 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Data Augmentation Through Deep Relighting
Oct 26, 2021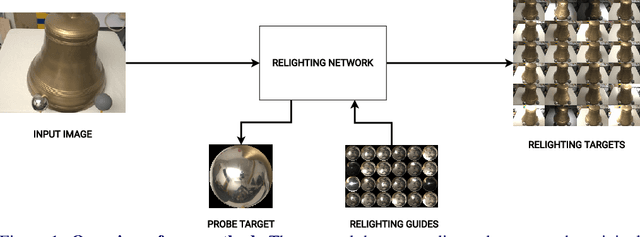
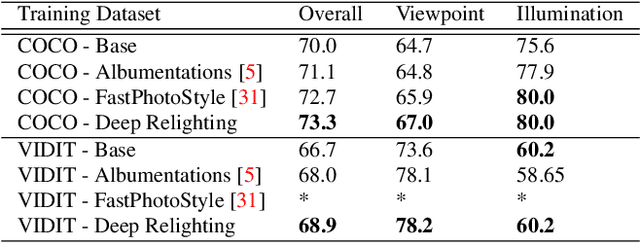
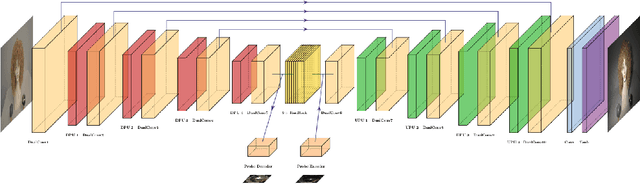

At the heart of the success of deep learning is the quality of the data. Through data augmentation, one can train models with better generalization capabilities and thus achieve greater results in their field of interest. In this work, we explore how to augment a varied set of image datasets through relighting so as to improve the ability of existing models to be invariant to illumination changes, namely for learned descriptors. We develop a tool, based on an encoder-decoder network, that is able to quickly generate multiple variations of the illumination of various input scenes whilst also allowing the user to define parameters such as the angle of incidence and intensity. We demonstrate that by training models on datasets that have been augmented with our pipeline, it is possible to achieve higher performance on localization benchmarks.
Border-SegGCN: Improving Semantic Segmentation by Refining the Border Outline using Graph Convolutional Network
Sep 11, 2021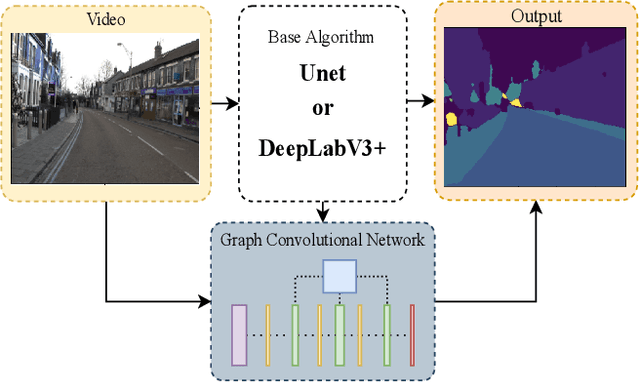
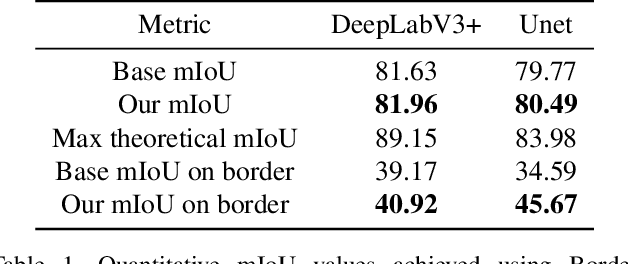
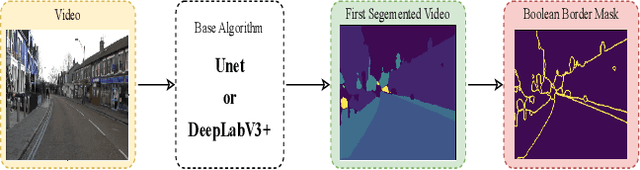
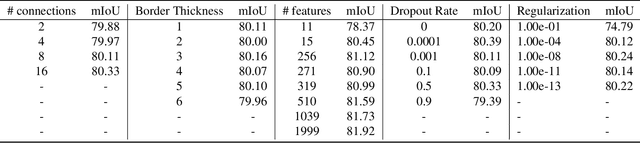
We present Border-SegGCN, a novel architecture to improve semantic segmentation by refining the border outline using graph convolutional networks (GCN). The semantic segmentation network such as Unet or DeepLabV3+ is used as a base network to have pre-segmented output. This output is converted into a graphical structure and fed into the GCN to improve the border pixel prediction of the pre-segmented output. We explored and studied the factors such as border thickness, number of edges for a node, and the number of features to be fed into the GCN by performing experiments. We demonstrate the effectiveness of the Border-SegGCN on the CamVid and Carla dataset, achieving a test set performance of 81.96% without any post-processing on CamVid dataset. It is higher than the reported state of the art mIoU achieved on CamVid dataset by 0.404%