 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoPE-VideoLM: Codec Primitives For Efficient Video Language Models
Feb 13, 2026Video Language Models (VideoLMs) empower AI systems to understand temporal dynamics in videos. To fit to the maximum context window constraint, current methods use keyframe sampling which can miss both macro-level events and micro-level details due to the sparse temporal coverage. Furthermore, processing full images and their tokens for each frame incurs substantial computational overhead. To address these limitations, we propose to leverage video codec primitives (specifically motion vectors and residuals) which natively encode video redundancy and sparsity without requiring expensive full-image encoding for most frames. To this end, we introduce lightweight transformer-based encoders that aggregate codec primitives and align their representations with image encoder embeddings through a pre-training strategy that accelerates convergence during end-to-end fine-tuning. Our approach reduces the time-to-first-token by up to $86\%$ and token usage by up to $93\%$ compared to standard VideoLMs. Moreover, by varying the keyframe and codec primitive densities we are able to maintain or exceed performance on $14$ diverse video understanding benchmarks spanning general question answering, temporal reasoning, long-form understanding, and spatial scene understanding.
Relative Pose Estimation through Affine Corrections of Monocular Depth Priors
Jan 09, 2025



Monocular depth estimation (MDE) models have undergone significant advancements over recent years. Many MDE models aim to predict affine-invariant relative depth from monocular images, while recent developments in large-scale training and vision foundation models enable reasonable estimation of metric (absolute) depth. However, effectively leveraging these predictions for geometric vision tasks, in particular relative pose estimation, remains relatively under explored. While depths provide rich constraints for cross-view image alignment, the intrinsic noise and ambiguity from the monocular depth priors present practical challenges to improving upon classic keypoint-based solutions. In this paper, we develop three solvers for relative pose estimation that explicitly account for independent affine (scale and shift) ambiguities, covering both calibrated and uncalibrated conditions. We further propose a hybrid estimation pipeline that combines our proposed solvers with classic point-based solvers and epipolar constraints. We find that the affine correction modeling is beneficial to not only the relative depth priors but also, surprisingly, the ``metric" ones. Results across multiple datasets demonstrate large improvements of our approach over classic keypoint-based baselines and PnP-based solutions, under both calibrated and uncalibrated setups. We also show that our method improves consistently with different feature matchers and MDE models, and can further benefit from very recent advances on both modules. Code is available at https://github.com/MarkYu98/madpose.
Robust Incremental Structure-from-Motion with Hybrid Features
Sep 29, 2024


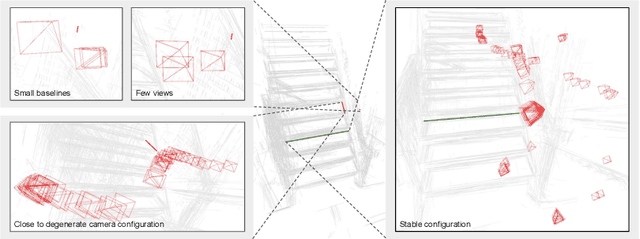
Structure-from-Motion (SfM) has become a ubiquitous tool for camera calibration and scene reconstruction with many downstream applications in computer vision and beyond. While the state-of-the-art SfM pipelines have reached a high level of maturity in well-textured and well-configured scenes over the last decades, they still fall short of robustly solving the SfM problem in challenging scenarios. In particular, weakly textured scenes and poorly constrained configurations oftentimes cause catastrophic failures or large errors for the primarily keypoint-based pipelines. In these scenarios, line segments are often abundant and can offer complementary geometric constraints. Their large spatial extent and typically structured configurations lead to stronger geometric constraints as compared to traditional keypoint-based methods. In this work, we introduce an incremental SfM system that, in addition to points, leverages lines and their structured geometric relations. Our technical contributions span the entire pipeline (mapping, triangulation, registration) and we integrate these into a comprehensive end-to-end SfM system that we share as an open-source software with the community. We also present the first analytical method to propagate uncertainties for 3D optimized lines via sensitivity analysis. Experiments show that our system is consistently more robust and accurate compared to the widely used point-based state of the art in SfM -- achieving richer maps and more precise camera registrations, especially under challenging conditions. In addition, our uncertainty-aware localization module alone is able to consistently improve over the state of the art under both point-alone and hybrid setups.
3D Neural Edge Reconstruction
May 29, 2024Real-world objects and environments are predominantly composed of edge features, including straight lines and curves. Such edges are crucial elements for various applications, such as CAD modeling, surface meshing, lane mapping, etc. However, existing traditional methods only prioritize lines over curves for simplicity in geometric modeling. To this end, we introduce EMAP, a new method for learning 3D edge representations with a focus on both lines and curves. Our method implicitly encodes 3D edge distance and direction in Unsigned Distance Functions (UDF) from multi-view edge maps. On top of this neural representation, we propose an edge extraction algorithm that robustly abstracts parametric 3D edges from the inferred edge points and their directions. Comprehensive evaluations demonstrate that our method achieves better 3D edge reconstruction on multiple challenging datasets. We further show that our learned UDF field enhances neural surface reconstruction by capturing more details.
Long-Term Invariant Local Features via Implicit Cross-Domain Correspondences
Nov 06, 2023



