 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReverse Personalization
Dec 28, 2025Recent text-to-image diffusion models have demonstrated remarkable generation of realistic facial images conditioned on textual prompts and human identities, enabling creating personalized facial imagery. However, existing prompt-based methods for removing or modifying identity-specific features rely either on the subject being well-represented in the pre-trained model or require model fine-tuning for specific identities. In this work, we analyze the identity generation process and introduce a reverse personalization framework for face anonymization. Our approach leverages conditional diffusion inversion, allowing direct manipulation of images without using text prompts. To generalize beyond subjects in the model's training data, we incorporate an identity-guided conditioning branch. Unlike prior anonymization methods, which lack control over facial attributes, our framework supports attribute-controllable anonymization. We demonstrate that our method achieves a state-of-the-art balance between identity removal, attribute preservation, and image quality. Source code and data are available at https://github.com/hanweikung/reverse-personalization .
MagicPortrait: Temporally Consistent Face Reenactment with 3D Geometric Guidance
Apr 30, 2025In this paper, we propose a method for video face reenactment that integrates a 3D face parametric model into a latent diffusion framework, aiming to improve shape consistency and motion control in existing video-based face generation approaches. Our approach employs the FLAME (Faces Learned with an Articulated Model and Expressions) model as the 3D face parametric representation, providing a unified framework for modeling face expressions and head pose. This enables precise extraction of detailed face geometry and motion features from driving videos. Specifically, we enhance the latent diffusion model with rich 3D expression and detailed pose information by incorporating depth maps, normal maps, and rendering maps derived from FLAME sequences. A multi-layer face movements fusion module with integrated self-attention mechanisms is used to combine identity and motion latent features within the spatial domain. By utilizing the 3D face parametric model as motion guidance, our method enables parametric alignment of face identity between the reference image and the motion captured from the driving video. Experimental results on benchmark datasets show that our method excels at generating high-quality face animations with precise expression and head pose variation modeling. In addition, it demonstrates strong generalization performance on out-of-domain images. Code is publicly available at https://github.com/weimengting/MagicPortrait.
NullFace: Training-Free Localized Face Anonymization
Mar 11, 2025
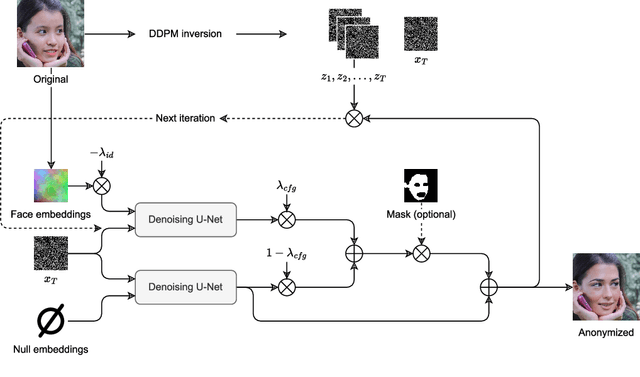


Privacy concerns around ever increasing number of cameras are increasing in today's digital age. Although existing anonymization methods are able to obscure identity information, they often struggle to preserve the utility of the images. In this work, we introduce a training-free method for face anonymization that preserves key non-identity-related attributes. Our approach utilizes a pre-trained text-to-image diffusion model without requiring optimization or training. It begins by inverting the input image to recover its initial noise. The noise is then denoised through an identity-conditioned diffusion process, where modified identity embeddings ensure the anonymized face is distinct from the original identity. Our approach also supports localized anonymization, giving users control over which facial regions are anonymized or kept intact. Comprehensive evaluations against state-of-the-art methods show our approach excels in anonymization, attribute preservation, and image quality. Its flexibility, robustness, and practicality make it well-suited for real-world applications. Code and data can be found at https://github.com/hanweikung/nullface .
