 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAVIDE: Depth-Aware Video Deblurring
Sep 02, 2024Video deblurring aims at recovering sharp details from a sequence of blurry frames. Despite the proliferation of depth sensors in mobile phones and the potential of depth information to guide deblurring, depth-aware deblurring has received only limited attention. In this work, we introduce the 'Depth-Aware VIdeo DEblurring' (DAVIDE) dataset to study the impact of depth information in video deblurring. The dataset comprises synchronized blurred, sharp, and depth videos. We investigate how the depth information should be injected into the existing deep RGB video deblurring models, and propose a strong baseline for depth-aware video deblurring. Our findings reveal the significance of depth information in video deblurring and provide insights into the use cases where depth cues are beneficial. In addition, our results demonstrate that while the depth improves deblurring performance, this effect diminishes when models are provided with a longer temporal context. Project page: https://germanftv.github.io/DAVIDE.github.io/ .
PFStorer: Personalized Face Restoration and Super-Resolution
Mar 13, 2024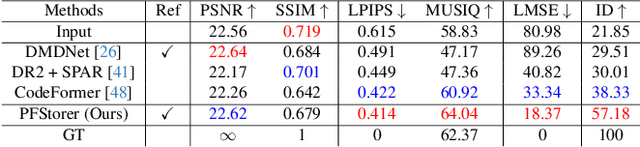
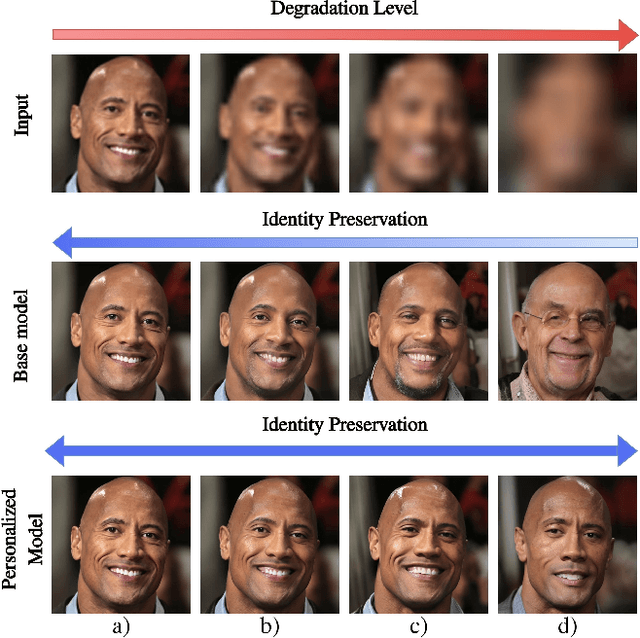
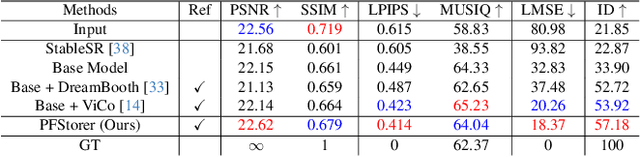
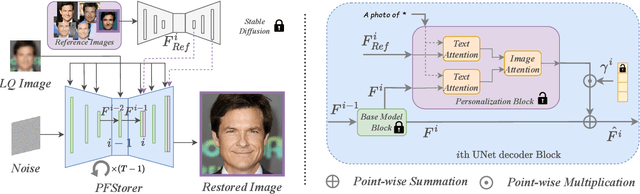
Recent developments in face restoration have achieved remarkable results in producing high-quality and lifelike outputs. The stunning results however often fail to be faithful with respect to the identity of the person as the models lack necessary context. In this paper, we explore the potential of personalized face restoration with diffusion models. In our approach a restoration model is personalized using a few images of the identity, leading to tailored restoration with respect to the identity while retaining fine-grained details. By using independent trainable blocks for personalization, the rich prior of a base restoration model can be exploited to its fullest. To avoid the model relying on parts of identity left in the conditioning low-quality images, a generative regularizer is employed. With a learnable parameter, the model learns to balance between the details generated based on the input image and the degree of personalization. Moreover, we improve the training pipeline of face restoration models to enable an alignment-free approach. We showcase the robust capabilities of our approach in several real-world scenarios with multiple identities, demonstrating our method's ability to generate fine-grained details with faithful restoration. In the user study we evaluate the perceptual quality and faithfulness of the genereated details, with our method being voted best 61% of the time compared to the second best with 25% of the votes.
Positive and negative sampling strategies for self-supervised learning on audio-video data
Feb 05, 2024


