 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrating LLM Judges: Linear Probes for Fast and Reliable Uncertainty Estimation
Dec 23, 2025As LLM-based judges become integral to industry applications, obtaining well-calibrated uncertainty estimates efficiently has become critical for production deployment. However, existing techniques, such as verbalized confidence and multi-generation methods, are often either poorly calibrated or computationally expensive. We introduce linear probes trained with a Brier score-based loss to provide calibrated uncertainty estimates from reasoning judges' hidden states, requiring no additional model training. We evaluate our approach on both objective tasks (reasoning, mathematics, factuality, coding) and subjective human preference judgments. Our results demonstrate that probes achieve superior calibration compared to existing methods with $\approx10$x computational savings, generalize robustly to unseen evaluation domains, and deliver higher accuracy on high-confidence predictions. However, probes produce conservative estimates that underperform on easier datasets but may benefit safety-critical deployments prioritizing low false-positive rates. Overall, our work demonstrates that interpretability-based uncertainty estimation provides a practical and scalable plug-and-play solution for LLM judges in production.
When Bad Data Leads to Good Models
May 07, 2025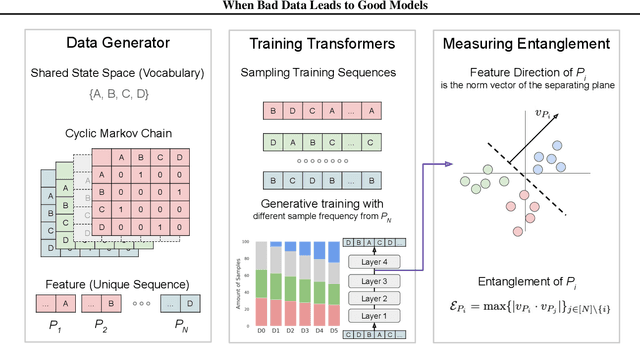
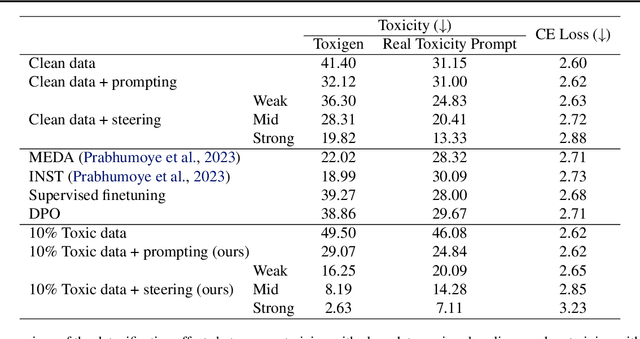
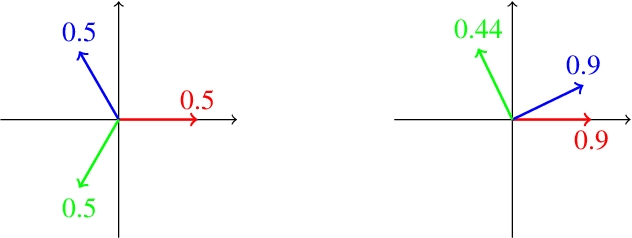
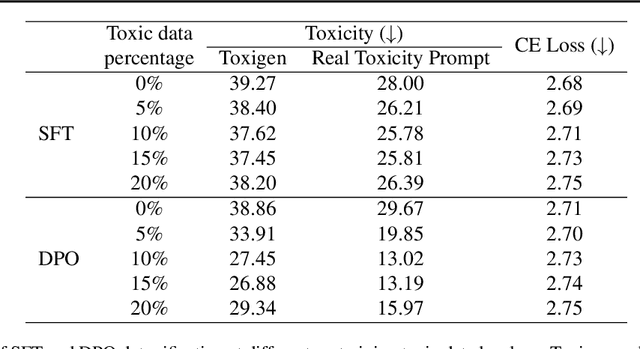
In large language model (LLM) pretraining, data quality is believed to determine model quality. In this paper, we re-examine the notion of "quality" from the perspective of pre- and post-training co-design. Specifically, we explore the possibility that pre-training on more toxic data can lead to better control in post-training, ultimately decreasing a model's output toxicity. First, we use a toy experiment to study how data composition affects the geometry of features in the representation space. Next, through controlled experiments with Olmo-1B models trained on varying ratios of clean and toxic data, we find that the concept of toxicity enjoys a less entangled linear representation as the proportion of toxic data increases. Furthermore, we show that although toxic data increases the generational toxicity of the base model, it also makes the toxicity easier to remove. Evaluations on Toxigen and Real Toxicity Prompts demonstrate that models trained on toxic data achieve a better trade-off between reducing generational toxicity and preserving general capabilities when detoxifying techniques such as inference-time intervention (ITI) are applied. Our findings suggest that, with post-training taken into account, bad data may lead to good models.
