 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning a Dashboard for Transparency and Control of Conversational AI
Jun 12, 2024



Conversational LLMs function as black box systems, leaving users guessing about why they see the output they do. This lack of transparency is potentially problematic, especially given concerns around bias and truthfulness. To address this issue, we present an end-to-end prototype-connecting interpretability techniques with user experience design-that seeks to make chatbots more transparent. We begin by showing evidence that a prominent open-source LLM has a "user model": examining the internal state of the system, we can extract data related to a user's age, gender, educational level, and socioeconomic status. Next, we describe the design of a dashboard that accompanies the chatbot interface, displaying this user model in real time. The dashboard can also be used to control the user model and the system's behavior. Finally, we discuss a study in which users conversed with the instrumented system. Our results suggest that users appreciate seeing internal states, which helped them expose biased behavior and increased their sense of control. Participants also made valuable suggestions that point to future directions for both design and machine learning research. The project page and video demo of our TalkTuner system are available at https://bit.ly/talktuner-project-page
AttentionViz: A Global View of Transformer Attention
May 04, 2023



Transformer models are revolutionizing machine learning, but their inner workings remain mysterious. In this work, we present a new visualization technique designed to help researchers understand the self-attention mechanism in transformers that allows these models to learn rich, contextual relationships between elements of a sequence. The main idea behind our method is to visualize a joint embedding of the query and key vectors used by transformer models to compute attention. Unlike previous attention visualization techniques, our approach enables the analysis of global patterns across multiple input sequences. We create an interactive visualization tool, AttentionViz, based on these joint query-key embeddings, and use it to study attention mechanisms in both language and vision transformers. We demonstrate the utility of our approach in improving model understanding and offering new insights about query-key interactions through several application scenarios and expert feedback.
GestureLens: Visual Analysis of Gestures in Presentation Videos
Apr 23, 2022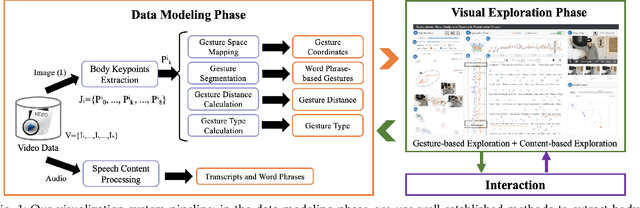
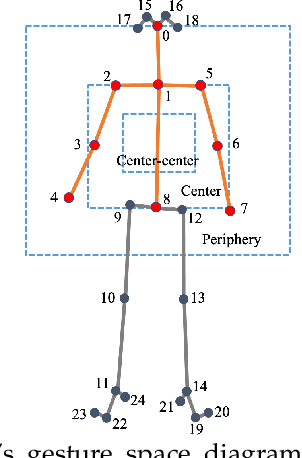
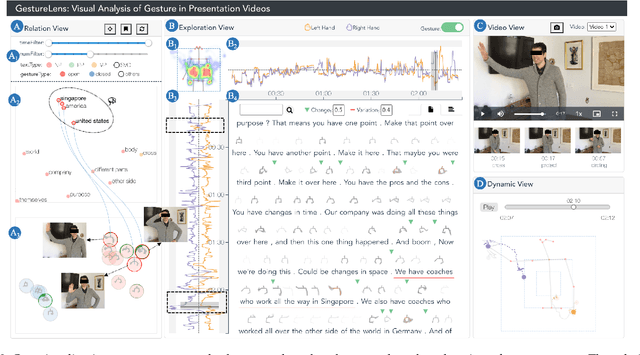
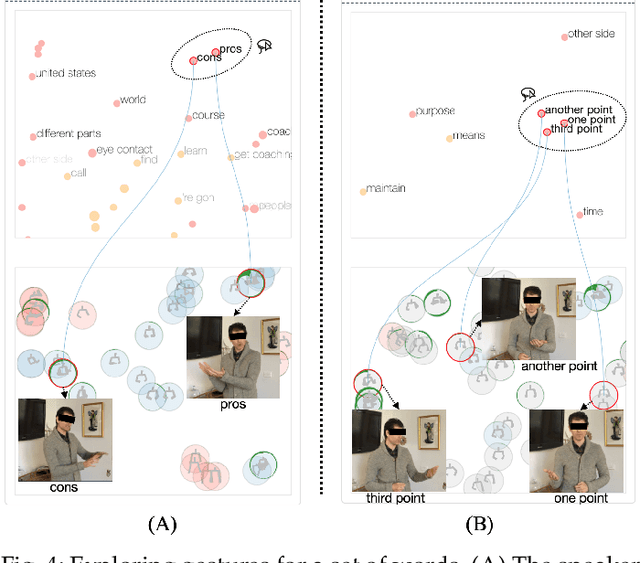
Appropriate gestures can enhance message delivery and audience engagement in both daily communication and public presentations. In this paper, we contribute a visual analytic approach that assists professional public speaking coaches in improving their practice of gesture training through analyzing presentation videos. Manually checking and exploring gesture usage in the presentation videos is often tedious and time-consuming. There lacks an efficient method to help users conduct gesture exploration, which is challenging due to the intrinsically temporal evolution of gestures and their complex correlation to speech content. In this paper, we propose GestureLens, a visual analytics system to facilitate gesture-based and content-based exploration of gesture usage in presentation videos. Specifically, the exploration view enables users to obtain a quick overview of the spatial and temporal distributions of gestures. The dynamic hand movements are firstly aggregated through a heatmap in the gesture space for uncovering spatial patterns, and then decomposed into two mutually perpendicular timelines for revealing temporal patterns. The relation view allows users to explicitly explore the correlation between speech content and gestures by enabling linked analysis and intuitive glyph designs. The video view and dynamic view show the context and overall dynamic movement of the selected gestures, respectively. Two usage scenarios and expert interviews with professional presentation coaches demonstrate the effectiveness and usefulness of GestureLens in facilitating gesture exploration and analysis of presentation videos.
VoiceCoach: Interactive Evidence-based Training for Voice Modulation Skills in Public Speaking
Jan 22, 2020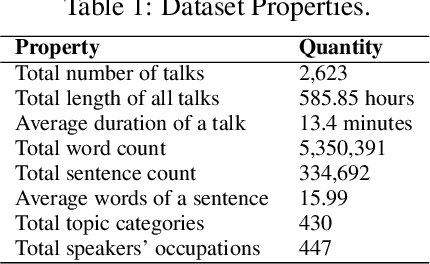
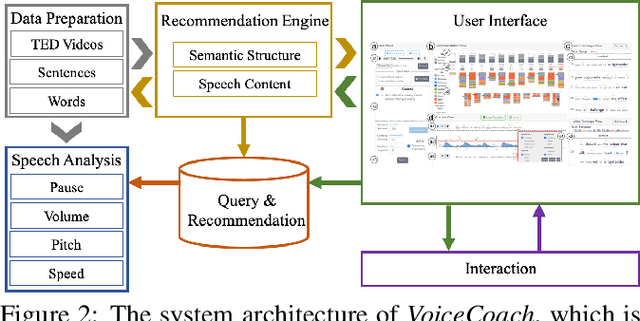