Towards Consistent and Controllable Image Synthesis for Face Editing
Feb 04, 2025Current face editing methods mainly rely on GAN-based techniques, but recent focus has shifted to diffusion-based models due to their success in image reconstruction. However, diffusion models still face challenges in manipulating fine-grained attributes and preserving consistency of attributes that should remain unchanged. To address these issues and facilitate more convenient editing of face images, we propose a novel approach that leverages the power of Stable-Diffusion models and crude 3D face models to control the lighting, facial expression and head pose of a portrait photo. We observe that this task essentially involve combinations of target background, identity and different face attributes. We aim to sufficiently disentangle the control of these factors to enable high-quality of face editing. Specifically, our method, coined as RigFace, contains: 1) A Spatial Arrtibute Encoder that provides presise and decoupled conditions of background, pose, expression and lighting; 2) An Identity Encoder that transfers identity features to the denoising UNet of a pre-trained Stable-Diffusion model; 3) An Attribute Rigger that injects those conditions into the denoising UNet. Our model achieves comparable or even superior performance in both identity preservation and photorealism compared to existing face editing models.
MagicFace: High-Fidelity Facial Expression Editing with Action-Unit Control
Jan 04, 2025



We address the problem of facial expression editing by controling the relative variation of facial action-unit (AU) from the same person. This enables us to edit this specific person's expression in a fine-grained, continuous and interpretable manner, while preserving their identity, pose, background and detailed facial attributes. Key to our model, which we dub MagicFace, is a diffusion model conditioned on AU variations and an ID encoder to preserve facial details of high consistency. Specifically, to preserve the facial details with the input identity, we leverage the power of pretrained Stable-Diffusion models and design an ID encoder to merge appearance features through self-attention. To keep background and pose consistency, we introduce an efficient Attribute Controller by explicitly informing the model of current background and pose of the target. By injecting AU variations into a denoising UNet, our model can animate arbitrary identities with various AU combinations, yielding superior results in high-fidelity expression editing compared to other facial expression editing works. Code is publicly available at https://github.com/weimengting/MagicFace.
Face Anonymization Made Simple
Nov 01, 2024



Current face anonymization techniques often depend on identity loss calculated by face recognition models, which can be inaccurate and unreliable. Additionally, many methods require supplementary data such as facial landmarks and masks to guide the synthesis process. In contrast, our approach uses diffusion models with only a reconstruction loss, eliminating the need for facial landmarks or masks while still producing images with intricate, fine-grained details. We validated our results on two public benchmarks through both quantitative and qualitative evaluations. Our model achieves state-of-the-art performance in three key areas: identity anonymization, facial attribute preservation, and image quality. Beyond its primary function of anonymization, our model can also perform face swapping tasks by incorporating an additional facial image as input, demonstrating its versatility and potential for diverse applications. Our code and models are available at https://github.com/hanweikung/face_anon_simple .
Towards Localized Fine-Grained Control for Facial Expression Generation
Jul 25, 2024Generative models have surged in popularity recently due to their ability to produce high-quality images and video. However, steering these models to produce images with specific attributes and precise control remains challenging. Humans, particularly their faces, are central to content generation due to their ability to convey rich expressions and intent. Current generative models mostly generate flat neutral expressions and characterless smiles without authenticity. Other basic expressions like anger are possible, but are limited to the stereotypical expression, while other unconventional facial expressions like doubtful are difficult to reliably generate. In this work, we propose the use of AUs (action units) for facial expression control in face generation. AUs describe individual facial muscle movements based on facial anatomy, allowing precise and localized control over the intensity of facial movements. By combining different action units, we unlock the ability to create unconventional facial expressions that go beyond typical emotional models, enabling nuanced and authentic reactions reflective of real-world expressions. The proposed method can be seamlessly integrated with both text and image prompts using adapters, offering precise and intuitive control of the generated results. Code and dataset are available in {https://github.com/tvaranka/fineface}.
