 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimuScene: Training and Benchmarking Code Generation to Simulate Physical Scenarios
Feb 11, 2026Large language models (LLMs) have been extensively studied for tasks like math competitions, complex coding, and scientific reasoning, yet their ability to accurately represent and simulate physical scenarios via code remains underexplored. We propose SimuScene, the first systematic study that trains and evaluates LLMs on simulating physical scenarios across five physics domains and 52 physical concepts. We build an automatic pipeline to collect data, with human verification to ensure quality. The final dataset contains 7,659 physical scenarios with 334 human-verified examples as the test set. We evaluated 10 contemporary LLMs and found that even the strongest model achieves only a 21.5% pass rate, demonstrating the difficulty of the task. Finally, we introduce a reinforcement learning pipeline with visual rewards that uses a vision-language model as a judge to train textual models. Experiments show that training with our data improves physical simulation via code while substantially enhancing general code generation performance.
Neural Theorem Proving for Verification Conditions: A Real-World Benchmark
Jan 26, 2026Theorem proving is fundamental to program verification, where the automated proof of Verification Conditions (VCs) remains a primary bottleneck. Real-world program verification frequently encounters hard VCs that existing Automated Theorem Provers (ATPs) cannot prove, leading to a critical need for extensive manual proofs that burden practical application. While Neural Theorem Proving (NTP) has achieved significant success in mathematical competitions, demonstrating the potential of machine learning approaches to formal reasoning, its application to program verification--particularly VC proving--remains largely unexplored. Despite existing work on annotation synthesis and verification-related theorem proving, no benchmark has specifically targeted this fundamental bottleneck: automated VC proving. This work introduces Neural Theorem Proving for Verification Conditions (NTP4VC), presenting the first real-world multi-language benchmark for this task. From real-world projects such as Linux and Contiki-OS kernel, our benchmark leverages industrial pipelines (Why3 and Frama-C) to generate semantically equivalent test cases across formal languages of Isabelle, Lean, and Rocq. We evaluate large language models (LLMs), both general-purpose and those fine-tuned for theorem proving, on NTP4VC. Results indicate that although LLMs show promise in VC proving, significant challenges remain for program verification, highlighting a large gap and opportunity for future research.
SCALAR: Scientific Citation-based Live Assessment of Long-context Academic Reasoning
Feb 19, 2025Evaluating large language models' (LLMs) long-context understanding capabilities remains challenging. We present SCALAR (Scientific Citation-based Live Assessment of Long-context Academic Reasoning), a novel benchmark that leverages academic papers and their citation networks. SCALAR features automatic generation of high-quality ground truth labels without human annotation, controllable difficulty levels, and a dynamic updating mechanism that prevents data contamination. Using ICLR 2025 papers, we evaluate 8 state-of-the-art LLMs, revealing key insights about their capabilities and limitations in processing long scientific documents across different context lengths and reasoning types. Our benchmark provides a reliable and sustainable way to track progress in long-context understanding as LLM capabilities evolve.
LLM360 K2: Building a 65B 360-Open-Source Large Language Model from Scratch
Jan 16, 2025



We detail the training of the LLM360 K2-65B model, scaling up our 360-degree OPEN SOURCE approach to the largest and most powerful models under project LLM360. While open-source LLMs continue to advance, the answer to "How are the largest LLMs trained?" remains unclear within the community. The implementation details for such high-capacity models are often protected due to business considerations associated with their high cost. This lack of transparency prevents LLM researchers from leveraging valuable insights from prior experience, e.g., "What are the best practices for addressing loss spikes?" The LLM360 K2 project addresses this gap by providing full transparency and access to resources accumulated during the training of LLMs at the largest scale. This report highlights key elements of the K2 project, including our first model, K2 DIAMOND, a 65 billion-parameter LLM that surpasses LLaMA-65B and rivals LLaMA2-70B, while requiring fewer FLOPs and tokens. We detail the implementation steps and present a longitudinal analysis of K2 DIAMOND's capabilities throughout its training process. We also outline ongoing projects such as TXT360, setting the stage for future models in the series. By offering previously unavailable resources, the K2 project also resonates with the 360-degree OPEN SOURCE principles of transparency, reproducibility, and accessibility, which we believe are vital in the era of resource-intensive AI research.
Libra-Leaderboard: Towards Responsible AI through a Balanced Leaderboard of Safety and Capability
Dec 24, 2024



