 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtual camera detection: Catching video injection attacks in remote biometric systems
Dec 11, 2025



Face anti-spoofing (FAS) is a vital component of remote biometric authentication systems based on facial recognition, increasingly used across web-based applications. Among emerging threats, video injection attacks -- facilitated by technologies such as deepfakes and virtual camera software -- pose significant challenges to system integrity. While virtual camera detection (VCD) has shown potential as a countermeasure, existing literature offers limited insight into its practical implementation and evaluation. This study introduces a machine learning-based approach to VCD, with a focus on its design and validation. The model is trained on metadata collected during sessions with authentic users. Empirical results demonstrate its effectiveness in identifying video injection attempts and reducing the risk of malicious users bypassing FAS systems.
KVC-onGoing: Keystroke Verification Challenge
Dec 29, 2024



This article presents the Keystroke Verification Challenge - onGoing (KVC-onGoing), on which researchers can easily benchmark their systems in a common platform using large-scale public databases, the Aalto University Keystroke databases, and a standard experimental protocol. The keystroke data consist of tweet-long sequences of variable transcript text from over 185,000 subjects, acquired through desktop and mobile keyboards simulating real-life conditions. The results on the evaluation set of KVC-onGoing have proved the high discriminative power of keystroke dynamics, reaching values as low as 3.33% of Equal Error Rate (EER) and 11.96% of False Non-Match Rate (FNMR) @1% False Match Rate (FMR) in the desktop scenario, and 3.61% of EER and 17.44% of FNMR @1% at FMR in the mobile scenario, significantly improving previous state-of-the-art results. Concerning demographic fairness, the analyzed scores reflect the subjects' age and gender to various extents, not negligible in a few cases. The framework runs on CodaLab.
IEEE BigData 2023 Keystroke Verification Challenge (KVC)
Jan 29, 2024This paper describes the results of the IEEE BigData 2023 Keystroke Verification Challenge (KVC), that considers the biometric verification performance of Keystroke Dynamics (KD), captured as tweet-long sequences of variable transcript text from over 185,000 subjects. The data are obtained from two of the largest public databases of KD up to date, the Aalto Desktop and Mobile Keystroke Databases, guaranteeing a minimum amount of data per subject, age and gender annotations, absence of corrupted data, and avoiding excessively unbalanced subject distributions with respect to the considered demographic attributes. Several neural architectures were proposed by the participants, leading to global Equal Error Rates (EERs) as low as 3.33% and 3.61% achieved by the best team respectively in the desktop and mobile scenario, outperforming the current state of the art biometric verification performance for KD. Hosted on CodaLab, the KVC will be made ongoing to represent a useful tool for the research community to compare different approaches under the same experimental conditions and to deepen the knowledge of the field.
Achieving Better Kinship Recognition Through Better Baseline
Jun 21, 2020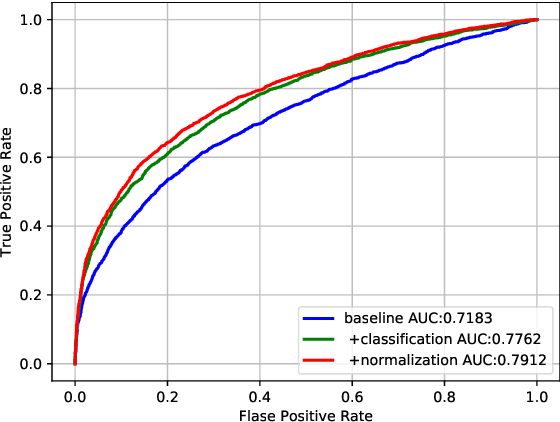

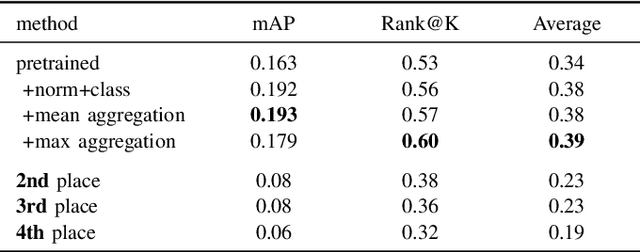
Recognizing blood relations using face images can be seen as an application of face recognition systems with additional restrictions. These restrictions proved to be difficult to deal with, however, recent advancements in face verification show that there is still much to gain using more data and novel ideas. As a result face recognition is a great source domain from which we can transfer the knowledge to get better performance in kinship recognition as a source domain. We present a new baseline for an automatic kinship recognition task and relatives search based on RetinaFace[1] for face registration and ArcFace[2] face verification model. With the approach described above as the foundation, we constructed a pipeline that achieved state-of-the-art performance on two tracks in the recent Recognizing Families In the Wild Data Challenge.