 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrated Face Analytics Networks through Cross-Dataset Hybrid Training
Nov 16, 2017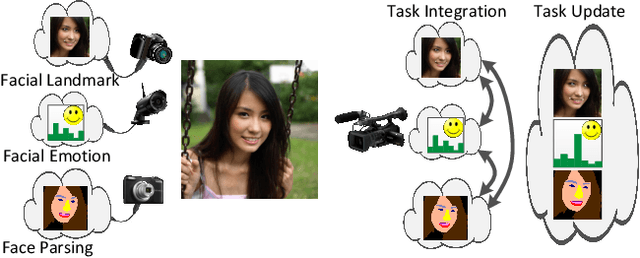
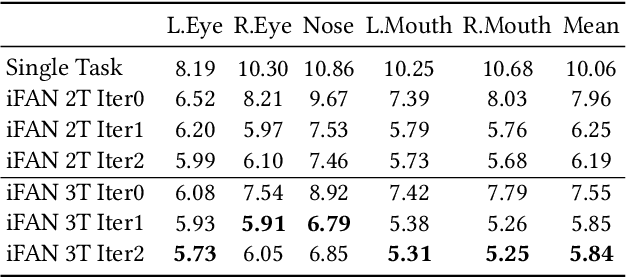
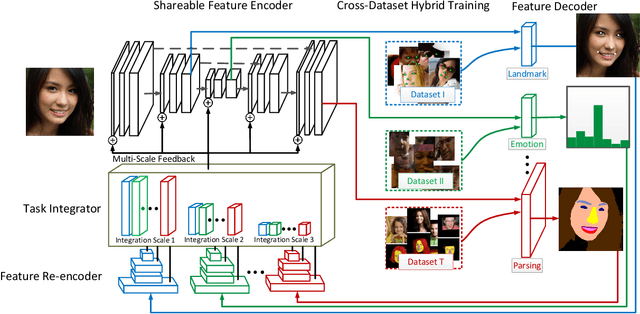
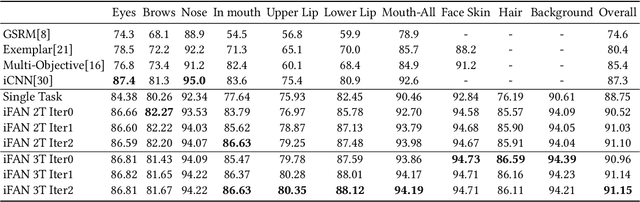
Face analytics benefits many multimedia applications. It consists of a number of tasks, such as facial emotion recognition and face parsing, and most existing approaches generally treat these tasks independently, which limits their deployment in real scenarios. In this paper we propose an integrated Face Analytics Network (iFAN), which is able to perform multiple tasks jointly for face analytics with a novel carefully designed network architecture to fully facilitate the informative interaction among different tasks. The proposed integrated network explicitly models the interactions between tasks so that the correlations between tasks can be fully exploited for performance boost. In addition, to solve the bottleneck of the absence of datasets with comprehensive training data for various tasks, we propose a novel cross-dataset hybrid training strategy. It allows "plug-in and play" of multiple datasets annotated for different tasks without the requirement of a fully labeled common dataset for all the tasks. We experimentally show that the proposed iFAN achieves state-of-the-art performance on multiple face analytics tasks using a single integrated model. Specifically, iFAN achieves an overall F-score of 91.15% on the Helen dataset for face parsing, a normalized mean error of 5.81% on the MTFL dataset for facial landmark localization and an accuracy of 45.73% on the BNU dataset for emotion recognition with a single model.
Deep Recurrent Regression for Facial Landmark Detection
Oct 31, 2016


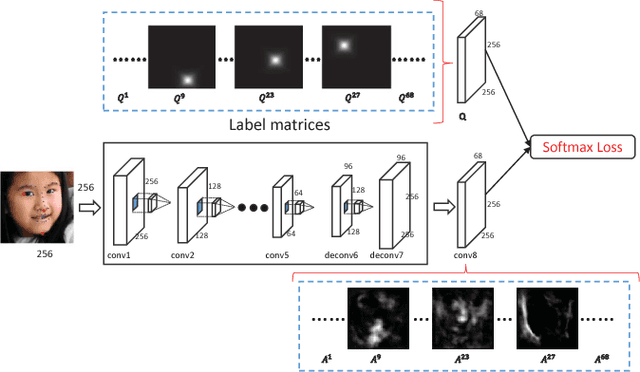
We propose a novel end-to-end deep architecture for face landmark detection, based on a deep convolutional and deconvolutional network followed by carefully designed recurrent network structures. The pipeline of this architecture consists of three parts. Through the first part, we encode an input face image to resolution-preserved deconvolutional feature maps via a deep network with stacked convolutional and deconvolutional layers. Then, in the second part, we estimate the initial coordinates of the facial key points by an additional convolutional layer on top of these deconvolutional feature maps. In the last part, by using the deconvolutional feature maps and the initial facial key points as input, we refine the coordinates of the facial key points by a recurrent network that consists of multiple Long-Short Term Memory (LSTM) components. Extensive evaluations on several benchmark datasets show that the proposed deep architecture has superior performance against the state-of-the-art methods.