 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQ-Probe: A Lightweight Approach to Reward Maximization for Language Models
Paper and Code

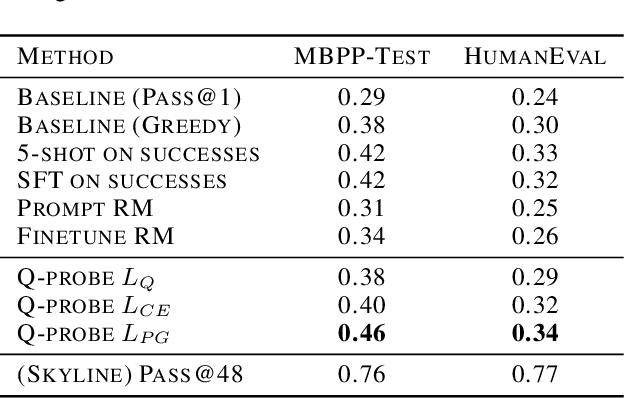
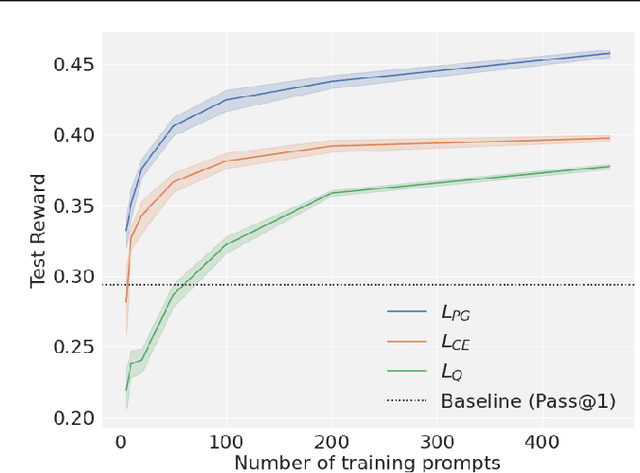
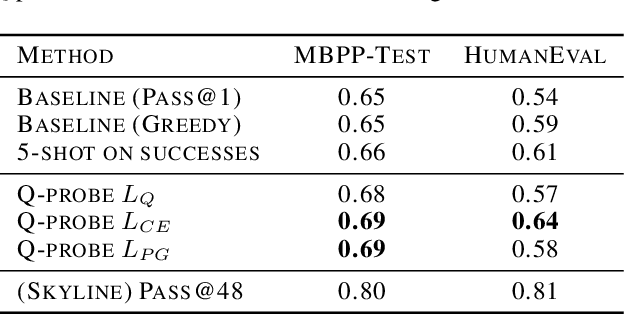
We present an approach called Q-probing to adapt a pre-trained language model to maximize a task-specific reward function. At a high level, Q-probing sits between heavier approaches such as finetuning and lighter approaches such as few shot prompting, but can also be combined with either. The idea is to learn a simple linear function on a model's embedding space that can be used to reweight candidate completions. We theoretically show that this sampling procedure is equivalent to a KL-constrained maximization of the Q-probe as the number of samples increases. To train the Q-probes we consider either reward modeling or a class of novel direct policy learning objectives based on importance weighted policy gradients. With this technique, we see gains in domains with ground-truth rewards (code generation) as well as implicit rewards defined by preference data, even outperforming finetuning in data-limited regimes. Moreover, a Q-probe can be trained on top of an API since it only assumes access to sampling and embeddings. Code: https://github.com/likenneth/q_probe .