 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeESPnet-Codec: Comprehensive Training and Evaluation of Neural Codecs for Audio, Music, and Speech
Sep 24, 2024Neural codecs have become crucial to recent speech and audio generation research. In addition to signal compression capabilities, discrete codecs have also been found to enhance downstream training efficiency and compatibility with autoregressive language models. However, as extensive downstream applications are investigated, challenges have arisen in ensuring fair comparisons across diverse applications. To address these issues, we present a new open-source platform ESPnet-Codec, which is built on ESPnet and focuses on neural codec training and evaluation. ESPnet-Codec offers various recipes in audio, music, and speech for training and evaluation using several widely adopted codec models. Together with ESPnet-Codec, we present VERSA, a standalone evaluation toolkit, which provides a comprehensive evaluation of codec performance over 20 audio evaluation metrics. Notably, we demonstrate that ESPnet-Codec can be integrated into six ESPnet tasks, supporting diverse applications.
Speech Recognition for Analysis of Police Radio Communication
Sep 17, 2024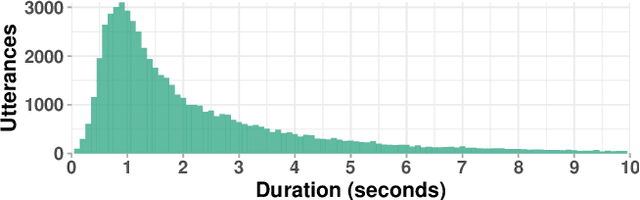
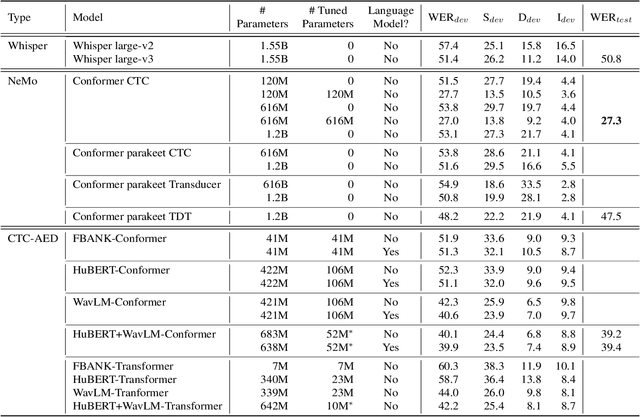

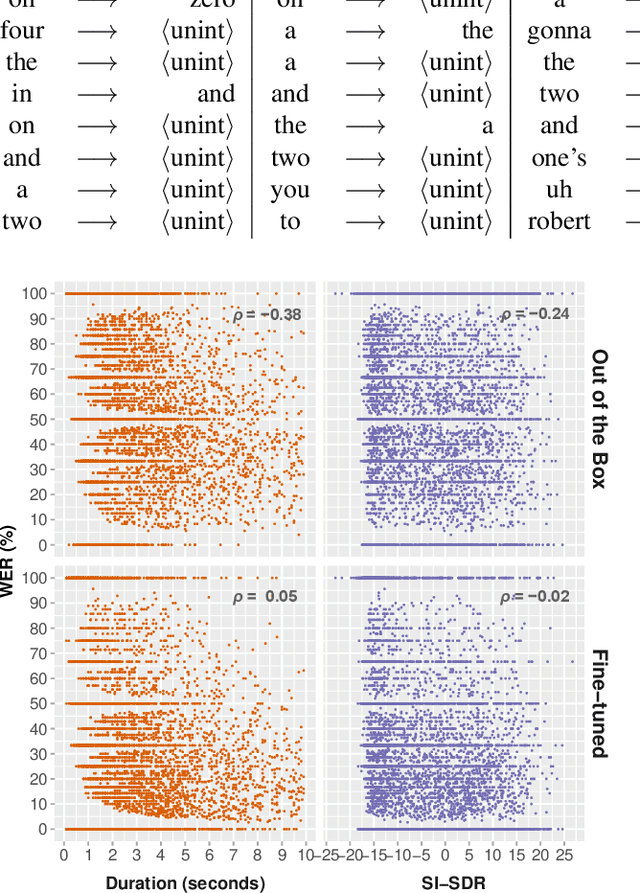
Police departments around the world use two-way radio for coordination. These broadcast police communications (BPC) are a unique source of information about everyday police activity and emergency response. Yet BPC are not transcribed, and their naturalistic audio properties make automatic transcription challenging. We collect a corpus of roughly 62,000 manually transcribed radio transmissions (~46 hours of audio) to evaluate the feasibility of automatic speech recognition (ASR) using modern recognition models. We evaluate the performance of off-the-shelf speech recognizers, models fine-tuned on BPC data, and customized end-to-end models. We find that both human and machine transcription is challenging in this domain. Large off-the-shelf ASR models perform poorly, but fine-tuned models can reach the approximate range of human performance. Our work suggests directions for future work, including analysis of short utterances and potential miscommunication in police radio interactions. We make our corpus and data annotation pipeline available to other researchers, to enable further research on recognition and analysis of police communication.
