 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShotVL: Human-Centric Highlight Frame Retrieval via Language Queries
Dec 17, 2024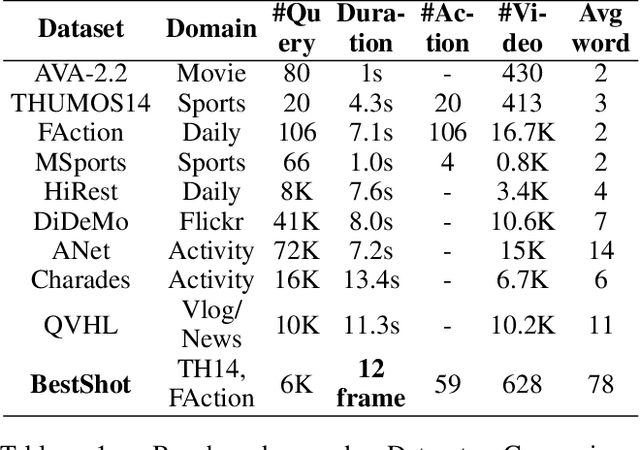

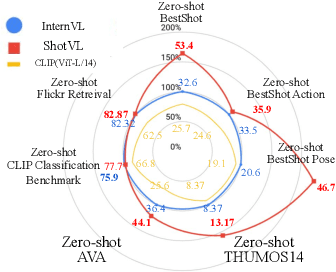
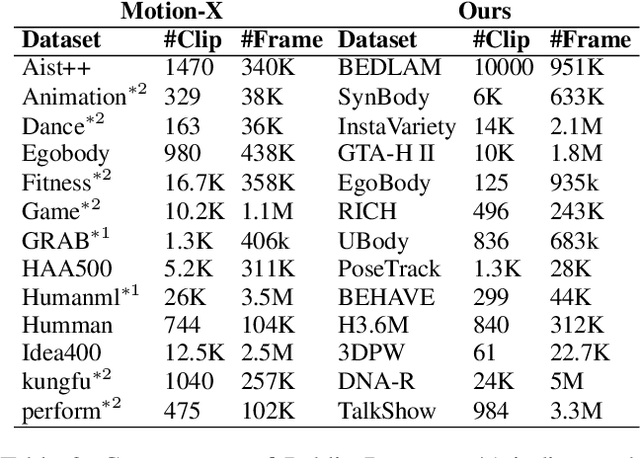
Existing works on human-centric video understanding typically focus on analyzing specific moment or entire videos. However, many applications require higher precision at the frame level. In this work, we propose a novel task, BestShot, which aims to locate highlight frames within human-centric videos via language queries. This task demands not only a deep semantic comprehension of human actions but also precise temporal localization. To support this task, we introduce the BestShot Benchmark. %The benchmark is meticulously constructed by combining human detection and tracking, potential frame selection based on human judgment, and detailed textual descriptions crafted by human input to ensure precision. The benchmark is meticulously constructed by combining human-annotated highlight frames, detailed textual descriptions and duration labeling. These descriptions encompass three critical elements: (1) Visual content; (2) Fine-grained action; and (3) Human Pose Description. Together, these elements provide the necessary precision to identify the exact highlight frames in videos. To tackle this problem, we have collected two distinct datasets: (i) ShotGPT4o Dataset, which is algorithmically generated by GPT-4o and (ii) Image-SMPLText Dataset, a dataset with large-scale and accurate per-frame pose description leveraging PoseScript and existing pose estimation datasets. Based on these datasets, we present a strong baseline model, ShotVL, fine-tuned from InternVL, specifically for BestShot. We highlight the impressive zero-shot capabilities of our model and offer comparative analyses with existing SOTA models. ShotVL demonstrates a significant 52% improvement over InternVL on the BestShot Benchmark and a notable 57% improvement on the THUMOS14 Benchmark, all while maintaining the SOTA performance in general image classification and retrieval.