 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Fallacy of Global Token Perplexity in Spoken Language Model Evaluation
Jan 09, 2026Generative spoken language models pretrained on large-scale raw audio can continue a speech prompt with appropriate content while preserving attributes like speaker and emotion, serving as foundation models for spoken dialogue. In prior literature, these models are often evaluated using ``global token perplexity'', which directly applies the text perplexity formulation to speech tokens. However, this practice overlooks fundamental differences between speech and text modalities, possibly leading to an underestimation of the speech characteristics. In this work, we propose a variety of likelihood- and generative-based evaluation methods that serve in place of naive global token perplexity. We demonstrate that the proposed evaluations more faithfully reflect perceived generation quality, as evidenced by stronger correlations with human-rated mean opinion scores (MOS). When assessed under the new metrics, the relative performance landscape of spoken language models is reshaped, revealing a significantly reduced gap between the best-performing model and the human topline. Together, these results suggest that appropriate evaluation is critical for accurately assessing progress in spoken language modeling.
Speech Recognition for Analysis of Police Radio Communication
Sep 17, 2024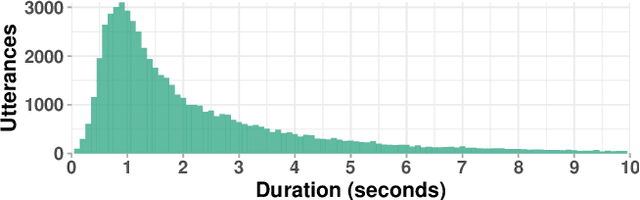
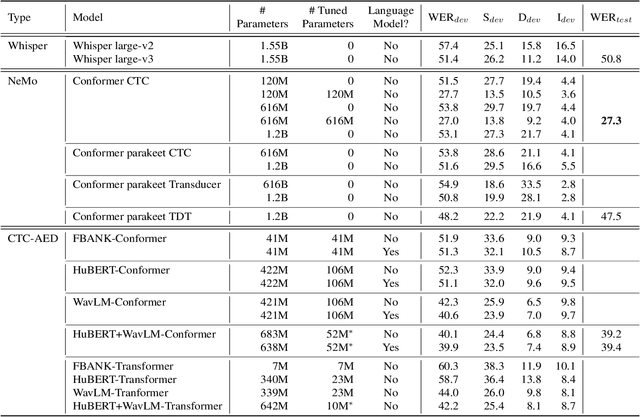

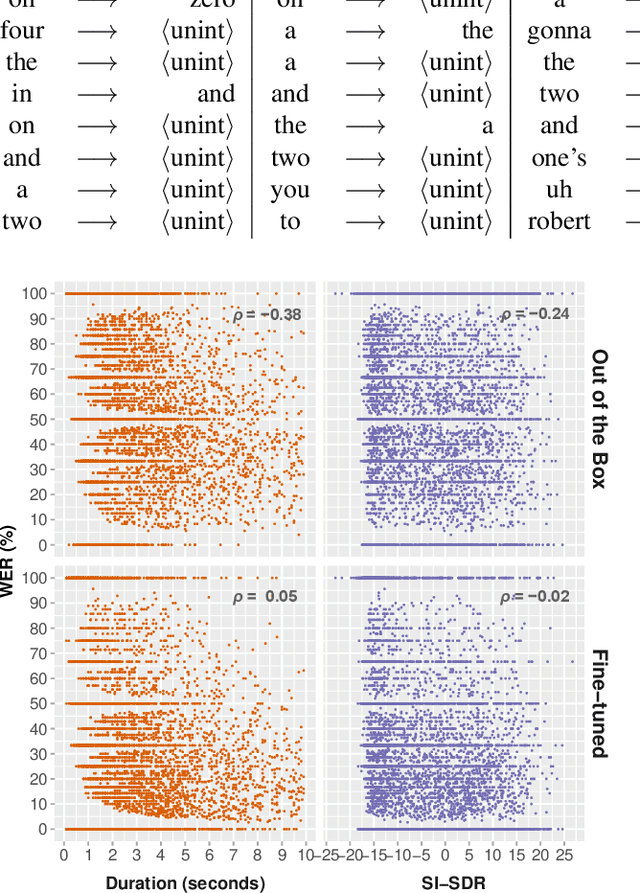
Police departments around the world use two-way radio for coordination. These broadcast police communications (BPC) are a unique source of information about everyday police activity and emergency response. Yet BPC are not transcribed, and their naturalistic audio properties make automatic transcription challenging. We collect a corpus of roughly 62,000 manually transcribed radio transmissions (~46 hours of audio) to evaluate the feasibility of automatic speech recognition (ASR) using modern recognition models. We evaluate the performance of off-the-shelf speech recognizers, models fine-tuned on BPC data, and customized end-to-end models. We find that both human and machine transcription is challenging in this domain. Large off-the-shelf ASR models perform poorly, but fine-tuned models can reach the approximate range of human performance. Our work suggests directions for future work, including analysis of short utterances and potential miscommunication in police radio interactions. We make our corpus and data annotation pipeline available to other researchers, to enable further research on recognition and analysis of police communication.