To address this gap, we introduce Libra-Leaderboard, a comprehensive framework designed to rank LLMs through a balanced evaluation of performance and safety. Combining a dynamic leaderboard with an interactive LLM arena, Libra-Leaderboard encourages the joint optimization of capability and safety. Unlike traditional approaches that average performance and safety metrics, Libra-Leaderboard uses a distance-to-optimal-score method to calculate the overall rankings. This approach incentivizes models to achieve a balance rather than excelling in one dimension at the expense of some other ones. In the first release, Libra-Leaderboard evaluates 26 mainstream LLMs from 14 leading organizations, identifying critical safety challenges even in state-of-the-art models.
Explore the Reasoning Capability of LLMs in the Chess Testbed
Nov 11, 2024



Reasoning is a central capability of human intelligence. In recent years, with the advent of large-scale datasets, pretrained large language models have emerged with new capabilities, including reasoning. However, these models still struggle with long-term, complex reasoning tasks, such as playing chess. Based on the observation that expert chess players employ a dual approach combining long-term strategic play with short-term tactical play along with language explanation, we propose improving the reasoning capability of large language models in chess by integrating annotated strategy and tactic. Specifically, we collect a dataset named MATE, which consists of 1 million chess positions with candidate moves annotated by chess experts for strategy and tactics. We finetune the LLaMA-3-8B model and compare it against state-of-the-art commercial language models in the task of selecting better chess moves. Our experiments show that our models perform better than GPT, Claude, and Gemini models. We find that language explanations can enhance the reasoning capability of large language models.
ToolGen: Unified Tool Retrieval and Calling via Generation
Oct 04, 2024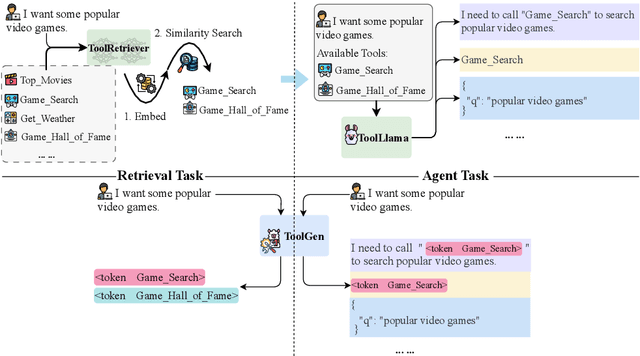
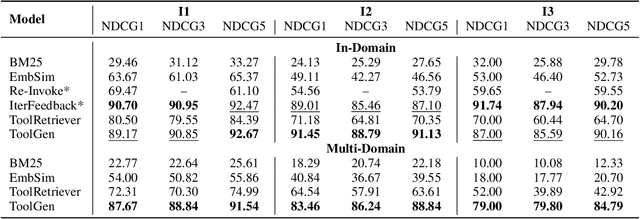
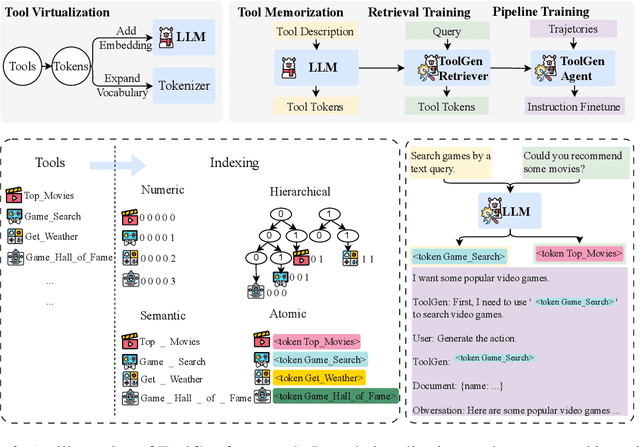

As large language models (LLMs) advance, their inability to autonomously execute tasks by directly interacting with external tools remains a critical limitation. Traditional methods rely on inputting tool descriptions as context, which is constrained by context length and requires separate, often inefficient, retrieval mechanisms. We introduce ToolGen, a paradigm shift that integrates tool knowledge directly into the LLM's parameters by representing each tool as a unique token. This enables the LLM to generate tool calls and arguments as part of its next token prediction capabilities, seamlessly blending tool invocation with language generation. Our framework allows the LLM to access and utilize a vast amount of tools with no additional retrieval step, significantly enhancing both performance and scalability. Experimental results with over 47,000 tools show that ToolGen not only achieves superior results in both tool retrieval and autonomous task completion but also sets the stage for a new era of AI agents that can adapt to tools across diverse domains. By fundamentally transforming tool retrieval into a generative process, ToolGen paves the way for more versatile, efficient, and autonomous AI systems. ToolGen enables end-to-end tool learning and opens opportunities for integration with other advanced techniques such as chain-of-thought and reinforcement learning, thereby expanding the practical capabilities of LLMs.
Against The Achilles' Heel: A Survey on Red Teaming for Generative Models
Mar 31, 2024



