing a number, and tapping on the screen, considering the touchscreen and the simultaneous background sensor data (accelerometer, gravity sensor, gyroscope, linear accelerometer, and magnetometer). Our experiments are performed over HuMIdb, one of the largest and most comprehensive freely available mobile user interaction databases to date. A separate Recurrent Neural Network (RNN) with triplet loss is implemented for each single modality. Then, the weighted fusion of the different modalities is carried out at score level. In our experiments, the most discriminative background sensor is the magnetometer, whereas among touch tasks the best results are achieved with keystroke in a fixed-text scenario. In all cases, the fusion of modalities is very beneficial, leading to Equal Error Rates (EER) ranging from 4% to 9% depending on the modality combination in a 3-second interval.
SetMargin Loss applied to Deep Keystroke Biometrics with Circle Packing Interpretation
Sep 02, 2021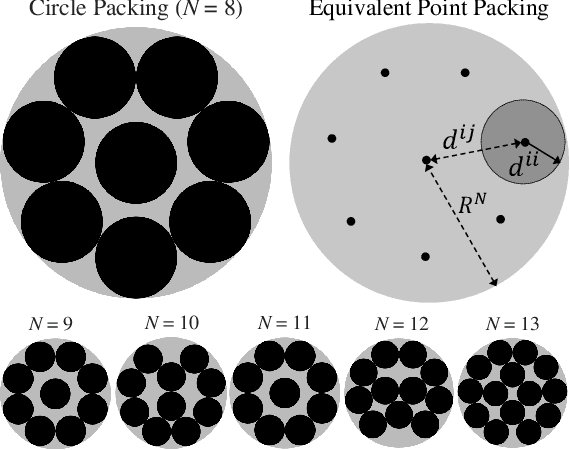
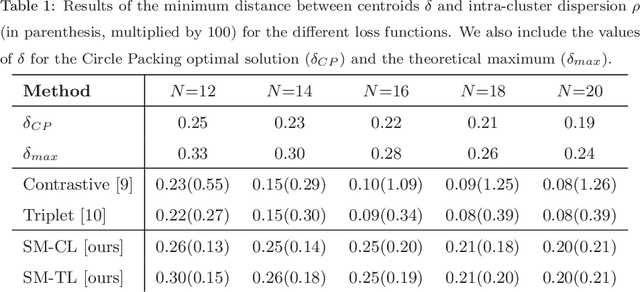
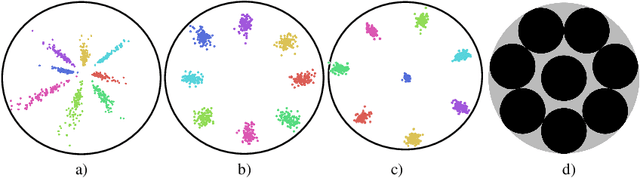
This work presents a new deep learning approach for keystroke biometrics based on a novel Distance Metric Learning method (DML). DML maps input data into a learned representation space that reveals a "semantic" structure based on distances. In this work, we propose a novel DML method specifically designed to address the challenges associated to free-text keystroke identification where the classes used in learning and inference are disjoint. The proposed SetMargin Loss (SM-L) extends traditional DML approaches with a learning process guided by pairs of sets instead of pairs of samples, as done traditionally. The proposed learning strategy allows to enlarge inter-class distances while maintaining the intra-class structure of keystroke dynamics. We analyze the resulting representation space using the mathematical problem known as Circle Packing, which provides neighbourhood structures with a theoretical maximum inter-class distance. We finally prove experimentally the effectiveness of the proposed approach on a challenging task: keystroke biometric identification over a large set of 78,000 subjects. Our method achieves state-of-the-art accuracy on a comparison performed with the best existing approaches.
