 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePFStorer: Personalized Face Restoration and Super-Resolution
Mar 13, 2024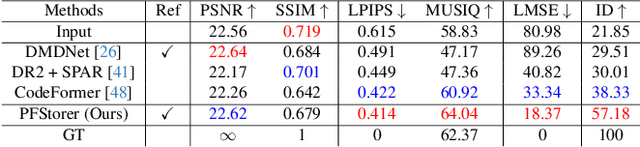
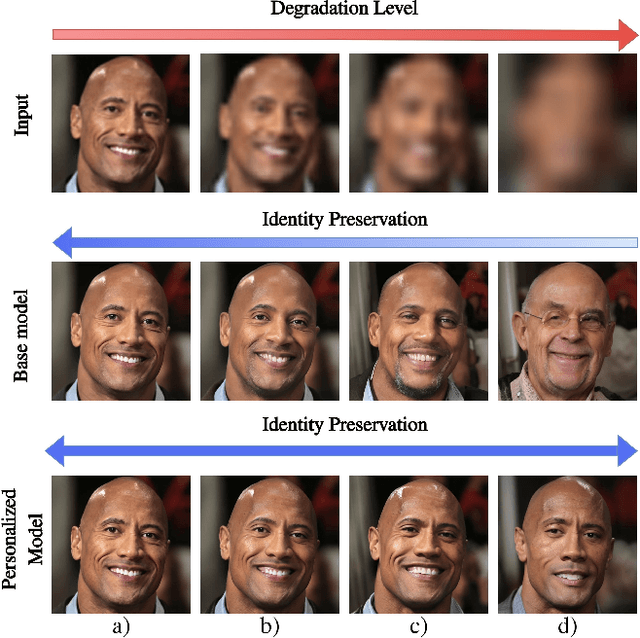
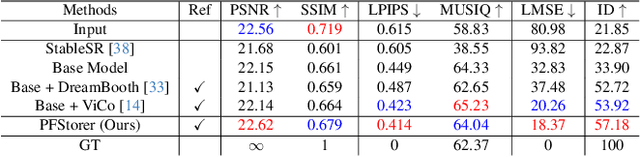
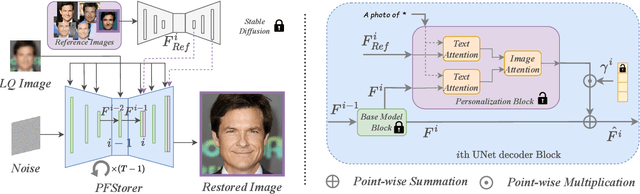
Recent developments in face restoration have achieved remarkable results in producing high-quality and lifelike outputs. The stunning results however often fail to be faithful with respect to the identity of the person as the models lack necessary context. In this paper, we explore the potential of personalized face restoration with diffusion models. In our approach a restoration model is personalized using a few images of the identity, leading to tailored restoration with respect to the identity while retaining fine-grained details. By using independent trainable blocks for personalization, the rich prior of a base restoration model can be exploited to its fullest. To avoid the model relying on parts of identity left in the conditioning low-quality images, a generative regularizer is employed. With a learnable parameter, the model learns to balance between the details generated based on the input image and the degree of personalization. Moreover, we improve the training pipeline of face restoration models to enable an alignment-free approach. We showcase the robust capabilities of our approach in several real-world scenarios with multiple identities, demonstrating our method's ability to generate fine-grained details with faithful restoration. In the user study we evaluate the perceptual quality and faithfulness of the genereated details, with our method being voted best 61% of the time compared to the second best with 25% of the votes.