Modern learning-based visual feature extraction networks perform well in intra-domain localization, however, their performance significantly declines when image pairs are captured across long-term visual domain variations, such as different seasonal and daytime variations. In this paper, our first contribution is a benchmark to investigate the performance impact of long-term variations on visual localization. We conduct a thorough analysis of the performance of current state-of-the-art feature extraction networks under various domain changes and find a significant performance gap between intra- and cross-domain localization. We investigate different methods to close this gap by improving the supervision of modern feature extractor networks. We propose a novel data-centric method, Implicit Cross-Domain Correspondences (iCDC). iCDC represents the same environment with multiple Neural Radiance Fields, each fitting the scene under individual visual domains. It utilizes the underlying 3D representations to generate accurate correspondences across different long-term visual conditions. Our proposed method enhances cross-domain localization performance, significantly reducing the performance gap. When evaluated on popular long-term localization benchmarks, our trained networks consistently outperform existing methods. This work serves as a substantial stride toward more robust visual localization pipelines for long-term deployments, and opens up research avenues in the development of long-term invariant descriptors.
Handbook on Leveraging Lines for Two-View Relative Pose Estimation
Sep 27, 2023



We propose an approach for estimating the relative pose between calibrated image pairs by jointly exploiting points, lines, and their coincidences in a hybrid manner. We investigate all possible configurations where these data modalities can be used together and review the minimal solvers available in the literature. Our hybrid framework combines the advantages of all configurations, enabling robust and accurate estimation in challenging environments. In addition, we design a method for jointly estimating multiple vanishing point correspondences in two images, and a bundle adjustment that considers all relevant data modalities. Experiments on various indoor and outdoor datasets show that our approach outperforms point-based methods, improving AUC@10$^\circ$ by 1-7 points while running at comparable speeds. The source code of the solvers and hybrid framework will be made public.
Vanishing Point Estimation in Uncalibrated Images with Prior Gravity Direction
Aug 21, 2023



We tackle the problem of estimating a Manhattan frame, i.e. three orthogonal vanishing points, and the unknown focal length of the camera, leveraging a prior vertical direction. The direction can come from an Inertial Measurement Unit that is a standard component of recent consumer devices, e.g., smartphones. We provide an exhaustive analysis of minimal line configurations and derive two new 2-line solvers, one of which does not suffer from singularities affecting existing solvers. Additionally, we design a new non-minimal method, running on an arbitrary number of lines, to boost the performance in local optimization. Combining all solvers in a hybrid robust estimator, our method achieves increased accuracy even with a rough prior. Experiments on synthetic and real-world datasets demonstrate the superior accuracy of our method compared to the state of the art, while having comparable runtimes. We further demonstrate the applicability of our solvers for relative rotation estimation. The code is available at https://github.com/cvg/VP-Estimation-with-Prior-Gravity.
GlueStick: Robust Image Matching by Sticking Points and Lines Together
Apr 04, 2023Line segments are powerful features complementary to points. They offer structural cues, robust to drastic viewpoint and illumination changes, and can be present even in texture-less areas. However, describing and matching them is more challenging compared to points due to partial occlusions, lack of texture, or repetitiveness. This paper introduces a new matching paradigm, where points, lines, and their descriptors are unified into a single wireframe structure. We propose GlueStick, a deep matching Graph Neural Network (GNN) that takes two wireframes from different images and leverages the connectivity information between nodes to better glue them together. In addition to the increased efficiency brought by the joint matching, we also demonstrate a large boost of performance when leveraging the complementary nature of these two features in a single architecture. We show that our matching strategy outperforms the state-of-the-art approaches independently matching line segments and points for a wide variety of datasets and tasks. The code is available at https://github.com/cvg/GlueStick.
3D Line Mapping Revisited
Mar 30, 2023In contrast to sparse keypoints, a handful of line segments can concisely encode the high-level scene layout, as they often delineate the main structural elements. In addition to offering strong geometric cues, they are also omnipresent in urban landscapes and indoor scenes. Despite their apparent advantages, current line-based reconstruction methods are far behind their point-based counterparts. In this paper we aim to close the gap by introducing LIMAP, a library for 3D line mapping that robustly and efficiently creates 3D line maps from multi-view imagery. This is achieved through revisiting the degeneracy problem of line triangulation, carefully crafted scoring and track building, and exploiting structural priors such as line coincidence, parallelism, and orthogonality. Our code integrates seamlessly with existing point-based Structure-from-Motion methods and can leverage their 3D points to further improve the line reconstruction. Furthermore, as a byproduct, the method is able to recover 3D association graphs between lines and points / vanishing points (VPs). In thorough experiments, we show that LIMAP significantly outperforms existing approaches for 3D line mapping. Our robust 3D line maps also open up new research directions. We show two example applications: visual localization and bundle adjustment, where integrating lines alongside points yields the best results. Code is available at https://github.com/cvg/limap.
DeepLSD: Line Segment Detection and Refinement with Deep Image Gradients
Dec 15, 2022



Line segments are ubiquitous in our human-made world and are increasingly used in vision tasks. They are complementary to feature points thanks to their spatial extent and the structural information they provide. Traditional line detectors based on the image gradient are extremely fast and accurate, but lack robustness in noisy images and challenging conditions. Their learned counterparts are more repeatable and can handle challenging images, but at the cost of a lower accuracy and a bias towards wireframe lines. We propose to combine traditional and learned approaches to get the best of both worlds: an accurate and robust line detector that can be trained in the wild without ground truth lines. Our new line segment detector, DeepLSD, processes images with a deep network to generate a line attraction field, before converting it to a surrogate image gradient magnitude and angle, which is then fed to any existing handcrafted line detector. Additionally, we propose a new optimization tool to refine line segments based on the attraction field and vanishing points. This refinement improves the accuracy of current deep detectors by a large margin. We demonstrate the performance of our method on low-level line detection metrics, as well as on several downstream tasks using multiple challenging datasets. The source code and models are available at https://github.com/cvg/DeepLSD.