TypeNet: Deep Learning Keystroke Biometrics
Feb 18, 2021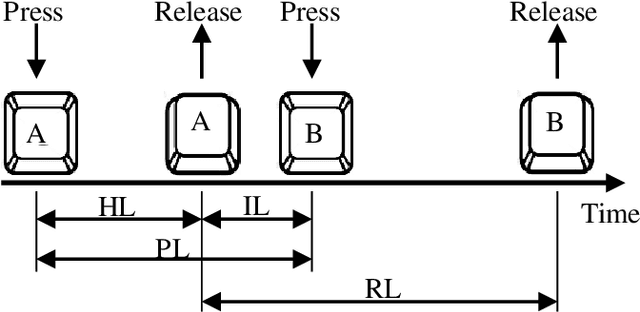
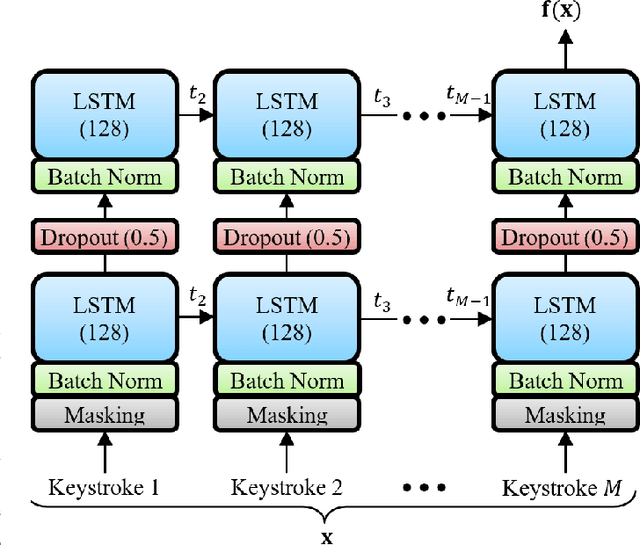
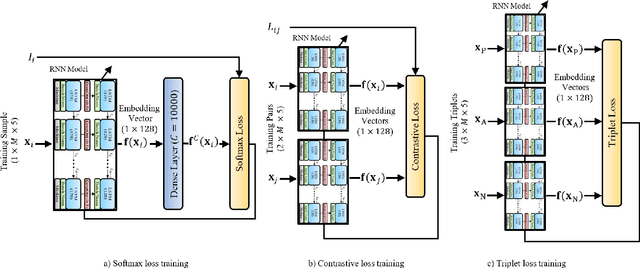
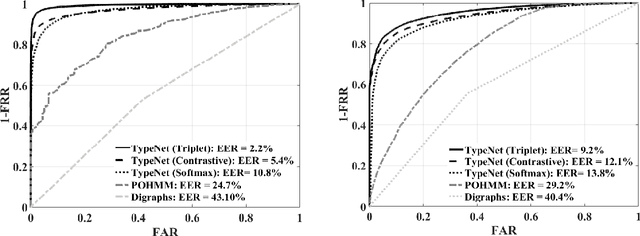
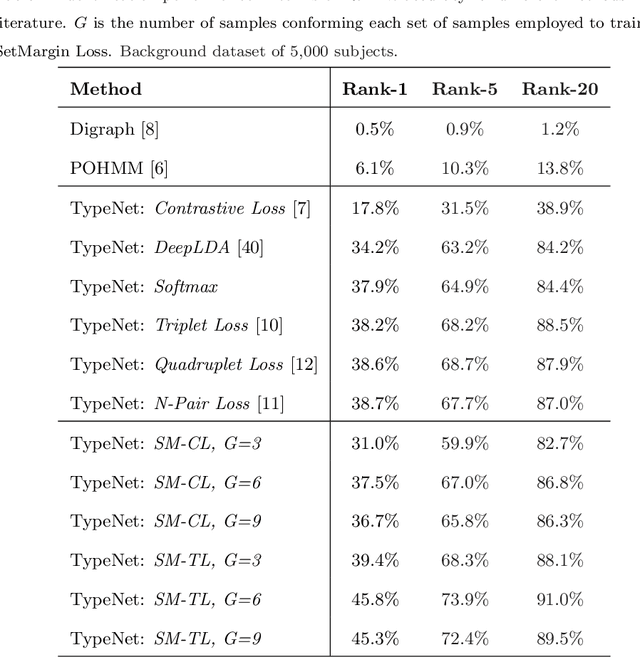
We study the performance of Long Short-Term Memory networks for keystroke biometric authentication at large scale in free-text scenarios. For this we introduce TypeNet, a Recurrent Neural Network (RNN) trained with a moderate number of keystrokes per identity. We evaluate different learning approaches depending on the loss function (softmax, contrastive, and triplet loss), number of gallery samples, length of the keystroke sequences, and device type (physical vs touchscreen keyboard). With 5 gallery sequences and test sequences of length 50, TypeNet achieves state-of-the-art keystroke biometric authentication performance with an Equal Error Rate of 2.2% and 9.2% for physical and touchscreen keyboards, respectively, significantly outperforming previous approaches. Our experiments demonstrate a moderate increase in error with up to 100,000 subjects, demonstrating the potential of TypeNet to operate at an Internet scale. We utilize two Aalto University keystroke databases, one captured on physical keyboards and the second on mobile devices (touchscreen keyboards). To the best of our knowledge, both databases are the largest existing free-text keystroke databases available for research with more than 136 million keystrokes from 168,000 subjects in physical keyboards, and 60,000 subjects with more than 63 million keystrokes acquired on mobile touchscreens.