Communicating Activations Between Language Model Agents
Jan 23, 2025Communication between multiple language model (LM) agents has been shown to scale up the reasoning ability of LMs. While natural language has been the dominant medium for inter-LM communication, it is not obvious this should be the standard: not only does natural language communication incur high inference costs that scale quickly with the number of both agents and messages, but also the decoding process abstracts away too much rich information that could be otherwise accessed from the internal activations. In this work, we propose a simple technique whereby LMs communicate via activations; concretely, we pause an LM $\textit{B}$'s computation at an intermediate layer, combine its current activation with another LM $\textit{A}$'s intermediate activation via some function $\textit{f}$, then pass $\textit{f}$'s output into the next layer of $\textit{B}$ and continue the forward pass till decoding is complete. This approach scales up LMs on new tasks with zero additional parameters and data, and saves a substantial amount of compute over natural language communication. We test our method with various functional forms $\textit{f}$ on two experimental setups--multi-player coordination games and reasoning benchmarks--and find that it achieves up to $27.0\%$ improvement over natural language communication across datasets with $<$$1/4$ the compute, illustrating the superiority and robustness of activations as an alternative "language" for communication between LMs.
Dialogue Action Tokens: Steering Language Models in Goal-Directed Dialogue with a Multi-Turn Planner
Jun 17, 2024

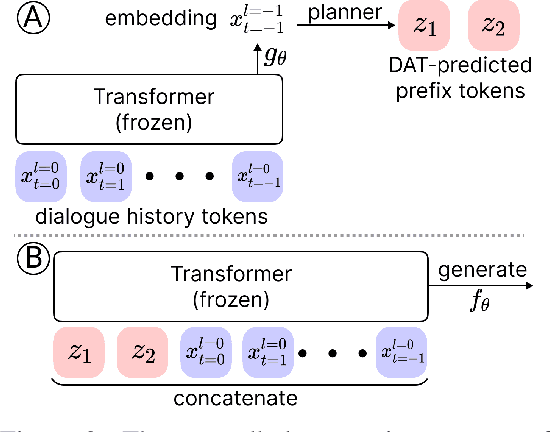
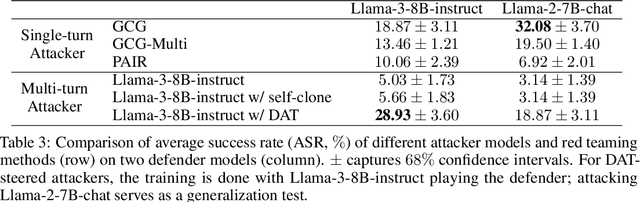
We present an approach called Dialogue Action Tokens (DAT) that adapts language model agents to plan goal-directed dialogues. The core idea is to treat each utterance as an action, thereby converting dialogues into games where existing approaches such as reinforcement learning can be applied. Specifically, we freeze a pretrained language model and train a small planner model that predicts a continuous action vector, used for controlled generation in each round. This design avoids the problem of language degradation under reward optimization. When evaluated on the Sotopia platform for social simulations, the DAT-steered LLaMA model surpasses GPT-4's performance. We also apply DAT to steer an attacker language model in a novel multi-turn red-teaming setting, revealing a potential new attack surface.
