 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHallucinating Pose-Compatible Scenes
Paper and Code

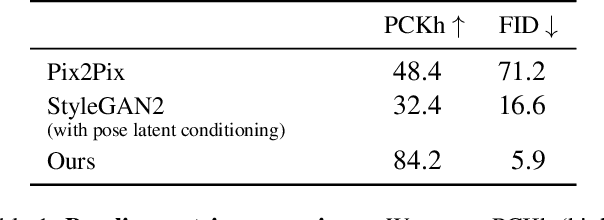

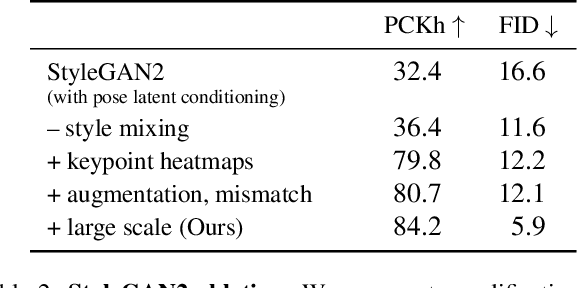
What does human pose tell us about a scene? We propose a task to answer this question: given human pose as input, hallucinate a compatible scene. Subtle cues captured by human pose -- action semantics, environment affordances, object interactions -- provide surprising insight into which scenes are compatible. We present a large-scale generative adversarial network for pose-conditioned scene generation. We significantly scale the size and complexity of training data, curating a massive meta-dataset containing over 19 million frames of humans in everyday environments. We double the capacity of our model with respect to StyleGAN2 to handle such complex data, and design a pose conditioning mechanism that drives our model to learn the nuanced relationship between pose and scene. We leverage our trained model for various applications: hallucinating pose-compatible scene(s) with or without humans, visualizing incompatible scenes and poses, placing a person from one generated image into another scene, and animating pose. Our model produces diverse samples and outperforms pose-conditioned StyleGAN2 and Pix2Pix baselines in terms of accurate human placement (percent of correct keypoints) and image quality (Frechet inception distance).