 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObjectMate: A Recurrence Prior for Object Insertion and Subject-Driven Generation
Dec 11, 2024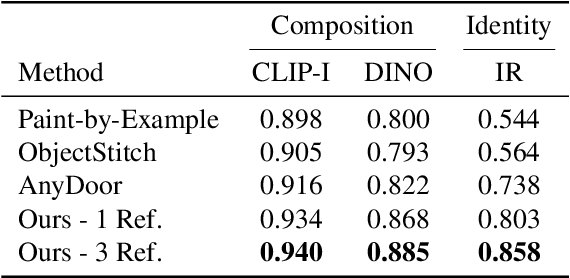

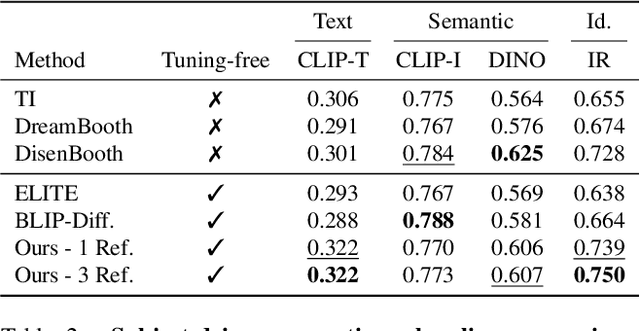
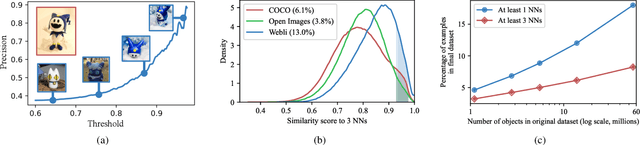
This paper introduces a tuning-free method for both object insertion and subject-driven generation. The task involves composing an object, given multiple views, into a scene specified by either an image or text. Existing methods struggle to fully meet the task's challenging objectives: (i) seamlessly composing the object into the scene with photorealistic pose and lighting, and (ii) preserving the object's identity. We hypothesize that achieving these goals requires large scale supervision, but manually collecting sufficient data is simply too expensive. The key observation in this paper is that many mass-produced objects recur across multiple images of large unlabeled datasets, in different scenes, poses, and lighting conditions. We use this observation to create massive supervision by retrieving sets of diverse views of the same object. This powerful paired dataset enables us to train a straightforward text-to-image diffusion architecture to map the object and scene descriptions to the composited image. We compare our method, ObjectMate, with state-of-the-art methods for object insertion and subject-driven generation, using a single or multiple references. Empirically, ObjectMate achieves superior identity preservation and more photorealistic composition. Differently from many other multi-reference methods, ObjectMate does not require slow test-time tuning.
On the Origin of Llamas: Model Tree Heritage Recovery
May 28, 2024



The rapid growth of neural network models shared on the internet has made model weights an important data modality. However, this information is underutilized as the weights are uninterpretable, and publicly available models are disorganized. Inspired by Darwin's tree of life, we define the Model Tree which describes the origin of models i.e., the parent model that was used to fine-tune the target model. Similarly to the natural world, the tree structure is unknown. In this paper, we introduce the task of Model Tree Heritage Recovery (MoTHer Recovery) for discovering Model Trees in the ever-growing universe of neural networks. Our hypothesis is that model weights encode this information, the challenge is to decode the underlying tree structure given the weights. Beyond the immediate application of model authorship attribution, MoTHer recovery holds exciting long-term applications akin to indexing the internet by search engines. Practically, for each pair of models, this task requires: i) determining if they are related, and ii) establishing the direction of the relationship. We find that certain distributional properties of the weights evolve monotonically during training, which enables us to classify the relationship between two given models. MoTHer recovery reconstructs entire model hierarchies, represented by a directed tree, where a parent model gives rise to multiple child models through additional training. Our approach successfully reconstructs complex Model Trees, as well as the structure of "in-the-wild" model families such as Llama 2 and Stable Diffusion.
Distilling Datasets Into Less Than One Image
Mar 18, 2024



Dataset distillation aims to compress a dataset into a much smaller one so that a model trained on the distilled dataset achieves high accuracy. Current methods frame this as maximizing the distilled classification accuracy for a budget of K distilled images-per-class, where K is a positive integer. In this paper, we push the boundaries of dataset distillation, compressing the dataset into less than an image-per-class. It is important to realize that the meaningful quantity is not the number of distilled images-per-class but the number of distilled pixels-per-dataset. We therefore, propose Poster Dataset Distillation (PoDD), a new approach that distills the entire original dataset into a single poster. The poster approach motivates new technical solutions for creating training images and learnable labels. Our method can achieve comparable or better performance with less than an image-per-class compared to existing methods that use one image-per-class. Specifically, our method establishes a new state-of-the-art performance on CIFAR-10, CIFAR-100, and CUB200 using as little as 0.3 images-per-class.