Hypothesis Generation with Large Language Models
Apr 05, 2024Effective generation of novel hypotheses is instrumental to scientific progress. So far, researchers have been the main powerhouse behind hypothesis generation by painstaking data analysis and thinking (also known as the Eureka moment). In this paper, we examine the potential of large language models (LLMs) to generate hypotheses. We focus on hypothesis generation based on data (i.e., labeled examples). To enable LLMs to handle arbitrarily long contexts, we generate initial hypotheses from a small number of examples and then update them iteratively to improve the quality of hypotheses. Inspired by multi-armed bandits, we design a reward function to inform the exploitation-exploration tradeoff in the update process. Our algorithm is able to generate hypotheses that enable much better predictive performance than few-shot prompting in classification tasks, improving accuracy by 31.7% on a synthetic dataset and by 13.9%, 3.3% and, 24.9% on three real-world datasets. We also outperform supervised learning by 12.8% and 11.2% on two challenging real-world datasets. Furthermore, we find that the generated hypotheses not only corroborate human-verified theories but also uncover new insights for the tasks.
EFFUSE: Efficient Self-Supervised Feature Fusion for E2E ASR in Multilingual and Low Resource Scenarios
Oct 05, 2023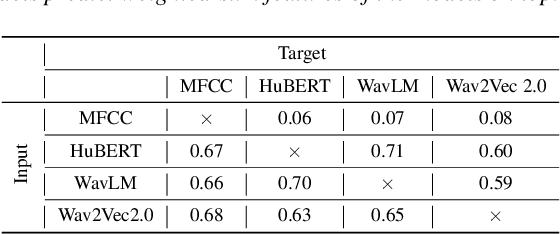
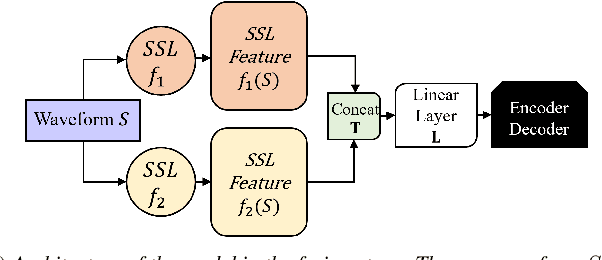
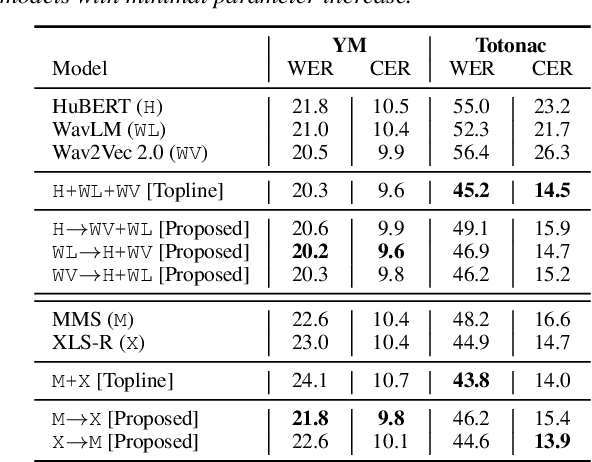
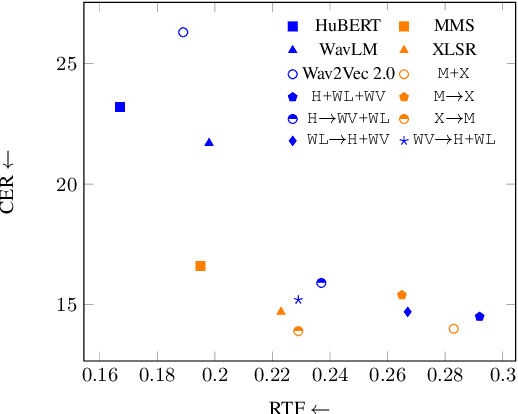
Self-Supervised Learning (SSL) models have demonstrated exceptional performance in various speech tasks, particularly in low-resource and multilingual domains. Recent works show that fusing SSL models could achieve superior performance compared to using one SSL model. However, fusion models have increased model parameter size, leading to longer inference times. In this paper, we propose a novel approach of predicting other SSL models' features from a single SSL model, resulting in a light-weight framework with competitive performance. Our experiments show that SSL feature prediction models outperform individual SSL models in multilingual speech recognition tasks. The leading prediction model achieves an average SUPERB score increase of 135.4 in ML-SUPERB benchmarks. Moreover, our proposed framework offers an efficient solution, as it reduces the resulting model parameter size and inference times compared to previous fusion models.
A Riemannian ADMM
Nov 03, 2022We consider a class of Riemannian optimization problems where the objective is the sum of a smooth function and a nonsmooth function, considered in the ambient space. This class of problems finds important applications in machine learning and statistics such as the sparse principal component analysis, sparse spectral clustering, and orthogonal dictionary learning. We propose a Riemannian alternating direction method of multipliers (ADMM) to solve this class of problems. Our algorithm adopts easily computable steps in each iteration. The iteration complexity of the proposed algorithm for obtaining an $\epsilon$-stationary point is analyzed under mild assumptions. To the best of our knowledge, this is the first Riemannian ADMM with provable convergence guarantee for solving Riemannian optimization problem with nonsmooth objective. Numerical experiments are conducted to demonstrate the advantage of the proposed method.