Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Instruction Mixture for Large Language Model Fine-tuning
Paper and Code
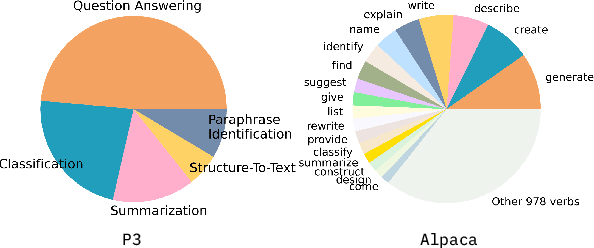
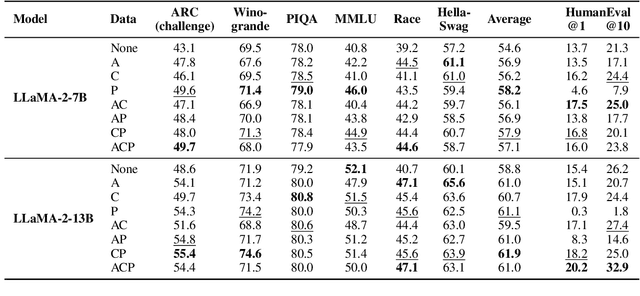
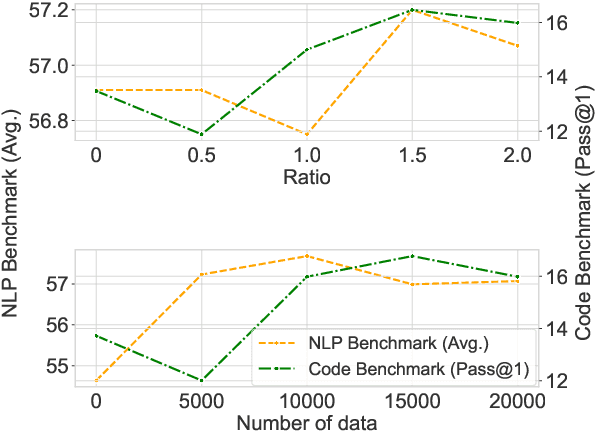
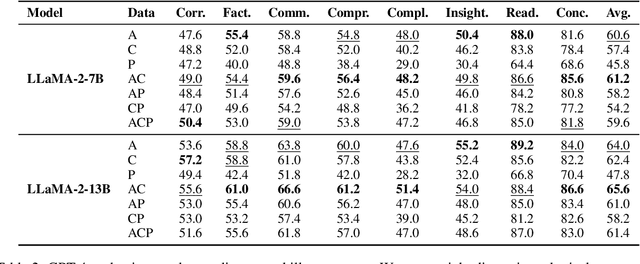
While instructions fine-tuning of large language models (LLMs) has been proven to enhance performance across various applications, the influence of the instruction dataset mixture on LLMs has not been thoroughly explored. In this study, we classify instructions into three main types: NLP downstream tasks, coding, and general chatting, and investigate their impact on LLMs. Our findings reveal that specific types of instructions are more beneficial for particular uses, while it may cause harms to other aspects, emphasizing the importance of meticulously designing the instruction mixture to maximize model performance. This study sheds light on the instruction mixture and paves the way for future research.
* Instruction Tuning, Large Language Model, Alignment
View paper on