Generative models are rapidly gaining popularity and being integrated into everyday applications, raising concerns over their safety issues as various vulnerabilities are exposed. Faced with the problem, the field of red teaming is experiencing fast-paced growth, which highlights the need for a comprehensive organization covering the entire pipeline and addressing emerging topics for the community. Our extensive survey, which examines over 120 papers, introduces a taxonomy of fine-grained attack strategies grounded in the inherent capabilities of language models. Additionally, we have developed the searcher framework that unifies various automatic red teaming approaches. Moreover, our survey covers novel areas including multimodal attacks and defenses, risks around multilingual models, overkill of harmless queries, and safety of downstream applications. We hope this survey can provide a systematic perspective on the field and unlock new areas of research.
Learning From Failure: Integrating Negative Examples when Fine-tuning Large Language Models as Agents
Feb 18, 2024



Large language models (LLMs) have achieved success in acting as agents, which interact with environments through tools like search engines. However, LLMs are not optimized specifically for tool use during training or alignment, limiting their effectiveness as agents. To resolve this problem, previous work has collected interaction trajectories between GPT-4 and environments, and fine-tuned smaller models with them. As part of this, the standard approach has been to simply discard trajectories that do not finish the task successfully, which, on the one hand, leads to a significant waste of data and resources, and on the other hand, has the potential to limit the possible optimization paths during fine-tuning. In this paper, we contend that large language models can learn from failures through appropriate data cleaning and fine-tuning strategies. We conduct experiments on mathematical reasoning, multi-hop question answering, and strategic question answering tasks. Experimental results demonstrate that compared to solely using positive examples, incorporating negative examples enhances model performance by a large margin.
Understanding the Instruction Mixture for Large Language Model Fine-tuning
Dec 19, 2023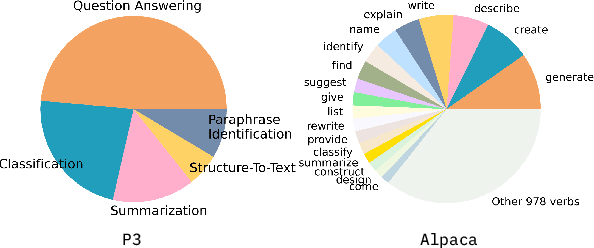
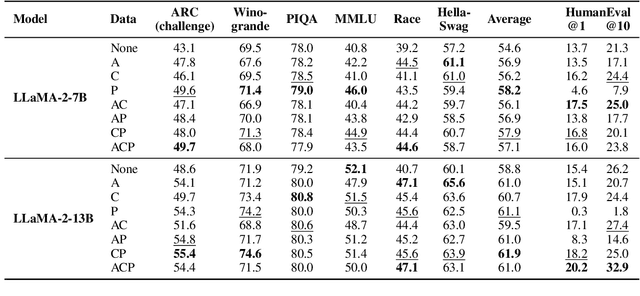
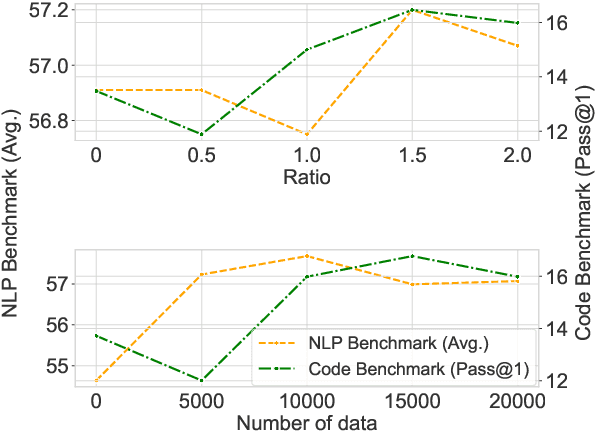
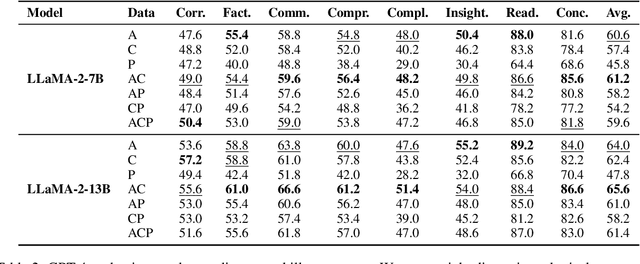
While instructions fine-tuning of large language models (LLMs) has been proven to enhance performance across various applications, the influence of the instruction dataset mixture on LLMs has not been thoroughly explored. In this study, we classify instructions into three main types: NLP downstream tasks, coding, and general chatting, and investigate their impact on LLMs. Our findings reveal that specific types of instructions are more beneficial for particular uses, while it may cause harms to other aspects, emphasizing the importance of meticulously designing the instruction mixture to maximize model performance. This study sheds light on the instruction mixture and paves the way for future research.