 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Case or Not to Case: An Empirical Study in Learned Sparse Retrieval
Jan 24, 2026Learned Sparse Retrieval (LSR) methods construct sparse lexical representations of queries and documents that can be efficiently searched using inverted indexes. Existing LSR approaches have relied almost exclusively on uncased backbone models, whose vocabularies exclude case-sensitive distinctions, thereby reducing vocabulary mismatch. However, the most recent state-of-the-art language models are only available in cased versions. Despite this shift, the impact of backbone model casing on LSR has not been studied, potentially posing a risk to the viability of the method going forward. To fill this gap, we systematically evaluate paired cased and uncased versions of the same backbone models across multiple datasets to assess their suitability for LSR. Our findings show that LSR models with cased backbone models by default perform substantially worse than their uncased counterparts; however, this gap can be eliminated by pre-processing the text to lowercase. Moreover, our token-level analysis reveals that, under lowercasing, cased models almost entirely suppress cased vocabulary items and behave effectively as uncased models, explaining their restored performance. This result broadens the applicability of recent cased models to the LSR setting and facilitates the integration of stronger backbone architectures into sparse retrieval. The complete code and implementation for this project are available at: https://github.com/lionisakis/Uncased-vs-cased-models-in-LSR
Hierarchical Multi-Positive Contrastive Learning for Patent Image Retrieval
Jun 16, 2025Patent images are technical drawings that convey information about a patent's innovation. Patent image retrieval systems aim to search in vast collections and retrieve the most relevant images. Despite recent advances in information retrieval, patent images still pose significant challenges due to their technical intricacies and complex semantic information, requiring efficient fine-tuning for domain adaptation. Current methods neglect patents' hierarchical relationships, such as those defined by the Locarno International Classification (LIC) system, which groups broad categories (e.g., "furnishing") into subclasses (e.g., "seats" and "beds") and further into specific patent designs. In this work, we introduce a hierarchical multi-positive contrastive loss that leverages the LIC's taxonomy to induce such relations in the retrieval process. Our approach assigns multiple positive pairs to each patent image within a batch, with varying similarity scores based on the hierarchical taxonomy. Our experimental analysis with various vision and multimodal models on the DeepPatent2 dataset shows that the proposed method enhances the retrieval results. Notably, our method is effective with low-parameter models, which require fewer computational resources and can be deployed on environments with limited hardware.
VISION DIFFMASK: Faithful Interpretation of Vision Transformers with Differentiable Patch Masking
Apr 13, 2023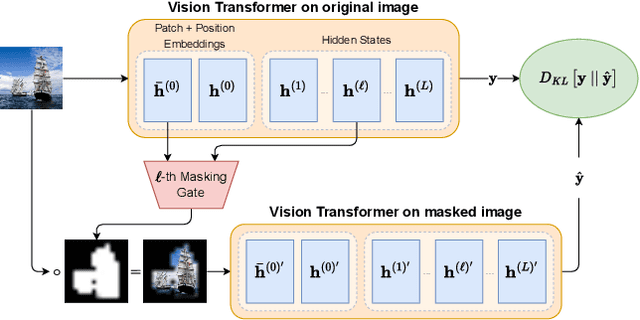
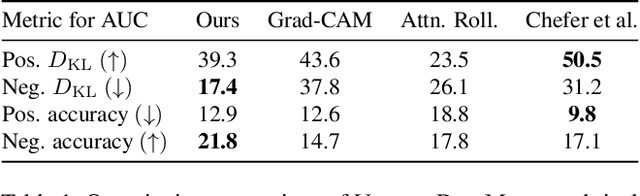


The lack of interpretability of the Vision Transformer may hinder its use in critical real-world applications despite its effectiveness. To overcome this issue, we propose a post-hoc interpretability method called VISION DIFFMASK, which uses the activations of the model's hidden layers to predict the relevant parts of the input that contribute to its final predictions. Our approach uses a gating mechanism to identify the minimal subset of the original input that preserves the predicted distribution over classes. We demonstrate the faithfulness of our method, by introducing a faithfulness task, and comparing it to other state-of-the-art attribution methods on CIFAR-10 and ImageNet-1K, achieving compelling results. To aid reproducibility and further extension of our work, we open source our implementation: https://github.com/AngelosNal/Vision-DiffMask