 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialogue Action Tokens: Steering Language Models in Goal-Directed Dialogue with a Multi-Turn Planner
Paper and Code


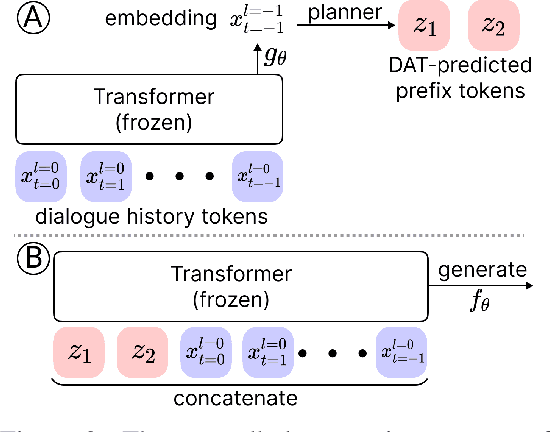
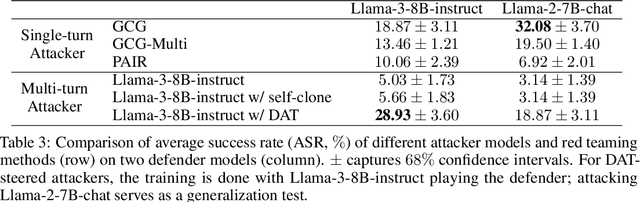
We present an approach called Dialogue Action Tokens (DAT) that adapts language model agents to plan goal-directed dialogues. The core idea is to treat each utterance as an action, thereby converting dialogues into games where existing approaches such as reinforcement learning can be applied. Specifically, we freeze a pretrained language model and train a small planner model that predicts a continuous action vector, used for controlled generation in each round. This design avoids the problem of language degradation under reward optimization. When evaluated on the Sotopia platform for social simulations, the DAT-steered LLaMA model surpasses GPT-4's performance. We also apply DAT to steer an attacker language model in a novel multi-turn red-teaming setting, revealing a potential new attack surface.