Power of human-algorithm collaboration in solving combinatorial optimization problems
Jul 25, 2021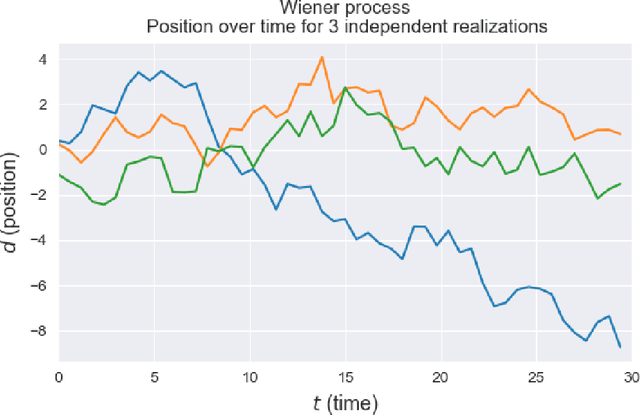
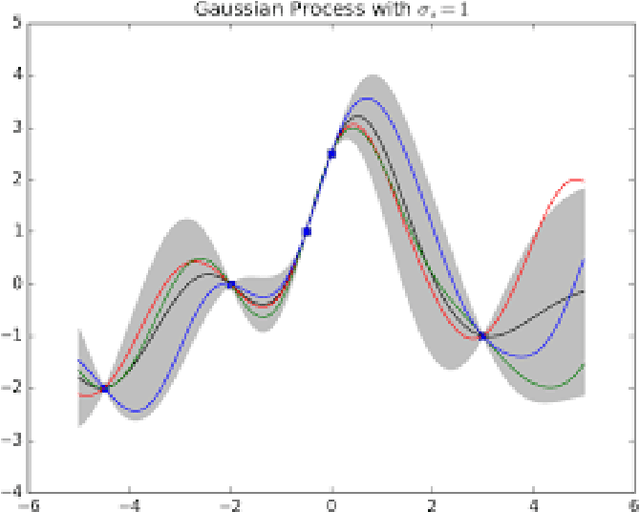
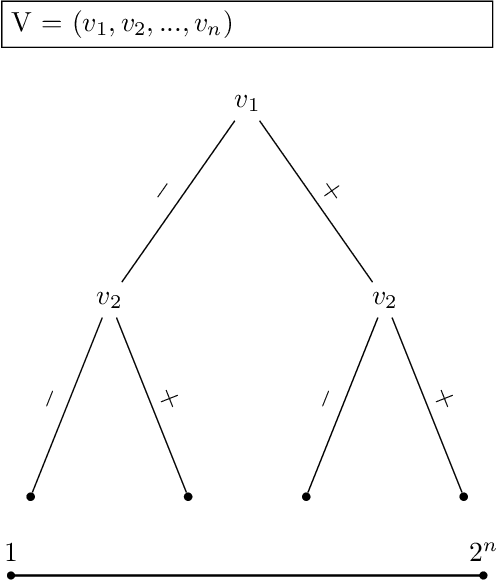
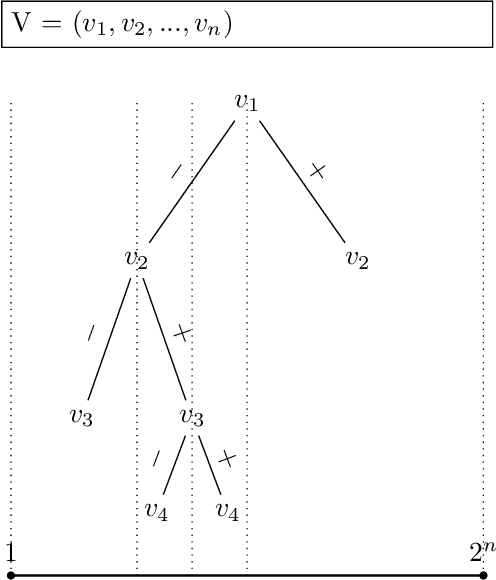
Many combinatorial optimization problems are often considered intractable to solve exactly or by approximation. An example of such problem is maximum clique which -- under standard assumptions in complexity theory -- cannot be solved in sub-exponential time or be approximated within polynomial factor efficiently. We show that if a polynomial time algorithm can query informative Gaussian priors from an expert $poly(n)$ times, then a class of combinatorial optimization problems can be solved efficiently in expectation up to a multiplicative factor $\epsilon$ where $\epsilon$ is arbitrary constant. While our proposed methods are merely theoretical, they cast new light on how to approach solving these problems that have been usually considered intractable.
Teaching Machine Learning in K-12 Computing Education: Potential and Pitfalls
Jun 02, 2021


Over the past decades, numerous practical applications of machine learning techniques have shown the potential of data-driven approaches in a large number of computing fields. Machine learning is increasingly included in computing curricula in higher education, and a quickly growing number of initiatives are expanding it in K-12 computing education, too. As machine learning enters K-12 computing education, understanding how intuition and agency in the context of such systems is developed becomes a key research area. But as schools and teachers are already struggling with integrating traditional computational thinking and traditional artificial intelligence into school curricula, understanding the challenges behind teaching machine learning in K-12 is an even more daunting challenge for computing education research. Despite the central position of machine learning in the field of modern computing, the computing education research body of literature contains remarkably few studies of how people learn to train, test, improve, and deploy machine learning systems. This is especially true of the K-12 curriculum space. This article charts the emerging trajectories in educational practice, theory, and technology related to teaching machine learning in K-12 education. The article situates the existing work in the context of computing education in general, and describes some differences that K-12 computing educators should take into account when facing this challenge. The article focuses on key aspects of the paradigm shift that will be required in order to successfully integrate machine learning into the broader K-12 computing curricula. A crucial step is abandoning the belief that rule-based "traditional" programming is a central aspect and building block in developing next generation computational thinking.