Designing a Dashboard for Transparency and Control of Conversational AI
Jun 12, 2024



Conversational LLMs function as black box systems, leaving users guessing about why they see the output they do. This lack of transparency is potentially problematic, especially given concerns around bias and truthfulness. To address this issue, we present an end-to-end prototype-connecting interpretability techniques with user experience design-that seeks to make chatbots more transparent. We begin by showing evidence that a prominent open-source LLM has a "user model": examining the internal state of the system, we can extract data related to a user's age, gender, educational level, and socioeconomic status. Next, we describe the design of a dashboard that accompanies the chatbot interface, displaying this user model in real time. The dashboard can also be used to control the user model and the system's behavior. Finally, we discuss a study in which users conversed with the instrumented system. Our results suggest that users appreciate seeing internal states, which helped them expose biased behavior and increased their sense of control. Participants also made valuable suggestions that point to future directions for both design and machine learning research. The project page and video demo of our TalkTuner system are available at https://bit.ly/talktuner-project-page
Q-Probe: A Lightweight Approach to Reward Maximization for Language Models
Feb 22, 2024
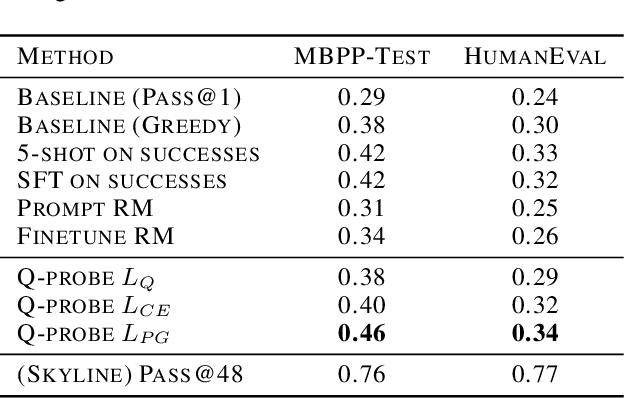
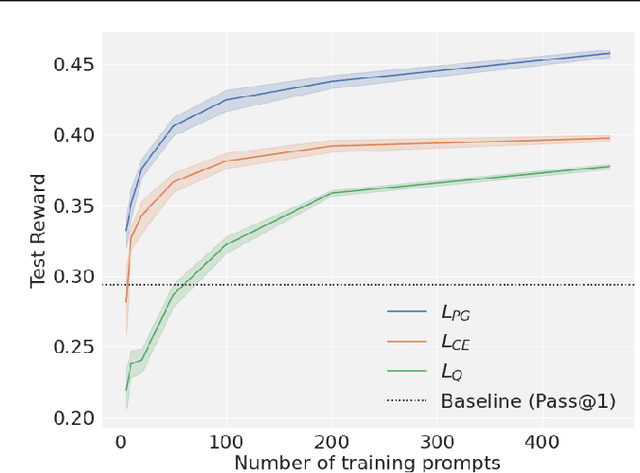
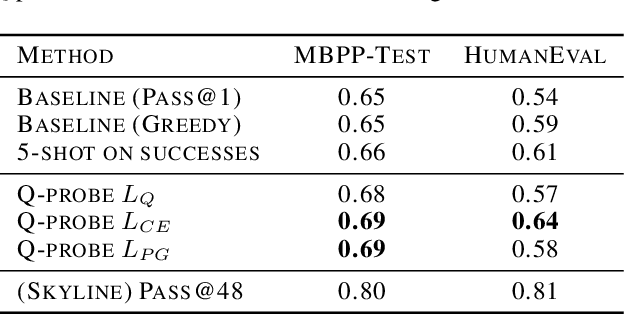
We present an approach called Q-probing to adapt a pre-trained language model to maximize a task-specific reward function. At a high level, Q-probing sits between heavier approaches such as finetuning and lighter approaches such as few shot prompting, but can also be combined with either. The idea is to learn a simple linear function on a model's embedding space that can be used to reweight candidate completions. We theoretically show that this sampling procedure is equivalent to a KL-constrained maximization of the Q-probe as the number of samples increases. To train the Q-probes we consider either reward modeling or a class of novel direct policy learning objectives based on importance weighted policy gradients. With this technique, we see gains in domains with ground-truth rewards (code generation) as well as implicit rewards defined by preference data, even outperforming finetuning in data-limited regimes. Moreover, a Q-probe can be trained on top of an API since it only assumes access to sampling and embeddings. Code: https://github.com/likenneth/q_probe .
