 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTypeNet: Deep Learning Keystroke Biometrics
Feb 18, 2021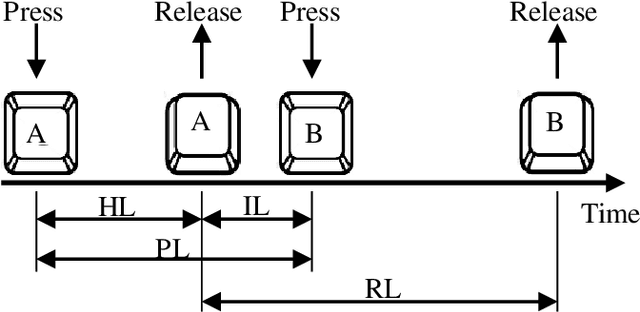
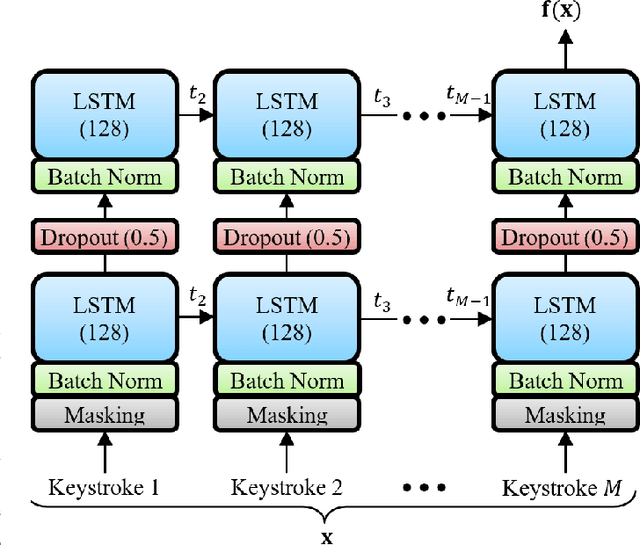
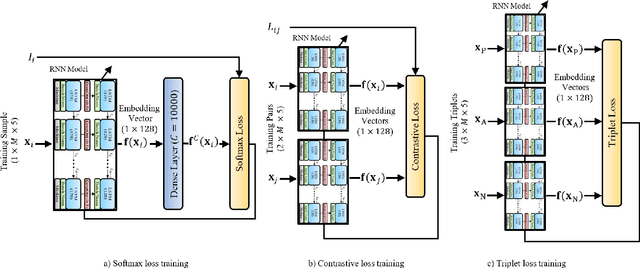
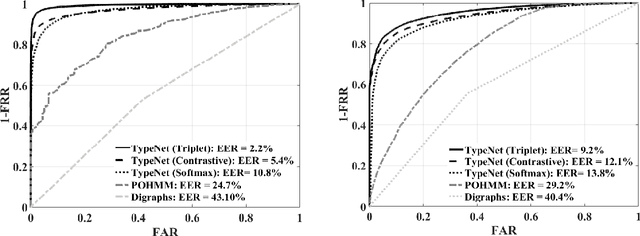
We study the performance of Long Short-Term Memory networks for keystroke biometric authentication at large scale in free-text scenarios. For this we introduce TypeNet, a Recurrent Neural Network (RNN) trained with a moderate number of keystrokes per identity. We evaluate different learning approaches depending on the loss function (softmax, contrastive, and triplet loss), number of gallery samples, length of the keystroke sequences, and device type (physical vs touchscreen keyboard). With 5 gallery sequences and test sequences of length 50, TypeNet achieves state-of-the-art keystroke biometric authentication performance with an Equal Error Rate of 2.2% and 9.2% for physical and touchscreen keyboards, respectively, significantly outperforming previous approaches. Our experiments demonstrate a moderate increase in error with up to 100,000 subjects, demonstrating the potential of TypeNet to operate at an Internet scale. We utilize two Aalto University keystroke databases, one captured on physical keyboards and the second on mobile devices (touchscreen keyboards). To the best of our knowledge, both databases are the largest existing free-text keystroke databases available for research with more than 136 million keystrokes from 168,000 subjects in physical keyboards, and 60,000 subjects with more than 63 million keystrokes acquired on mobile touchscreens.
