 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Random and Cyclic Effects in Time-Lapse Sequences
Jul 04, 2022
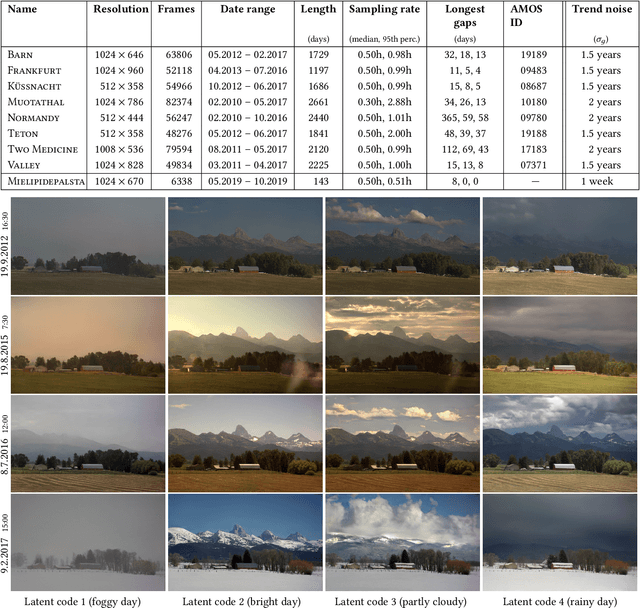


Time-lapse image sequences offer visually compelling insights into dynamic processes that are too slow to observe in real time. However, playing a long time-lapse sequence back as a video often results in distracting flicker due to random effects, such as weather, as well as cyclic effects, such as the day-night cycle. We introduce the problem of disentangling time-lapse sequences in a way that allows separate, after-the-fact control of overall trends, cyclic effects, and random effects in the images, and describe a technique based on data-driven generative models that achieves this goal. This enables us to "re-render" the sequences in ways that would not be possible with the input images alone. For example, we can stabilize a long sequence to focus on plant growth over many months, under selectable, consistent weather. Our approach is based on Generative Adversarial Networks (GAN) that are conditioned with the time coordinate of the time-lapse sequence. Our architecture and training procedure are designed so that the networks learn to model random variations, such as weather, using the GAN's latent space, and to disentangle overall trends and cyclic variations by feeding the conditioning time label to the model using Fourier features with specific frequencies. We show that our models are robust to defects in the training data, enabling us to amend some of the practical difficulties in capturing long time-lapse sequences, such as temporary occlusions, uneven frame spacing, and missing frames.
Alias-Free Generative Adversarial Networks
Jul 15, 2021
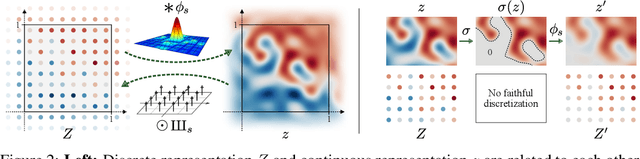
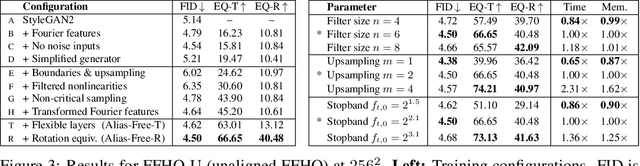
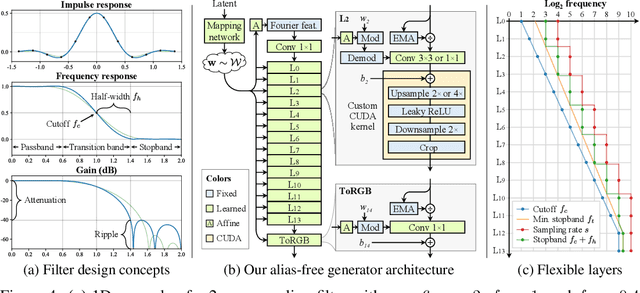
We observe that despite their hierarchical convolutional nature, the synthesis process of typical generative adversarial networks depends on absolute pixel coordinates in an unhealthy manner. This manifests itself as, e.g., detail appearing to be glued to image coordinates instead of the surfaces of depicted objects. We trace the root cause to careless signal processing that causes aliasing in the generator network. Interpreting all signals in the network as continuous, we derive generally applicable, small architectural changes that guarantee that unwanted information cannot leak into the hierarchical synthesis process. The resulting networks match the FID of StyleGAN2 but differ dramatically in their internal representations, and they are fully equivariant to translation and rotation even at subpixel scales. Our results pave the way for generative models better suited for video and animation.
GANSpace: Discovering Interpretable GAN Controls
Apr 06, 2020
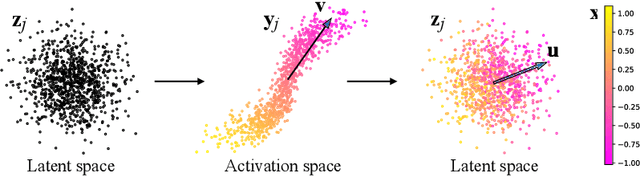


This paper describes a simple technique to analyze Generative Adversarial Networks (GANs) and create interpretable controls for image synthesis, such as change of viewpoint, aging, lighting, and time of day. We identify important latent directions based on Principal Components Analysis (PCA) applied in activation space. Then, we show that interpretable edits can be defined based on layer-wise application of these edit directions. Moreover, we show that BigGAN can be controlled with layer-wise inputs in a StyleGAN-like manner. A user may identify a large number of interpretable controls with these mechanisms. We demonstrate results on GANs from various datasets.
E-LPIPS: Robust Perceptual Image Similarity via Random Transformation Ensembles
Jun 11, 2019


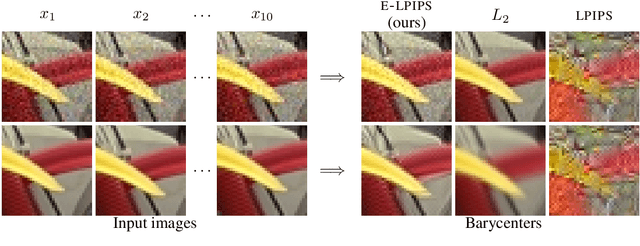
It has been recently shown that the hidden variables of convolutional neural networks make for an efficient perceptual similarity metric that accurately predicts human judgment on relative image similarity assessment. First, we show that such learned perceptual similarity metrics (LPIPS) are susceptible to adversarial attacks that dramatically contradict human visual similarity judgment. While this is not surprising in light of neural networks' well-known weakness to adversarial perturbations, we proceed to show that self-ensembling with an infinite family of random transformations of the input --- a technique known not to render classification networks robust --- is enough to turn the metric robust against attack, while retaining predictive power on human judgments. Finally, we study the geometry imposed by our our novel self-ensembled metric (E-LPIPS) on the space of natural images. We find evidence of "perceptual convexity" by showing that convex combinations of similar-looking images retain appearance, and that discrete geodesics yield meaningful frame interpolation and texture morphing, all without explicit correspondences.