 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEFFUSE: Efficient Self-Supervised Feature Fusion for E2E ASR in Multilingual and Low Resource Scenarios
Paper and Code
Oct 05, 2023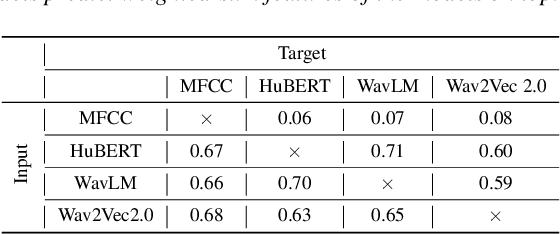
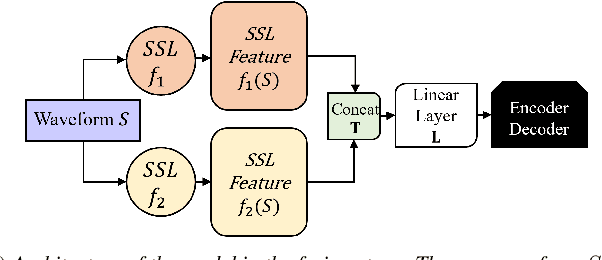
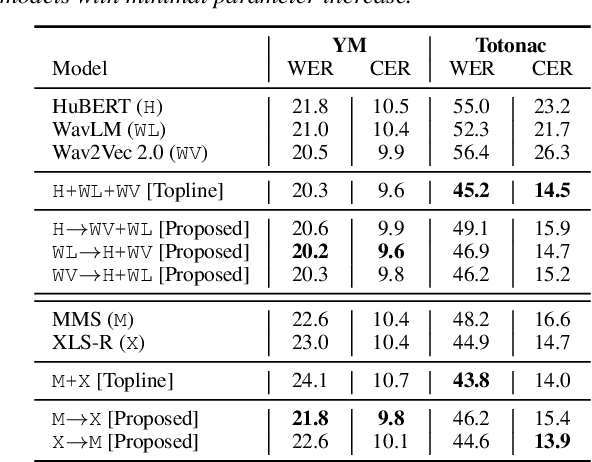
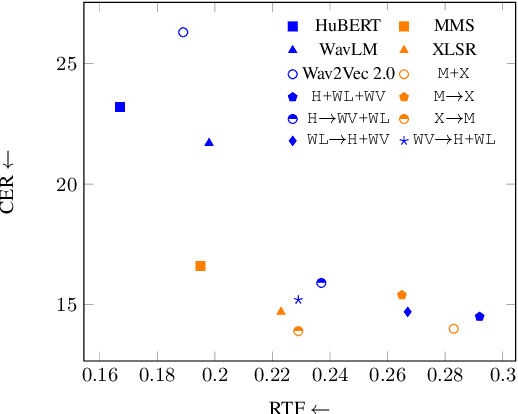
Self-Supervised Learning (SSL) models have demonstrated exceptional performance in various speech tasks, particularly in low-resource and multilingual domains. Recent works show that fusing SSL models could achieve superior performance compared to using one SSL model. However, fusion models have increased model parameter size, leading to longer inference times. In this paper, we propose a novel approach of predicting other SSL models' features from a single SSL model, resulting in a light-weight framework with competitive performance. Our experiments show that SSL feature prediction models outperform individual SSL models in multilingual speech recognition tasks. The leading prediction model achieves an average SUPERB score increase of 135.4 in ML-SUPERB benchmarks. Moreover, our proposed framework offers an efficient solution, as it reduces the resulting model parameter size and inference times compared to previous fusion models.