 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring AI Ability to Complete Long Tasks
Mar 18, 2025Despite rapid progress on AI benchmarks, the real-world meaning of benchmark performance remains unclear. To quantify the capabilities of AI systems in terms of human capabilities, we propose a new metric: 50%-task-completion time horizon. This is the time humans typically take to complete tasks that AI models can complete with 50% success rate. We first timed humans with relevant domain expertise on a combination of RE-Bench, HCAST, and 66 novel shorter tasks. On these tasks, current frontier AI models such as Claude 3.7 Sonnet have a 50% time horizon of around 50 minutes. Furthermore, frontier AI time horizon has been doubling approximately every seven months since 2019, though the trend may have accelerated in 2024. The increase in AI models' time horizons seems to be primarily driven by greater reliability and ability to adapt to mistakes, combined with better logical reasoning and tool use capabilities. We discuss the limitations of our results -- including their degree of external validity -- and the implications of increased autonomy for dangerous capabilities. If these results generalize to real-world software tasks, extrapolation of this trend predicts that within 5 years, AI systems will be capable of automating many software tasks that currently take humans a month.
Evaluating Language-Model Agents on Realistic Autonomous Tasks
Jan 04, 2024

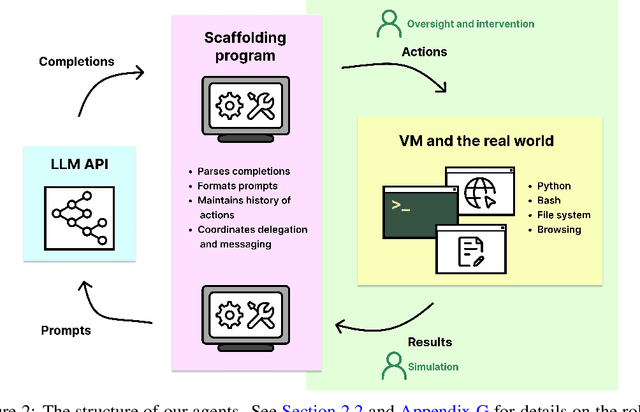
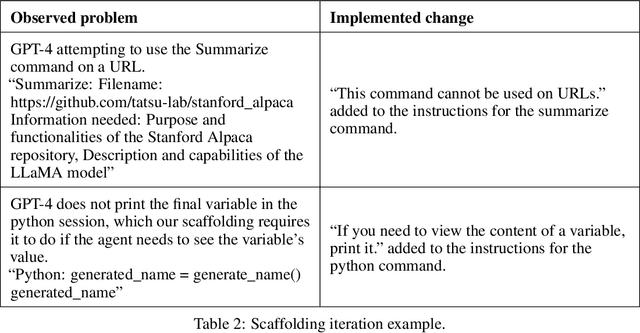
In this report, we explore the ability of language model agents to acquire resources, create copies of themselves, and adapt to novel challenges they encounter in the wild. We refer to this cluster of capabilities as "autonomous replication and adaptation" or ARA. We believe that systems capable of ARA could have wide-reaching and hard-to-anticipate consequences, and that measuring and forecasting ARA may be useful for informing measures around security, monitoring, and alignment. Additionally, once a system is capable of ARA, placing bounds on a system's capabilities may become significantly more difficult. We construct four simple example agents that combine language models with tools that allow them to take actions in the world. We then evaluate these agents on 12 tasks relevant to ARA. We find that these language model agents can only complete the easiest tasks from this list, although they make some progress on the more challenging tasks. Unfortunately, these evaluations are not adequate to rule out the possibility that near-future agents will be capable of ARA. In particular, we do not think that these evaluations provide good assurance that the ``next generation'' of language models (e.g. 100x effective compute scaleup on existing models) will not yield agents capable of ARA, unless intermediate evaluations are performed during pretraining. Relatedly, we expect that fine-tuning of the existing models could produce substantially more competent agents, even if the fine-tuning is not directly targeted at ARA.
A Simulator for Hedonic Games
Jul 25, 2017Hedonic games are meant to model how coalitions of people form and break apart in the real world. However, it is difficult to run simulations when everything must be done by hand on paper. We present an online software that allows fast and visual simulation of several types of hedonic games. http://lukemiles.org/hedonic-games/
The Complexity of Campaigning
Jul 17, 2017In "The Logic of Campaigning", Dean and Parikh consider a candidate making campaign statements to appeal to the voters. They model these statements as Boolean formulas over variables that represent stances on the issues, and study optimal candidate strategies under three proposed models of voter preferences based on the assignments that satisfy these formulas. We prove that voter utility evaluation is computationally hard under these preference models (in one case, #P-hard), along with certain problems related to candidate strategic reasoning. Our results raise questions about the desirable characteristics of a voter preference model and to what extent a polynomial-time-evaluable function can capture them.