PFStorer: Personalized Face Restoration and Super-Resolution
Mar 13, 2024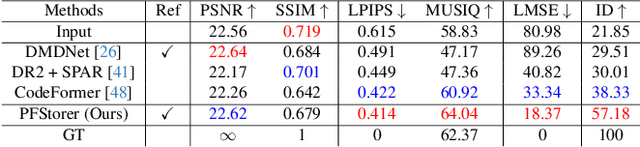
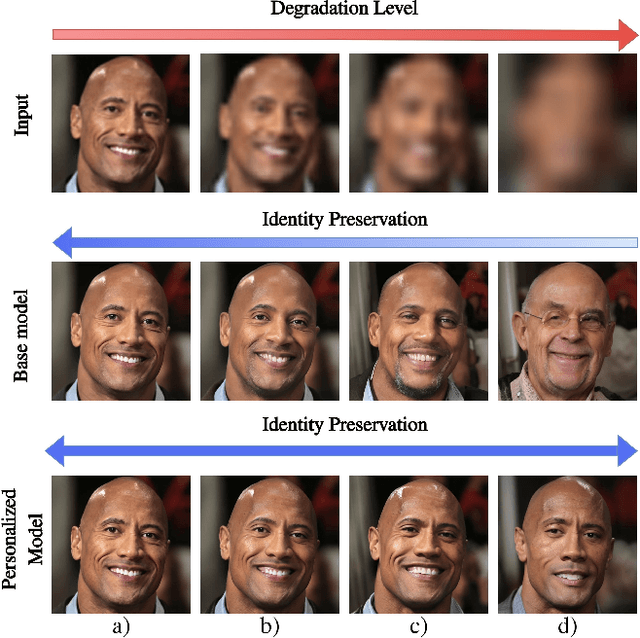
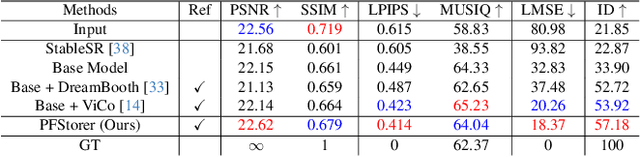
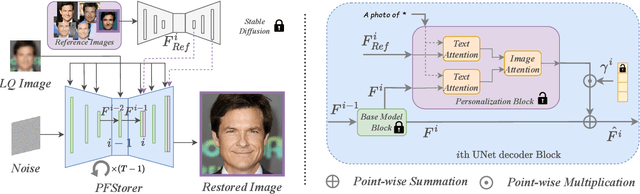
Recent developments in face restoration have achieved remarkable results in producing high-quality and lifelike outputs. The stunning results however often fail to be faithful with respect to the identity of the person as the models lack necessary context. In this paper, we explore the potential of personalized face restoration with diffusion models. In our approach a restoration model is personalized using a few images of the identity, leading to tailored restoration with respect to the identity while retaining fine-grained details. By using independent trainable blocks for personalization, the rich prior of a base restoration model can be exploited to its fullest. To avoid the model relying on parts of identity left in the conditioning low-quality images, a generative regularizer is employed. With a learnable parameter, the model learns to balance between the details generated based on the input image and the degree of personalization. Moreover, we improve the training pipeline of face restoration models to enable an alignment-free approach. We showcase the robust capabilities of our approach in several real-world scenarios with multiple identities, demonstrating our method's ability to generate fine-grained details with faithful restoration. In the user study we evaluate the perceptual quality and faithfulness of the genereated details, with our method being voted best 61% of the time compared to the second best with 25% of the votes.
