 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstant Continual Learning of Neural Radiance Fields
Sep 06, 2023



Neural radiance fields (NeRFs) have emerged as an effective method for novel-view synthesis and 3D scene reconstruction. However, conventional training methods require access to all training views during scene optimization. This assumption may be prohibitive in continual learning scenarios, where new data is acquired in a sequential manner and a continuous update of the NeRF is desired, as in automotive or remote sensing applications. When naively trained in such a continual setting, traditional scene representation frameworks suffer from catastrophic forgetting, where previously learned knowledge is corrupted after training on new data. Prior works in alleviating forgetting with NeRFs suffer from low reconstruction quality and high latency, making them impractical for real-world application. We propose a continual learning framework for training NeRFs that leverages replay-based methods combined with a hybrid explicit--implicit scene representation. Our method outperforms previous methods in reconstruction quality when trained in a continual setting, while having the additional benefit of being an order of magnitude faster.
Dynamic Advisor-Based Ensemble : Case Study in Stock Trend Prediction of Critical Metal Companies
Aug 15, 2018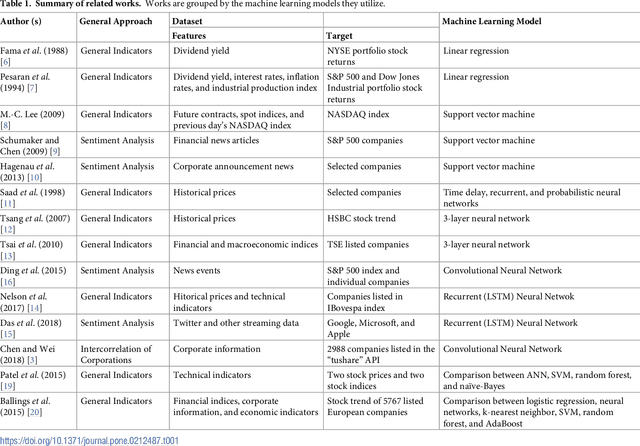
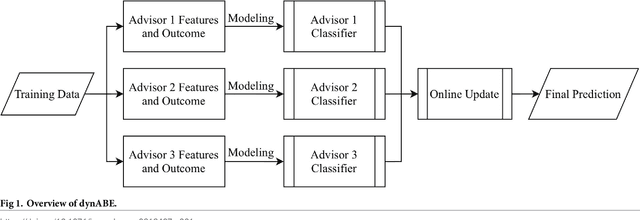
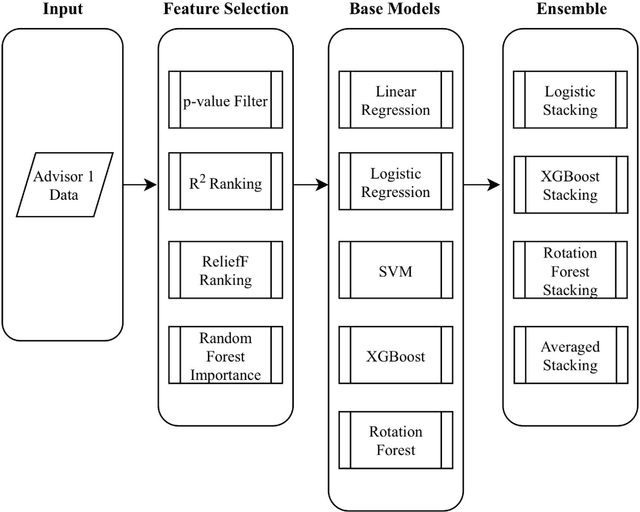
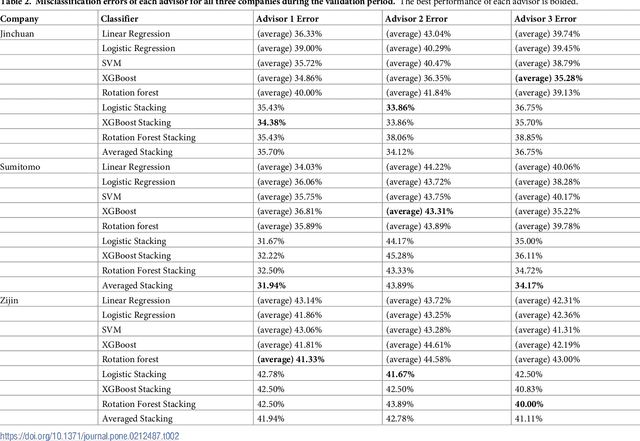
The demand for metals by modern technology has been shifting from common base metals to a variety of minor metals, such as cobalt or indium. The industrial importance and limited geological availability of some minor metals have led to them being considered more "critical," and there is a growing investment interest in such critical metals and their producing companies. In this research, we create a novel framework, Dynamic Advisor-Based Ensemble (dynABE), for stock prediction and use critical metal companies as case study. dynABE uses domain knowledge to diversify the feature set by dividing them into different "advisors." creates high-level ensembles with complex base models for each advisor, and combines the advisors together dynamically during validation with a novel and effective online update strategy. We test dynABE on three cobalt-related companies, and it achieves the best-case misclassification error of 31.12% and excess return of 477% compared to the stock itself in a year and a half. In addition to presenting an effective stock prediction model with decent profitabilities, this research further analyzes dynABE to visualize how it works in practice, which also yields discoveries of its interesting behaviors when processing time-series data.