 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-efficient Alignment of Multimodal Sequences by Aligning Gradient Updates and Internal Feature Distributions
Paper and Code


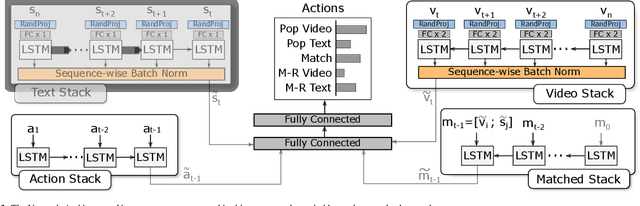

The task of video and text sequence alignment is a prerequisite step toward joint understanding of movie videos and screenplays. However, supervised methods face the obstacle of limited realistic training data. With this paper, we attempt to enhance data efficiency of the end-to-end alignment network NeuMATCH [15]. Recent research [56] suggests that network components dealing with different modalities may overfit and generalize at different speeds, creating difficulties for training. We propose to employ (1) layer-wise adaptive rate scaling (LARS) to align the magnitudes of gradient updates in different layers and balance the pace of learning and (2) sequence-wise batch normalization (SBN) to align the internal feature distributions from different modalities. Finally, we leverage random projection to reduce the dimensionality of input features. On the YouTube Movie Summary dataset, the combined use of these technique closes the performance gap when the pretraining on the LSMDC dataset is omitted and achieves the state-of-the-art result. Extensive empirical comparisons and analysis reveal that these techniques improve optimization and regularize the network more effectively than two different setups of layer normalization.