Data Leakage and Evaluation Issues in Micro-Expression Analysis
Nov 21, 2022


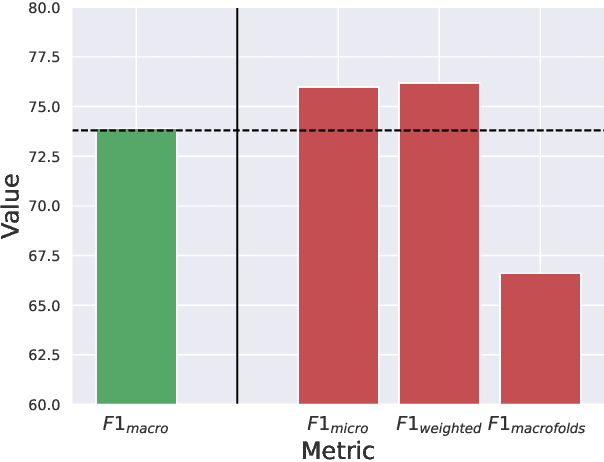
Micro-expressions have drawn increasing interest lately due to various potential applications. The task is, however, difficult as it incorporates many challenges from the fields of computer vision, machine learning and emotional sciences. Due to the spontaneous and subtle characteristics of micro-expressions, the available training and testing data are limited, which make evaluation complex. We show that data leakage and fragmented evaluation protocols are issues among the micro-expression literature. We find that fixing data leaks can drastically reduce model performance, in some cases even making the models perform similarly to a random classifier. To this end, we go through common pitfalls, propose a new standardized evaluation protocol using facial action units with over 2000 micro-expression samples, and provide an open source library that implements the evaluation protocols in a standardized manner. Code will be available in \url{https://github.com/tvaranka/meb}.
Hyperbolic Deep Neural Networks: A Survey
Jan 14, 2021

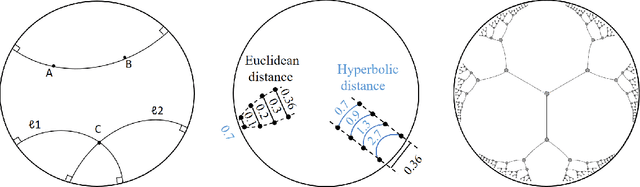
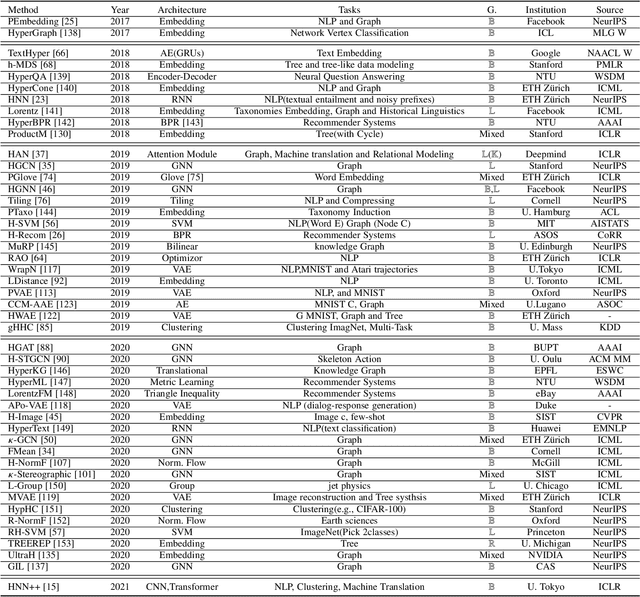
Recently, there has been a raising surge of momentum for deep representation learning in hyperbolic spaces due to theirhigh capacity of modeling data like knowledge graphs or synonym hierarchies, possessing hierarchical structure. We refer it ashyperbolic deep neural network in this paper. Such a hyperbolic neural architecture potentially leads to drastically compact models withmuch more physical interpretability than its counterpart in Euclidean space. To stimulate future research, this paper presents acoherent and comprehensive review of the literature around the neural components in the construction of hyperbolic deep neuralnetworks, as well as the generalization of the leading deep approaches to the Hyperbolic space. It also presents current applicationsaround various machine learning tasks on several publicly available datasets, together with insightful observations and identifying openquestions and promising future directions.