 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBorder-SegGCN: Improving Semantic Segmentation by Refining the Border Outline using Graph Convolutional Network
Sep 11, 2021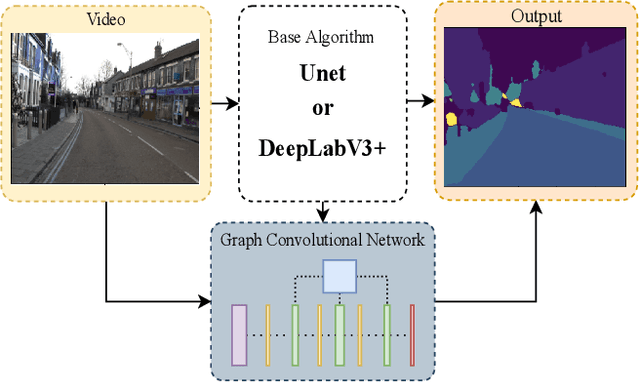
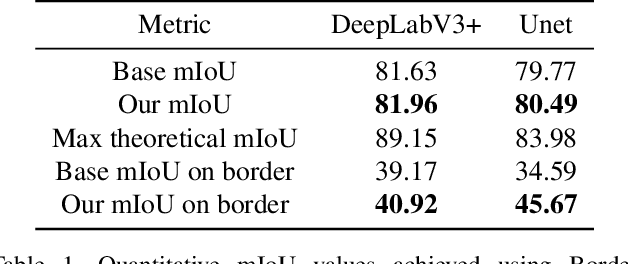
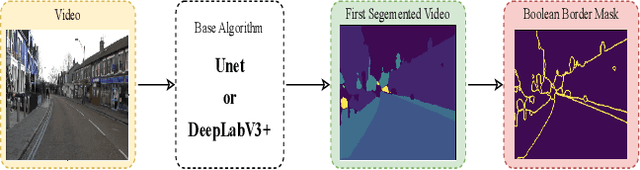
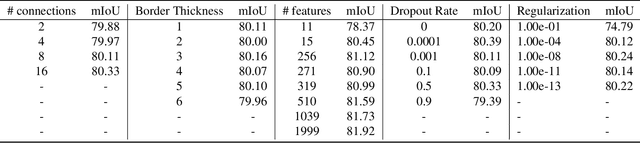
We present Border-SegGCN, a novel architecture to improve semantic segmentation by refining the border outline using graph convolutional networks (GCN). The semantic segmentation network such as Unet or DeepLabV3+ is used as a base network to have pre-segmented output. This output is converted into a graphical structure and fed into the GCN to improve the border pixel prediction of the pre-segmented output. We explored and studied the factors such as border thickness, number of edges for a node, and the number of features to be fed into the GCN by performing experiments. We demonstrate the effectiveness of the Border-SegGCN on the CamVid and Carla dataset, achieving a test set performance of 81.96% without any post-processing on CamVid dataset. It is higher than the reported state of the art mIoU achieved on CamVid dataset by 0.404%
BGT-Net: Bidirectional GRU Transformer Network for Scene Graph Generation
Sep 11, 2021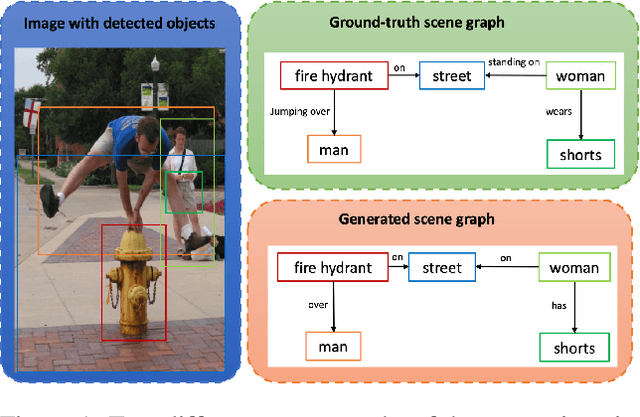
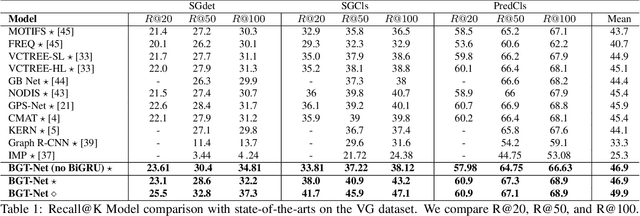
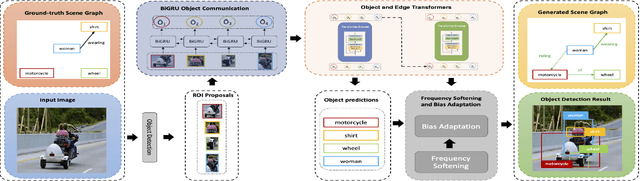

Scene graphs are nodes and edges consisting of objects and object-object relationships, respectively. Scene graph generation (SGG) aims to identify the objects and their relationships. We propose a bidirectional GRU (BiGRU) transformer network (BGT-Net) for the scene graph generation for images. This model implements novel object-object communication to enhance the object information using a BiGRU layer. Thus, the information of all objects in the image is available for the other objects, which