Toward Joint Language Modeling for Speech Units and Text
Oct 12, 2023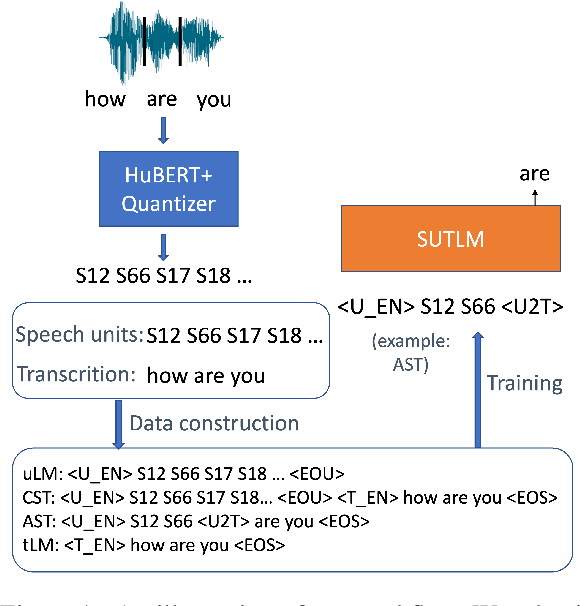

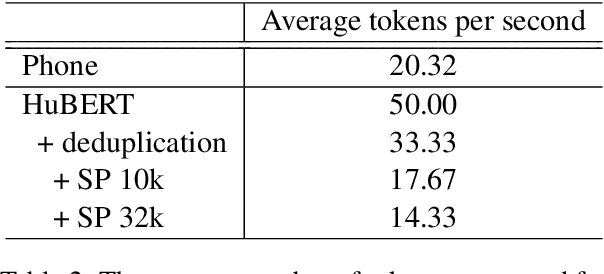
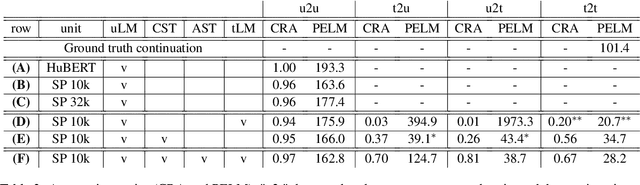
Speech and text are two major forms of human language. The research community has been focusing on mapping speech to text or vice versa for many years. However, in the field of language modeling, very little effort has been made to model them jointly. In light of this, we explore joint language modeling for speech units and text. Specifically, we compare different speech tokenizers to transform continuous speech signals into discrete units and use different methods to construct mixed speech-text data. We introduce automatic metrics to evaluate how well the joint LM mixes speech and text. We also fine-tune the LM on downstream spoken language understanding (SLU) tasks with different modalities (speech or text) and test its performance to assess the model's learning of shared representations. Our results show that by mixing speech units and text with our proposed mixing techniques, the joint LM improves over a speech-only baseline on SLU tasks and shows zero-shot cross-modal transferability.
Few-Shot Spoken Language Understanding via Joint Speech-Text Models
Oct 09, 2023Recent work on speech representation models jointly pre-trained with text has demonstrated the potential of improving speech representations by encoding speech and text in a shared space. In this paper, we leverage such shared representations to address the persistent challenge of limited data availability in spoken language understanding tasks. By employing a pre-trained speech-text model, we find that models fine-tuned on text can be effectively transferred to speech testing data. With as little as 1 hour of labeled speech data, our proposed approach achieves comparable performance on spoken language understanding tasks (specifically, sentiment analysis and named entity recognition) when compared to previous methods using speech-only pre-trained models fine-tuned on 10 times more data. Beyond the proof-of-concept study, we also analyze the latent representations. We find that the bottom layers of speech-text models are largely task-agnostic and align speech and text representations into a shared space, while the top layers are more task-specific.