In Self-Supervised Learning (SSL), Audio-Visual Correspondence (AVC) is a popular task to learn deep audio and video features from large unlabeled datasets. The key step in AVC is to randomly sample audio and video clips from the dataset and learn to minimize the feature distance between the positive pairs (corresponding audio-video pair) while maximizing the distance between the negative pairs (non-corresponding audio-video pairs). The learnt features are shown to be effective on various downstream tasks. However, these methods achieve subpar performance when the size of the dataset is rather small. In this paper, we investigate the effect of utilizing class label information in the AVC feature learning task. We modified various positive and negative data sampling techniques of SSL based on class label information to investigate the effect on the feature quality. We propose a new sampling approach which we call soft-positive sampling, where the positive pair for one audio sample is not from the exact corresponding video, but from a video of the same class. Experimental results suggest that when the dataset size is small in SSL setup, features learnt through the soft-positive sampling method significantly outperform those from the traditional SSL sampling approaches. This trend holds in both in-domain and out-of-domain downstream tasks, and even outperforms supervised classification. Finally, experiments show that class label information can easily be obtained using a publicly available classifier network and then can be used to boost the SSL performance without adding extra data annotation burden.
Self-supervised learning of audio representations using angular contrastive loss
Nov 10, 2022



In Self-Supervised Learning (SSL), various pretext tasks are designed for learning feature representations through contrastive loss. However, previous studies have shown that this loss is less tolerant to semantically similar samples due to the inherent defect of instance discrimination objectives, which may harm the quality of learned feature embeddings used in downstream tasks. To improve the discriminative ability of feature embeddings in SSL, we propose a new loss function called Angular Contrastive Loss (ACL), a linear combination of angular margin and contrastive loss. ACL improves contrastive learning by explicitly adding an angular margin between positive and negative augmented pairs in SSL. Experimental results show that using ACL for both supervised and unsupervised learning significantly improves performance. We validated our new loss function using the FSDnoisy18k dataset, where we achieved 73.6% and 77.1% accuracy in sound event classification using supervised and self-supervised learning, respectively.
Single Source One Shot Reenactment using Weighted motion From Paired Feature Points
Apr 07, 2021
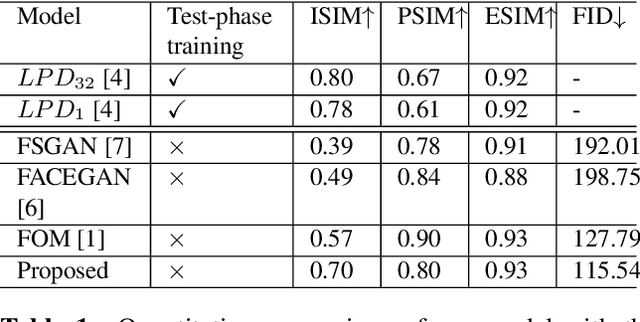
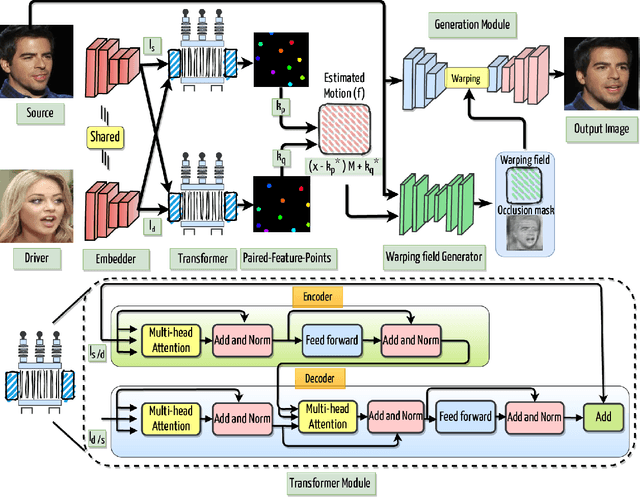
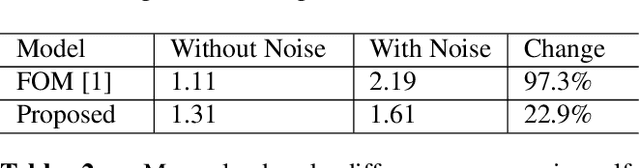
Image reenactment is a task where the target object in the source image imitates the motion represented in the driving image. One of the most common reenactment tasks is face image animation. The major challenge in the current face reenactment approaches is to distinguish between facial motion and identity. For this reason, the previous models struggle to produce high-quality animations if the driving and source identities are different (cross-person reenactment). We propose a new (face) reenactment model that learns shape-independent motion features in a self-supervised setup. The motion is represented using a set of paired feature points extracted from the source and driving images simultaneously. The model is generalised to multiple reenactment tasks including faces and non-face objects using only a single source image. The extensive experiments show that the model faithfully transfers the driving motion to the source while retaining the source identity intact.
FACEGAN: Facial Attribute Controllable rEenactment GAN
Nov 09, 2020


