 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrimDiffusion: Volumetric Primitives Diffusion for 3D Human Generation
Paper and Code
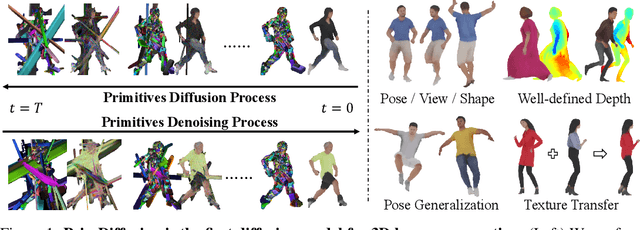

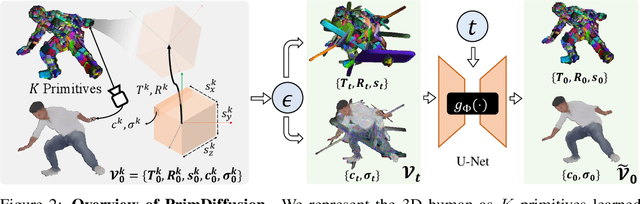

We present PrimDiffusion, the first diffusion-based framework for 3D human generation. Devising diffusion models for 3D human generation is difficult due to the intensive computational cost of 3D representations and the articulated topology of 3D humans. To tackle these challenges, our key insight is operating the denoising diffusion process directly on a set of volumetric primitives, which models the human body as a number of small volumes with radiance and kinematic information. This volumetric primitives representation marries the capacity of volumetric representations with the efficiency of primitive-based rendering. Our PrimDiffusion framework has three appealing properties: 1) compact and expressive parameter space for the diffusion model, 2) flexible 3D representation that incorporates human prior, and 3) decoder-free rendering for efficient novel-view and novel-pose synthesis. Extensive experiments validate that PrimDiffusion outperforms state-of-the-art methods in 3D human generation. Notably, compared to GAN-based methods, our PrimDiffusion supports real-time rendering of high-quality 3D humans at a resolution of $512\times512$ once the denoising process is done. We also demonstrate the flexibility of our framework on training-free conditional generation such as texture transfer and 3D inpainting.