Keystroke Biometrics in Response to Fake News Propagation in a Global Pandemic
May 18, 2020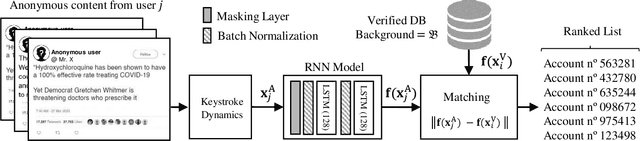
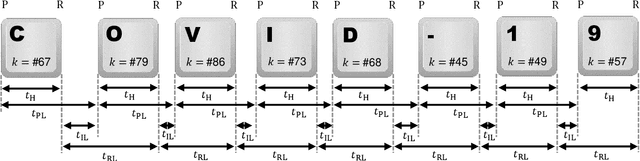
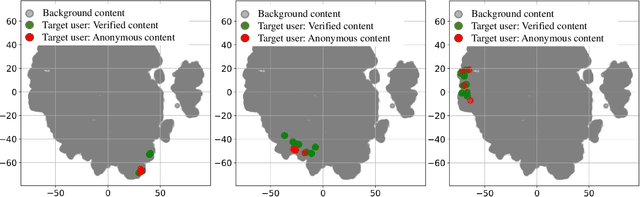
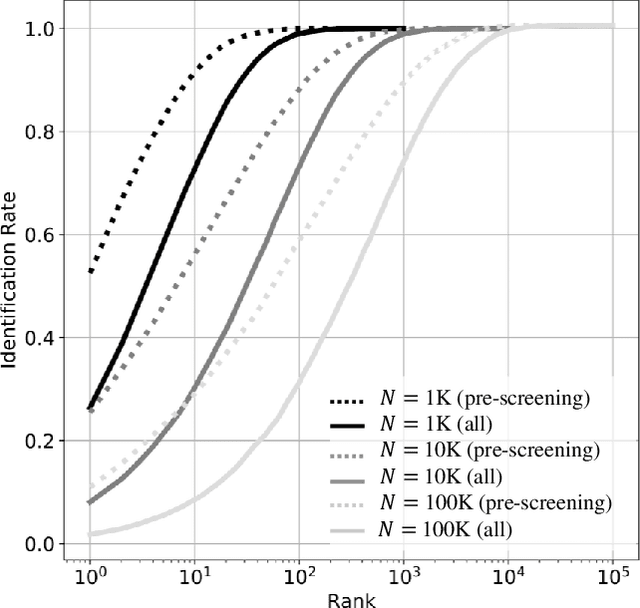
This work proposes and analyzes the use of keystroke biometrics for content de-anonymization. Fake news have become a powerful tool to manipulate public opinion, especially during major events. In particular, the massive spread of fake news during the COVID-19 pandemic has forced governments and companies to fight against missinformation. In this context, the ability to link multiple accounts or profiles that spread such malicious content on the Internet while hiding in anonymity would enable proactive identification and blacklisting. Behavioral biometrics can be powerful tools in this fight. In this work, we have analyzed how the latest advances in keystroke biometric recognition can help to link behavioral typing patterns in experiments involving 100,000 users and more than 1 million typed sequences. Our proposed system is based on Recurrent Neural Networks adapted to the context of content de-anonymization. Assuming the challenge to link the typed content of a target user in a pool of candidate profiles, our results show that keystroke recognition can be used to reduce the list of candidate profiles by more than 90%. In addition, when keystroke is combined with auxiliary data (such as location), our system achieves a Rank-1 identification performance equal to 52.6% and 10.9% for a background candidate list composed of 1K and 100K profiles, respectively.