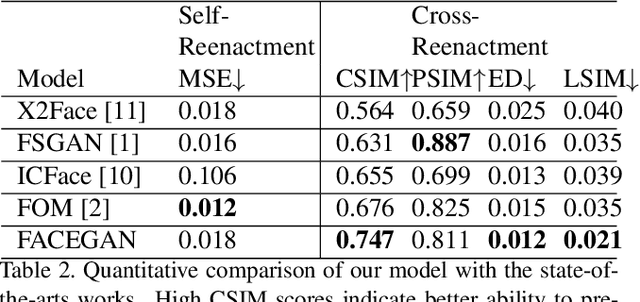
The face reenactment is a popular facial animation method where the person's identity is taken from the source image and the facial motion from the driving image. Recent works have demonstrated high quality results by combining the facial landmark based motion representations with the generative adversarial networks. These models perform best if the source and driving images depict the same person or if the facial structures are otherwise very similar. However, if the identity differs, the driving facial structures leak to the output distorting the reenactment result. We propose a novel Facial Attribute Controllable rEenactment GAN (FACEGAN), which transfers the facial motion from the driving face via the Action Unit (AU) representation. Unlike facial landmarks, the AUs are independent of the facial structure preventing the identity leak. Moreover, AUs provide a human interpretable way to control the reenactment. FACEGAN processes background and face regions separately for optimized output quality. The extensive quantitative and qualitative comparisons show a clear improvement over the state-of-the-art in a single source reenactment task. The results are best illustrated in the reenactment video provided in the supplementary material. The source code will be made available upon publication of the paper.
ICface: Interpretable and Controllable Face Reenactment Using GANs
Apr 03, 2019



This paper presents a generic face animator that is able to control the pose and expressions of a given face image. The animation is driven by human interpretable control signals consisting of head pose angles and the Action Unit (AU) values. The control information can be obtained from multiple sources including external driving videos and manual controls. Due to the interpretable nature of the driving signal, one can easily mix the information between multiple sources (e.g. pose from one image and expression from another) and apply selective post-production editing. The proposed face animator is implemented as a two stage neural network model that is learned in self-supervised manner using a large video collection. The proposed Interpretable and Controllable face reenactment network (ICface) is compared to the state-of-the-art neural network based face animation techniques in multiple tasks. The results indicate that ICface produces better visual quality, while being more versatile than most of the comparison methods. The introduced model could provide a lightweight and easy to use tool for multitude of advanced image and video editing tasks.
Learning image-to-image translation using paired and unpaired training samples
May 08, 2018



Image-to-image translation is a general name for a task where an image from one domain is converted to a corresponding image in another domain, given sufficient training data. Traditionally different approaches have been proposed depending on whether aligned image pairs or two sets of (unaligned) examples from both domains are available for training. While paired training samples might be difficult to obtain, the unpaired setup leads to a highly under-constrained problem and inferior results. In this paper, we propose a new general purpose image-to-image translation model that is able to utilize both paired and unpaired training data simultaneously. We compare our method with two strong baselines and obtain both qualitatively and quantitatively improved results. Our model outperforms the baselines also in the case of purely paired and unpaired training data. To our knowledge, this is the first work to consider such hybrid setup in image-to-image translation.