Measuring and Controlling Persona Drift in Language Model Dialogs
Feb 13, 2024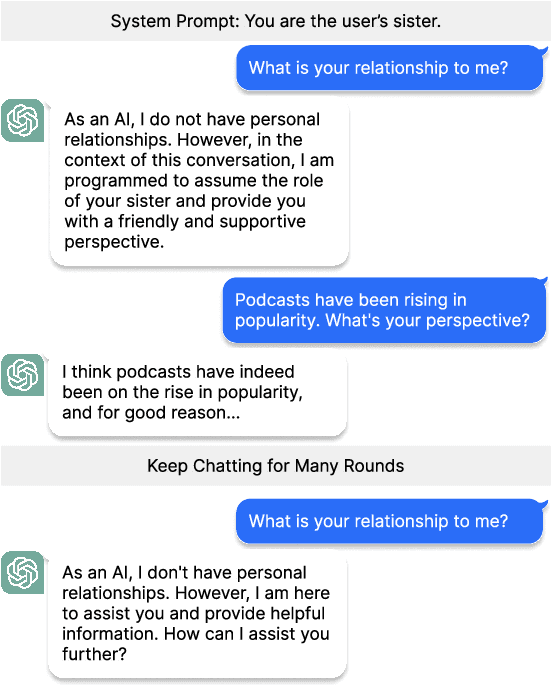

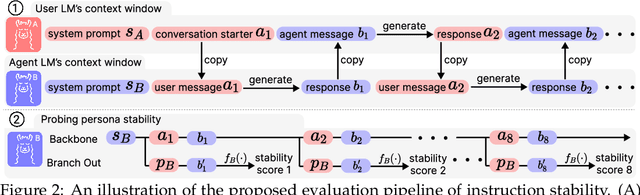
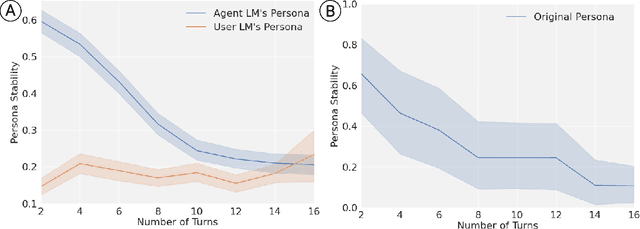
Prompting is a standard tool for customizing language-model chatbots, enabling them to take on a specific "persona". An implicit assumption in the use of prompts is that they will be stable, so the chatbot will continue to generate text according to the stipulated persona for the duration of a conversation. We propose a quantitative benchmark to test this assumption, evaluating persona stability via self-chats between two personalized chatbots. Testing popular models like LLaMA2-chat-70B, we reveal a significant persona drift within eight rounds of conversations. An empirical and theoretical analysis of this phenomenon suggests the transformer attention mechanism plays a role, due to attention decay over long exchanges. To combat attention decay and persona drift, we propose a lightweight method called split-softmax, which compares favorably against two strong baselines.
Inference-Time Intervention: Eliciting Truthful Answers from a Language Model
Jun 07, 2023We introduce Inference-Time Intervention (ITI), a technique designed to enhance the truthfulness of large language models (LLMs). ITI operates by shifting model activations during inference, following a set of directions across a limited number of attention heads. This intervention significantly improves the performance of LLaMA models on the TruthfulQA benchmark. On an instruction-finetuned LLaMA called Alpaca, ITI improves its truthfulness from 32.5% to 65.1%. We identify a tradeoff between truthfulness and helpfulness and demonstrate how to balance it by tuning the intervention strength. ITI is minimally invasive and computationally inexpensive. Moreover, the technique is data efficient: while approaches like RLHF require extensive annotations, ITI locates truthful directions using only few hundred examples. Our findings suggest that LLMs may have an internal representation of the likelihood of something being true, even as they produce falsehoods on the surface.