* arXiv admin note: text overlap with arXiv:2004.03627
BeCAPTCHA-Mouse: Synthetic Mouse Trajectories and Improved Bot Detection
May 02, 2020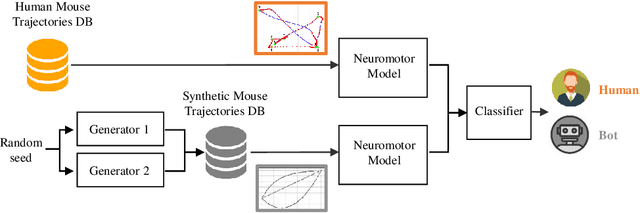


We first study the suitability of behavioral biometrics to distinguish between computers and humans, commonly named as bot detection. We then present BeCAPTCHA-Mouse, a bot detector based on neuromotor modeling of mouse dynamics that enhances traditional CAPTCHA methods. Our proposed bot detector is trained using both human and bot data generated by two new methods developed for generating realistic synthetic mouse trajectories: i) a knowledge-based method based on heuristic functions, and ii) a data-driven method based on Generative Adversarial Networks (GANs) in which a Generator synthesizes human-like trajectories from a Gaussian noise input. Experiments are conducted on a new testbed also introduced here and available in GitHub: BeCAPTCHA-Mouse Benchmark; useful for research in bot detection and other mouse-based HCI applications. Our benchmark data consists of 10,000 mouse trajectories including real data from 58 users and bot data with various levels of realism. Our experiments show that BeCAPTCHA-Mouse is able to detect bot trajectories of high realism with 93% of accuracy in average using only one mouse trajectory. When our approach is fused with state-of-the-art mouse dynamic features, the bot detection accuracy increases relatively by more than 36%, proving that mouse-based bot detection is a fast, easy, and reliable tool to complement traditional CAPTCHA systems.
TypeNet: Scaling up Keystroke Biometrics
Apr 19, 2020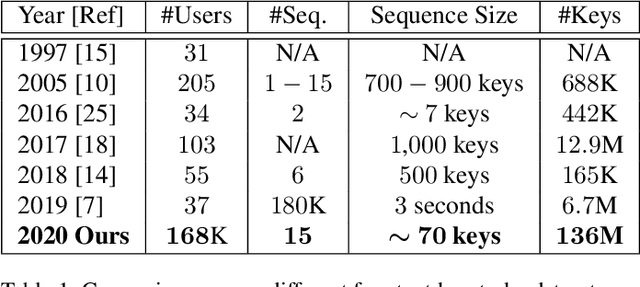
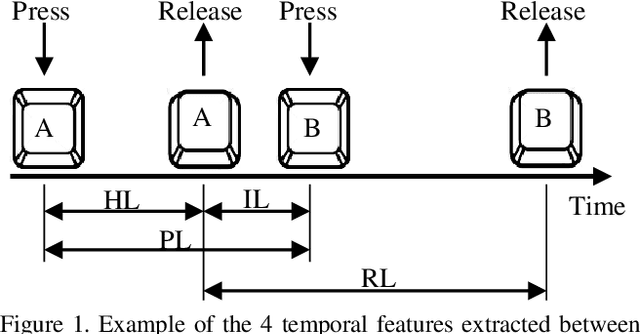
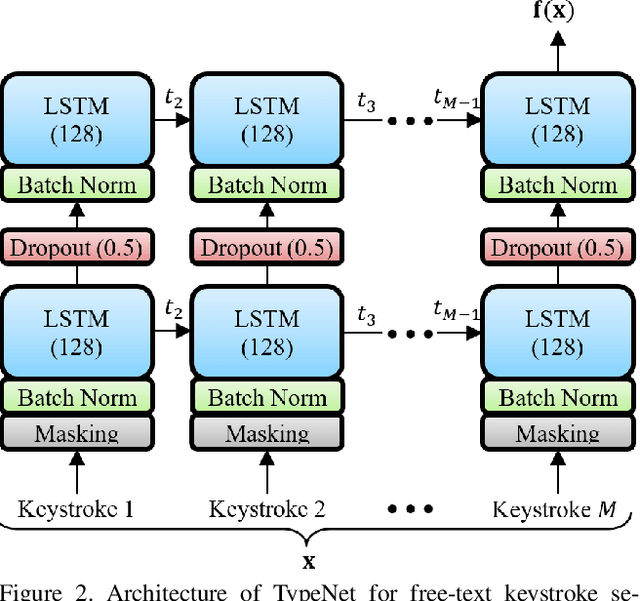
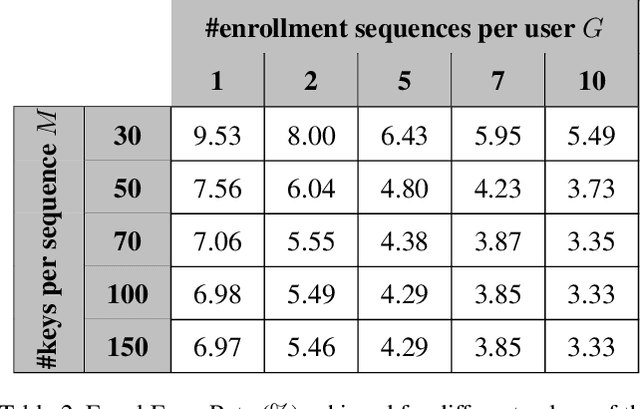