AV2Wav: Diffusion-Based Re-synthesis from Continuous Self-supervised Features for Audio-Visual Speech Enhancement
Sep 14, 2023Speech enhancement systems are typically trained using pairs of clean and noisy speech. In audio-visual speech enhancement (AVSE), there is not as much ground-truth clean data available; most audio-visual datasets are collected in real-world environments with background noise and reverberation, hampering the development of AVSE. In this work, we introduce AV2Wav, a resynthesis-based audio-visual speech enhancement approach that can generate clean speech despite the challenges of real-world training data. We obtain a subset of nearly clean speech from an audio-visual corpus using a neural quality estimator, and then train a diffusion model on this subset to generate waveforms conditioned on continuous speech representations from AV-HuBERT with noise-robust training. We use continuous rather than discrete representations to retain prosody and speaker information. With this vocoding task alone, the model can perform speech enhancement better than a masking-based baseline. We further fine-tune the diffusion model on clean/noisy utterance pairs to improve the performance. Our approach outperforms a masking-based baseline in terms of both automatic metrics and a human listening test and is close in quality to the target speech in the listening test. Audio samples can be found at https://home.ttic.edu/~jcchou/demo/avse/avse_demo.html.
Layer-wise Analysis of a Self-supervised Speech Representation Model
Jul 10, 2021



Recently proposed self-supervised learning approaches have been successful for pre-training speech representation models. The utility of these learned representations has been observed empirically, but not much has been studied about the type or extent of information encoded in the pre-trained representations themselves. Developing such insights can help understand the capabilities and limits of these models and enable the research community to more efficiently develop their usage for downstream applications. In this work, we begin to fill this gap by examining one recent and successful pre-trained model (wav2vec 2.0), via its intermediate representation vectors, using a suite of analysis tools. We use the metrics of canonical correlation, mutual information, and performance on simple downstream tasks with non-parametric probes, in order to (i) query for acoustic and linguistic information content, (ii) characterize the evolution of information across model layers, and (iii) understand how fine-tuning the model for automatic speech recognition (ASR) affects these observations. Our findings motivate modifying the fine-tuning protocol for ASR, which produces improved word error rates in a low-resource setting.
SpeechBrain: A General-Purpose Speech Toolkit
Jun 08, 2021
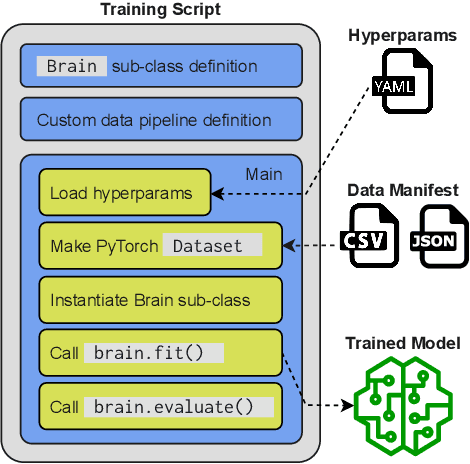

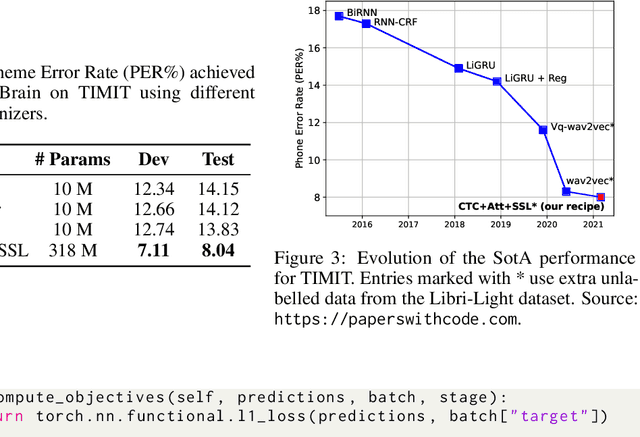
SpeechBrain is an open-source and all-in-one speech toolkit. It is designed to facilitate the research and development of neural speech processing technologies by being simple, flexible, user-friendly, and well-documented. This paper describes the core architecture designed to support several tasks of common interest, allowing users to naturally conceive, compare and share novel speech processing pipelines. SpeechBrain achieves competitive or state-of-the-art performance in a wide range of speech benchmarks. It also provides training recipes, pretrained models, and inference scripts for popular speech datasets, as well as tutorials which allow anyone with basic Python proficiency to familiarize themselves with speech technologies.