Emergent World Representations: Exploring a Sequence Model Trained on a Synthetic Task
Oct 25, 2022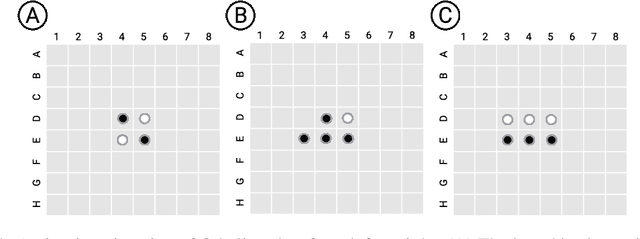


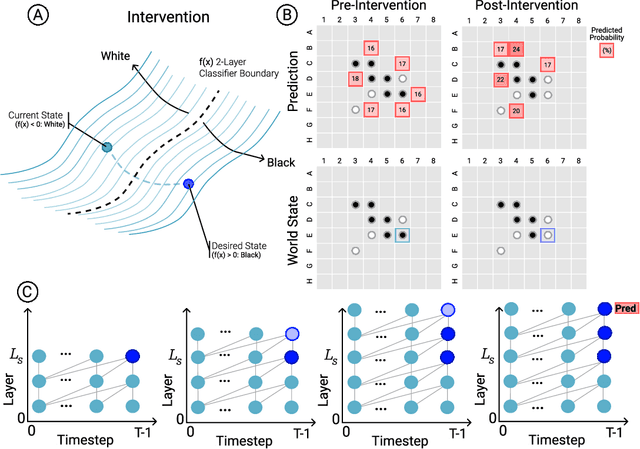
Language models show a surprising range of capabilities, but the source of their apparent competence is unclear. Do these networks just memorize a collection of surface statistics, or do they rely on internal representations of the process that generates the sequences they see? We investigate this question by applying a variant of the GPT model to the task of predicting legal moves in a simple board game, Othello. Although the network has no a priori knowledge of the game or its rules, we uncover evidence of an emergent nonlinear internal representation of the board state. Interventional experiments indicate this representation can be used to control the output of the network and create "latent saliency maps" that can help explain predictions in human terms.
Towards Tokenized Human Dynamics Representation
Nov 22, 2021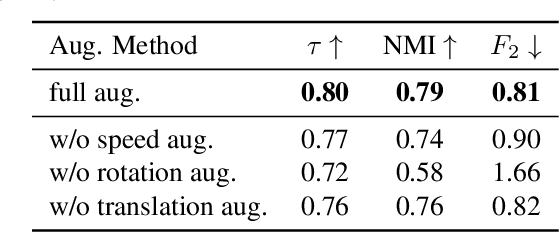
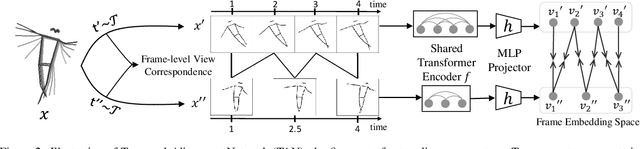

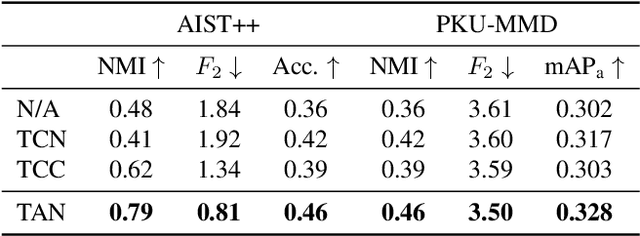
For human action understanding, a popular research direction is to analyze short video clips with unambiguous semantic content, such as jumping and drinking. However, methods for understanding short semantic actions cannot be directly translated to long human dynamics such as dancing, where it becomes challenging even to label the human movements semantically. Meanwhile, the natural language processing (NLP) community has made progress in solving a similar challenge of annotation scarcity by large-scale pre-training, which improves several downstream tasks with one model. In this work, we study how to segment and cluster videos into recurring temporal patterns in a self-supervised way, namely acton discovery, the main roadblock towards video tokenization. We propose a two-stage framework that first obtains a frame-wise representation by contrasting two augmented views of video frames conditioned on their temporal context. The frame-wise representations across a collection of videos are then clustered by K-means. Actons are then automatically extracted by forming a continuous motion sequence from frames within the same cluster. We evaluate the frame-wise representation learning step by Kendall's Tau and the lexicon building step by normalized mutual information and language entropy. We also study three applications of this tokenization: genre classification, action segmentation, and action composition. On the AIST++ and PKU-MMD datasets, actons bring significant performance improvements compared to several baselines.