We study the suitability of keystroke dynamics to authenticate 100K users typing free-text. For this, we first analyze to what extent our method based on a Siamese Recurrent Neural Network (RNN) is able to authenticate users when the amount of data per user is scarce, a common scenario in free-text keystroke authentication. With 1K users for testing the network, a population size comparable to previous works, TypeNet obtains an equal error rate of 4.8% using only 5 enrollment sequences and 1 test sequence per user with 50 keystrokes per sequence. Using the same amount of data per user, as the number of test users is scaled up to 100K, the performance in comparison to 1K decays relatively by less than 5%, demonstrating the potential of TypeNet to scale well at large scale number of users. Our experiments are conducted with the Aalto University keystroke database. To the best of our knowledge, this is the largest free-text keystroke database captured with more than 136M keystrokes from 168K users.
MultiLock: Mobile Active Authentication based on Multiple Biometric and Behavioral Patterns
Jan 29, 2019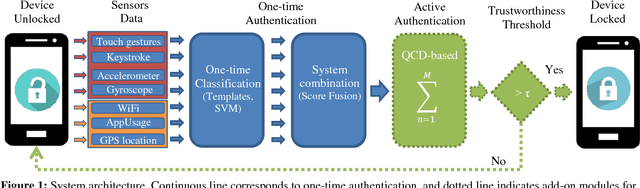
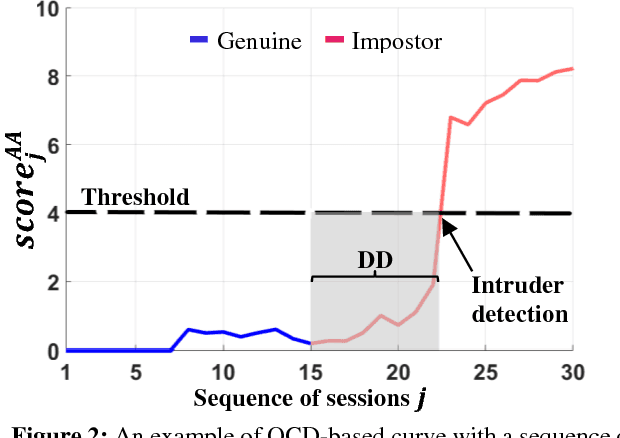
In this paper we evaluate mobile active authentication based on an ensemble of biometrics and behavior-based profiling signals. We consider seven different data channels and their combination. Touch dynamics (touch gestures and keystroking), accelerometer, gyroscope, WiFi, GPS location and app usage are all collected during human-mobile interaction to authenticate the users. We evaluate two approaches: one-time authentication and active authentication. In one-time authentication, we employ the information of all channels available during one session. For active authentication we take advantage of mobile user behavior across multiple sessions by updating a confidence value of the authentication score. Our experiments are conducted on the semi-uncontrolled UMDAA-02 database. This database comprises smartphone sensor signals acquired during natural human-mobile interaction. Our results show that different traits can be complementary and multimodal systems clearly increase the performance with accuracies ranging from 82.2% to 97.1% depending on the authentication scenario.