Keystroke Biometrics in Response to Fake News Propagation in a Global Pandemic
May 18, 2020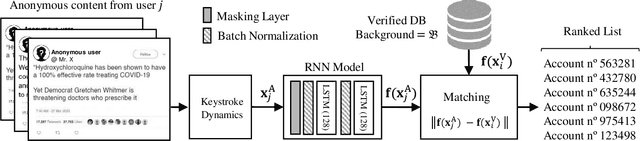
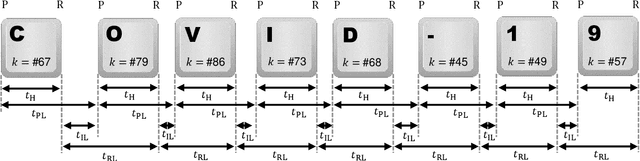
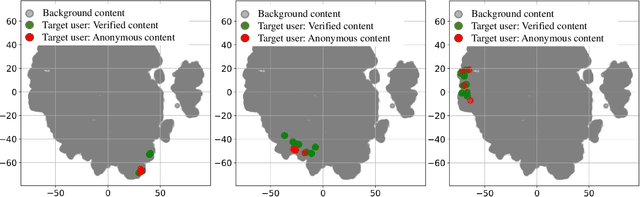
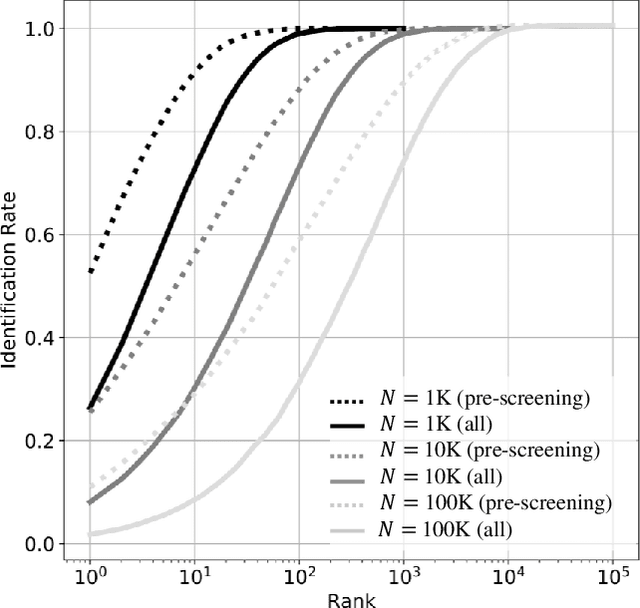
This work proposes and analyzes the use of keystroke biometrics for content de-anonymization. Fake news have become a powerful tool to manipulate public opinion, especially during major events. In particular, the massive spread of fake news during the COVID-19 pandemic has forced governments and companies to fight against missinformation. In this context, the ability to link multiple accounts or profiles that spread such malicious content on the Internet while hiding in anonymity would enable proactive identification and blacklisting. Behavioral biometrics can be powerful tools in this fight. In this work, we have analyzed how the latest advances in keystroke biometric recognition can help to link behavioral typing patterns in experiments involving 100,000 users and more than 1 million typed sequences. Our proposed system is based on Recurrent Neural Networks adapted to the context of content de-anonymization. Assuming the challenge to link the typed content of a target user in a pool of candidate profiles, our results show that keystroke recognition can be used to reduce the list of candidate profiles by more than 90%. In addition, when keystroke is combined with auxiliary data (such as location), our system achieves a Rank-1 identification performance equal to 52.6% and 10.9% for a background candidate list composed of 1K and 100K profiles, respectively.