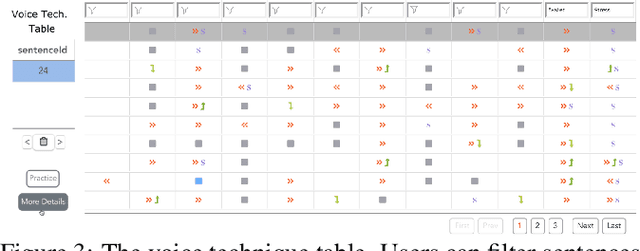
The modulation of voice properties, such as pitch, volume, and speed, is crucial for delivering a successful public speech. However, it is challenging to master different voice modulation skills. Though many guidelines are available, they are often not practical enough to be applied in different public speaking situations, especially for novice speakers. We present VoiceCoach, an interactive evidence-based approach to facilitate the effective training of voice modulation skills. Specifically, we have analyzed the voice modulation skills from 2623 high-quality speeches (i.e., TED Talks) and use them as the benchmark dataset. Given a voice input, VoiceCoach automatically recommends good voice modulation examples from the dataset based on the similarity of both sentence structures and voice modulation skills. Immediate and quantitative visual feedback is provided to guide further improvement. The expert interviews and the user study provide support for the effectiveness and usability of VoiceCoach.
EmoCo: Visual Analysis of Emotion Coherence in Presentation Videos
Jul 29, 2019
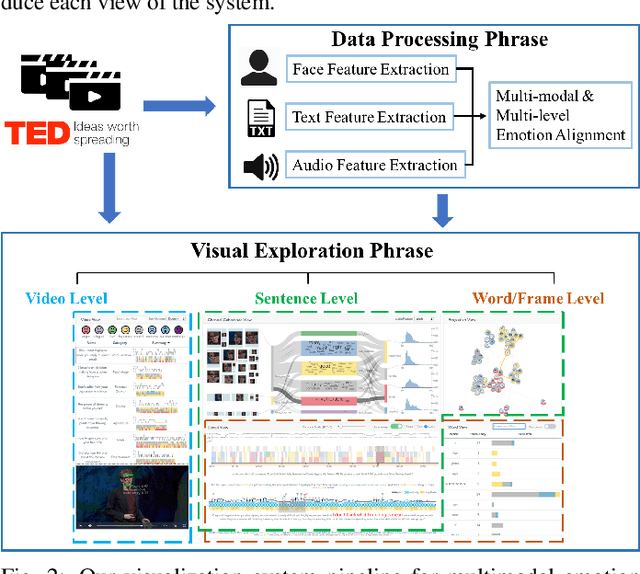

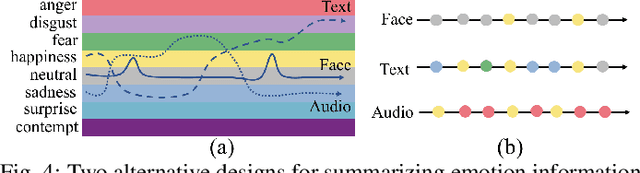
Emotions play a key role in human communication and public presentations. Human emotions are usually expressed through multiple modalities. Therefore, exploring multimodal emotions and their coherence is of great value for understanding emotional expressions in presentations and improving presentation skills. However, manually watching and studying presentation videos is often tedious and time-consuming. There is a lack of tool support to help conduct an efficient and in-depth multi-level analysis. Thus, in this paper, we introduce EmoCo, an interactive visual analytics system to facilitate efficient analysis of emotion coherence across facial, text, and audio modalities in presentation videos. Our visualization system features a channel coherence view and a sentence clustering view that together enable users to obtain a quick overview of emotion coherence and its temporal evolution. In addition, a detail view and word view enable detailed exploration and comparison from the sentence level and word level, respectively. We thoroughly evaluate the proposed system and visualization techniques through two usage scenarios based on TED Talk videos and interviews with two domain experts. The results demonstrate the effectiveness of our system in gaining insights into emotion coherence in presentations.