 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlterbute: Editing Intrinsic Attributes of Objects in Images
Jan 15, 2026We introduce Alterbute, a diffusion-based method for editing an object's intrinsic attributes in an image. We allow changing color, texture, material, and even the shape of an object, while preserving its perceived identity and scene context. Existing approaches either rely on unsupervised priors that often fail to preserve identity or use overly restrictive supervision that prevents meaningful intrinsic variations. Our method relies on: (i) a relaxed training objective that allows the model to change both intrinsic and extrinsic attributes conditioned on an identity reference image, a textual prompt describing the target intrinsic attributes, and a background image and object mask defining the extrinsic context. At inference, we restrict extrinsic changes by reusing the original background and object mask, thereby ensuring that only the desired intrinsic attributes are altered; (ii) Visual Named Entities (VNEs) - fine-grained visual identity categories (e.g., ''Porsche 911 Carrera'') that group objects sharing identity-defining features while allowing variation in intrinsic attributes. We use a vision-language model to automatically extract VNE labels and intrinsic attribute descriptions from a large public image dataset, enabling scalable, identity-preserving supervision. Alterbute outperforms existing methods on identity-preserving object intrinsic attribute editing.
ObjectMate: A Recurrence Prior for Object Insertion and Subject-Driven Generation
Dec 11, 2024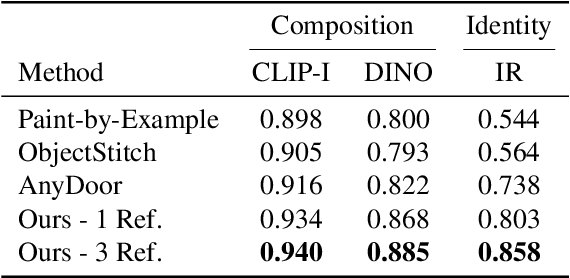

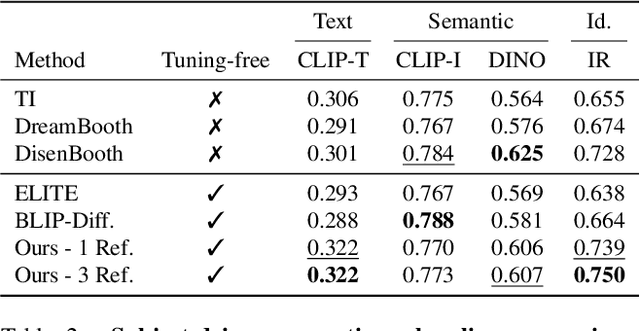
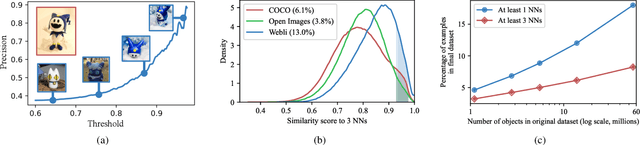
This paper introduces a tuning-free method for both object insertion and subject-driven generation. The task involves composing an object, given multiple views, into a scene specified by either an image or text. Existing methods struggle to fully meet the task's challenging objectives: (i) seamlessly composing the object into the scene with photorealistic pose and lighting, and (ii) preserving the object's identity. We hypothesize that achieving these goals requires large scale supervision, but manually collecting sufficient data is simply too expensive. The key observation in this paper is that many mass-produced objects recur across multiple images of large unlabeled datasets, in different scenes, poses, and lighting conditions. We use this observation to create massive supervision by retrieving sets of diverse views of the same object. This powerful paired dataset enables us to train a straightforward text-to-image diffusion architecture to map the object and scene descriptions to the composited image. We compare our method, ObjectMate, with state-of-the-art methods for object insertion and subject-driven generation, using a single or multiple references. Empirically, ObjectMate achieves superior identity preservation and more photorealistic composition. Differently from many other multi-reference methods, ObjectMate does not require slow test-time tuning.
ObjectDrop: Bootstrapping Counterfactuals for Photorealistic Object Removal and Insertion
Mar 27, 2024



Diffusion models have revolutionized image editing but often generate images that violate physical laws, particularly the effects of objects on the scene, e.g., occlusions, shadows, and reflections. By analyzing the limitations of self-supervised approaches, we propose a practical solution centered on a \q{counterfactual} dataset. Our method involves capturing a scene before and after removing a single object, while minimizing other changes. By fine-tuning a diffusion model on this dataset, we are able to not only remove objects but also their effects on the scene. However, we find that applying this approach for photorealistic object insertion requires an impractically large dataset. To tackle this challenge, we propose bootstrap supervision; leveraging our object removal model trained on a small counterfactual dataset, we synthetically expand this dataset considerably. Our approach significantly outperforms prior methods in photorealistic object removal and insertion, particularly at modeling the effects of objects on the scene.
Classifying Nodes in Graphs without GNNs
Feb 08, 2024Graph neural networks (GNNs) are the dominant paradigm for classifying nodes in a graph, but they have several undesirable attributes stemming from their message passing architecture. Recently, distillation methods succeeded in eliminating the use of GNNs at test time but they still require them during training. We perform a careful analysis of the role that GNNs play in distillation methods. This analysis leads us to propose a fully GNN-free approach for node classification, not requiring them at train or test time. Our method consists of three key components: smoothness constraints, pseudo-labeling iterations and neighborhood-label histograms. Our final approach can match the state-of-the-art accuracy on standard popular benchmarks such as citation and co-purchase networks, without training a GNN.