can be leveraged later in the object prediction step. This object information is used in a transformer encoder to predict the object class as well as to create object-specific edge information via the use of another transformer encoder. To handle the dataset bias induced by the long-tailed relationship distribution, softening with a log-softmax function and adding a bias adaptation term to regulate the bias for every relation prediction individually showed to be an effective approach. We conducted an elaborate study on experiments and ablations using open-source datasets, i.e., Visual Genome, Open-Images, and Visual Relationship Detection datasets, demonstrating the effectiveness of the proposed model over state of the art.
* 8 pages, 7 supplementary pages
Recognition and Localisation of Pointing Gestures using a RGB-D Camera
Jan 10, 2020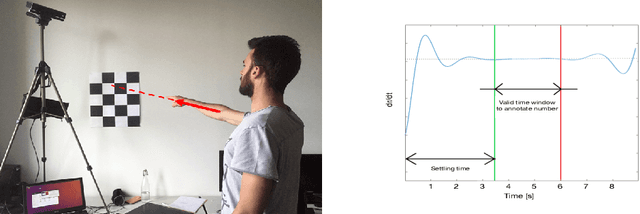


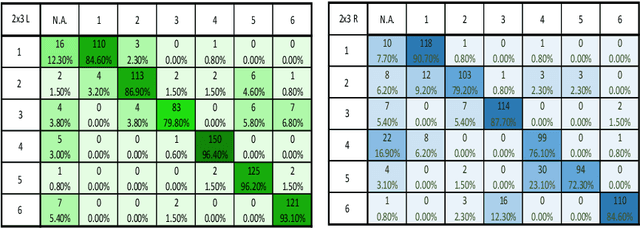
Non-verbal communication is part of our regular conversation, and multiple gestures are used to exchange information. Among those gestures, pointing is the most important one. If such gestures cannot be perceived by other team members, e.g. by blind and visually impaired people (BVIP), they lack important information and can hardly participate in a lively workflow. Thus, this paper describes a system for detecting such pointing gestures to provide input for suitable output modalities to BVIP. Our system employs an RGB-D camera to recognize the pointing gestures performed by the users. The system also locates the target of pointing e.g. on a common workspace. We evaluated the system by conducting a user study with 26 users. The results show that the system has a success rate of 89.59 and 79.92 % for a 2 x 3 matrix using the left and right arm respectively, and 73.57 and 68.99 % for 3 x 4 matrix using the left and right arm respectively.