* arXiv admin note: text overlap with arXiv:2004.03627
TypeNet: Scaling up Keystroke Biometrics
Apr 19, 2020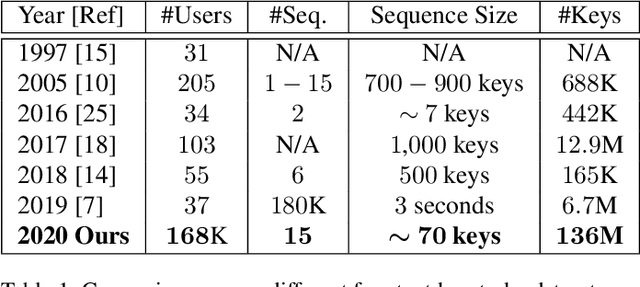
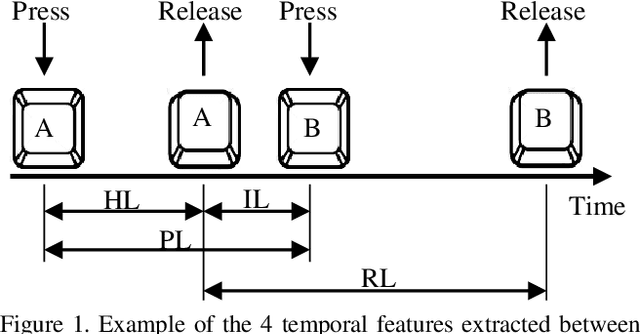
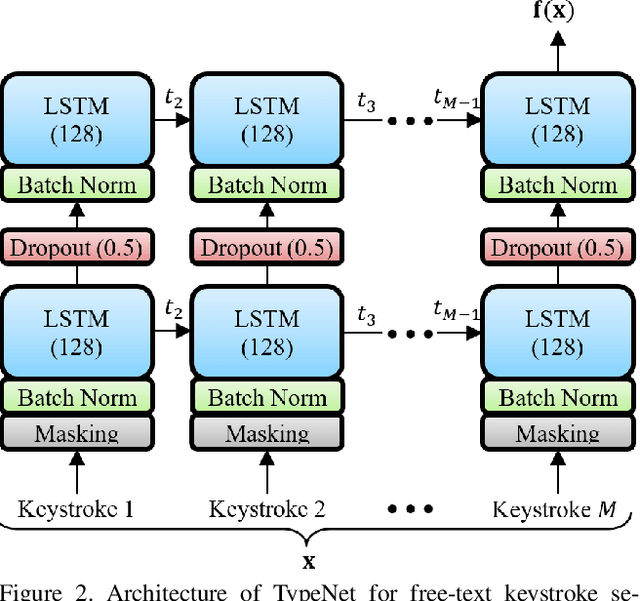
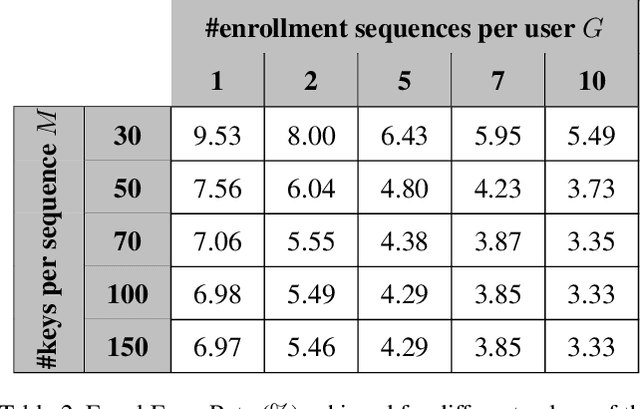
We study the suitability of keystroke dynamics to authenticate 100K users typing free-text. For this, we first analyze to what extent our method based on a Siamese Recurrent Neural Network (RNN) is able to authenticate users when the amount of data per user is scarce, a common scenario in free-text keystroke authentication. With 1K users for testing the network, a population size comparable to previous works, TypeNet obtains an equal error rate of 4.8% using only 5 enrollment sequences and 1 test sequence per user with 50 keystrokes per sequence. Using the same amount of data per user, as the number of test users is scaled up to 100K, the performance in comparison to 1K decays relatively by less than 5%, demonstrating the potential of TypeNet to scale well at large scale number of users. Our experiments are conducted with the Aalto University keystroke database. To the best of our knowledge, this is the largest free-text keystroke database captured with more than 136M keystrokes from 168K users.
Integer Factorization with a Neuromorphic Sieve
Apr 23, 2018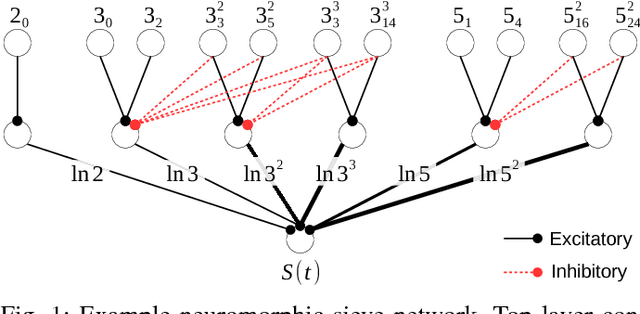

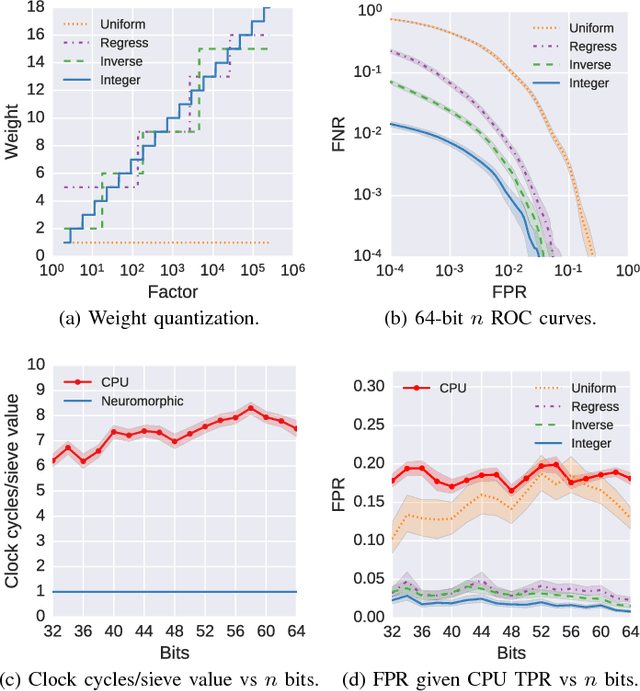
The bound to factor large integers is dominated by the computational effort to discover numbers that are smooth, typically performed by sieving a polynomial sequence. On a von Neumann architecture, sieving has log-log amortized time complexity to check each value for smoothness. This work presents a neuromorphic sieve that achieves a constant time check for smoothness by exploiting two characteristic properties of neuromorphic architectures: constant time synaptic integration and massively parallel computation. The approach is validated by modifying msieve, one of the fastest publicly available integer factorization implementations, to use the IBM Neurosynaptic System (NS1e) as a coprocessor for the sieving stage.
* Fixed typos in equation for modular roots (Section II, par. 6; Section III, par. 2) and phase calculation (Section IV, par 2)
The Partially Observable Hidden Markov Model and its Application to Keystroke Dynamics
Nov 20, 2017
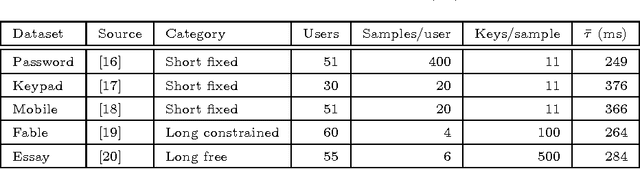

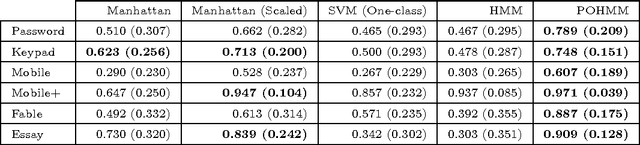
The partially observable hidden Markov model is an extension of the hidden Markov Model in which the hidden state is conditioned on an independent Markov chain. This structure is motivated by the presence of discrete metadata, such as an event type, that may partially reveal the hidden state but itself emanates from a separate process. Such a scenario is encountered in keystroke dynamics whereby a user's typing behavior is dependent on the text that is typed. Under the assumption that the user can be in either an active or passive state of typing, the keyboard key names are event types that partially reveal the hidden state due to the presence of relatively longer time intervals between words and sentences than between letters of a word. Using five public datasets, the proposed model is shown to consistently outperform other anomaly detectors, including the standard HMM, in biometric identification and verification tasks and is generally preferred over the HMM in a Monte Carlo goodness of fit test.