Res3ATN -- Deep 3D Residual Attention Network for Hand Gesture Recognition in Videos
Jan 04, 2020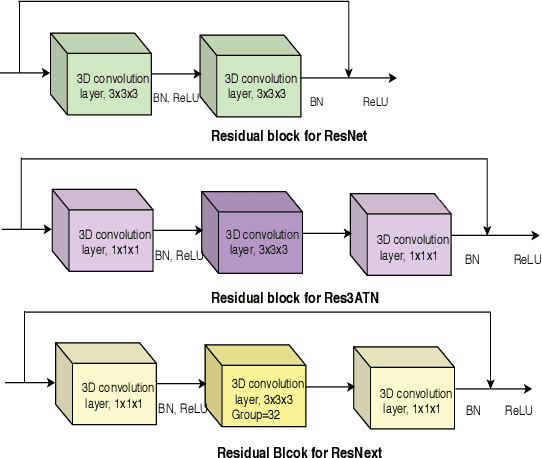
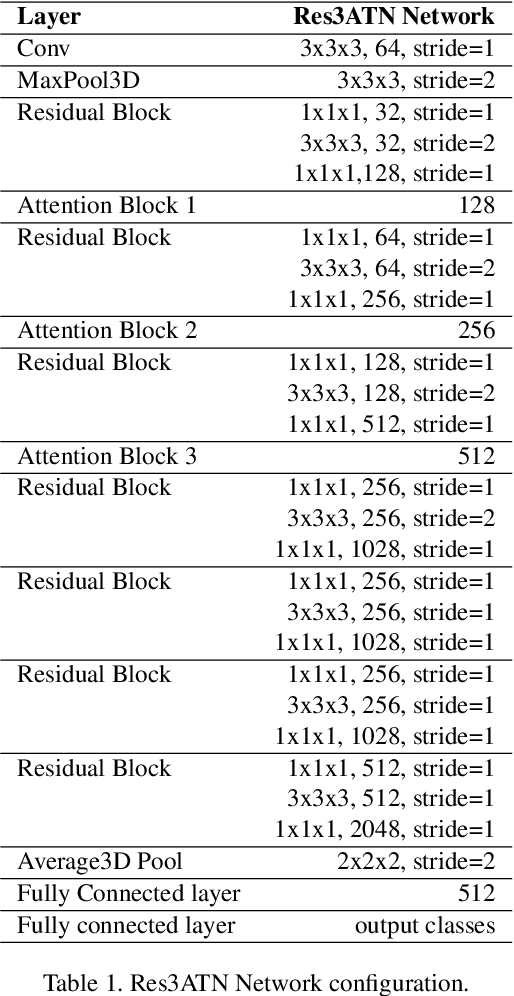
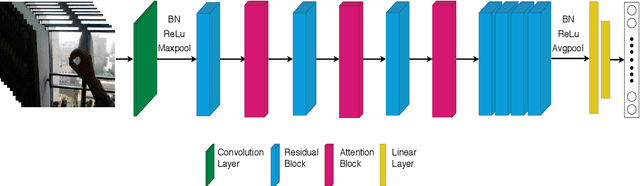
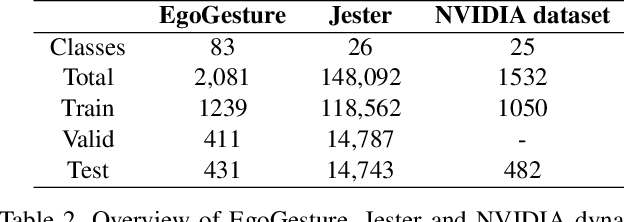
Hand gesture recognition is a strenuous task to solve in videos. In this paper, we use a 3D residual attention network which is trained end to end for hand gesture recognition. Based on the stacked multiple attention blocks, we build a 3D network which generates different features at each attention block. Our 3D attention based residual network (Res3ATN) can be built and extended to very deep layers. Using this network, an extensive analysis is performed on other 3D networks based on three publicly available datasets. The Res3ATN network performance is compared to C3D, ResNet-10, and ResNext-101 networks. We also study and evaluate our baseline network with different number of attention blocks. The comparison shows that the 3D residual attention network with 3 attention blocks is robust in attention learning and is able to classify the gestures with better accuracy, thus outperforming existing networks.
* 10 pages, 4 figures, International Conference on 3D Vision (3DV 2019), Quebec City, Canada, September 16-19, 2019