 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoctor-RAG: Failure-Aware Repair for Agentic Retrieval-Augmented Generation
Apr 01, 2026Agentic Retrieval-Augmented Generation (Agentic RAG) has become a widely adopted paradigm for multi-hop question answering and complex knowledge reasoning, where retrieval and reasoning are interleaved at inference time. As reasoning trajectories grow longer, failures become increasingly common. Existing approaches typically address such failures by either stopping at diagnostic analysis or rerunning the entire retrieval-reasoning pipeline, which leads to substantial computational overhead and redundant reasoning. In this paper, we propose Doctor-RAG (DR-RAG), a unified diagnose-and-repair framework that corrects failures in Agentic RAG through explicit error localization and prefix reuse, enabling minimal-cost intervention. DR-RAG decomposes failure handling into two consecutive stages: (i) trajectory-level failure diagnosis and localization, which attributes errors to a coverage-gated taxonomy and identifies the earliest failure point in the reasoning trajectory; and (ii) tool-conditioned local repair, which intervenes only at the diagnosed failure point while maximally reusing validated reasoning prefixes and retrieved evidence. By explicitly separating error attribution from correction, DR-RAG enables precise error localization, thereby avoiding expensive full-pipeline reruns and enabling targeted, efficient repair. We evaluate DR-RAG across three multi-hop question answering benchmarks, multiple agentic RAG baselines, and different backbone models. Experimental results demonstrate that DR-RAG substantially improves answer accuracy while significantly reducing reasoning token consumption compared to rerun-based repair strategies.
Fast-Slow Efficient Training for Multimodal Large Language Models via Visual Token Pruning
Feb 03, 2026Multimodal Large Language Models (MLLMs) suffer from severe training inefficiency issue, which is associated with their massive model sizes and visual token numbers. Existing efforts in efficient training focus on reducing model sizes or trainable parameters. Inspired by the success of Visual Token Pruning (VTP) in improving inference efficiency, we are exploring another substantial research direction for efficient training by reducing visual tokens. However, applying VTP at the training stage results in a training-inference mismatch: pruning-trained models perform poorly when inferring on non-pruned full visual token sequences. To close this gap, we propose DualSpeed, a fast-slow framework for efficient training of MLLMs. The fast-mode is the primary mode, which incorporates existing VTP methods as plugins to reduce visual tokens, along with a mode isolator to isolate the model's behaviors. The slow-mode is the auxiliary mode, where the model is trained on full visual sequences to retain training-inference consistency. To boost its training, it further leverages self-distillation to learn from the sufficiently trained fast-mode. Together, DualSpeed can achieve both training efficiency and non-degraded performance. Experiments show DualSpeed accelerates the training of LLaVA-1.5 by 2.1$\times$ and LLaVA-NeXT by 4.0$\times$, retaining over 99% performance. Code: https://github.com/dingkun-zhang/DualSpeed
PruneRAG: Confidence-Guided Query Decomposition Trees for Efficient Retrieval-Augmented Generation
Jan 16, 2026Retrieval-augmented generation (RAG) has become a powerful framework for enhancing large language models in knowledge-intensive and reasoning tasks. However, as reasoning chains deepen or search trees expand, RAG systems often face two persistent failures: evidence forgetting, where retrieved knowledge is not effectively used, and inefficiency, caused by uncontrolled query expansions and redundant retrieval. These issues reveal a critical gap between retrieval and evidence utilization in current RAG architectures. We propose PruneRAG, a confidence-guided query decomposition framework that builds a structured query decomposition tree to perform stable and efficient reasoning. PruneRAG introduces three key mechanisms: adaptive node expansion that regulates tree width and depth, confidence-guided decisions that accept reliable answers and prune uncertain branches, and fine-grained retrieval that extracts entity-level anchors to improve retrieval precision. Together, these components preserve salient evidence throughout multi-hop reasoning while significantly reducing retrieval overhead. To better analyze evidence misuse, we define the Evidence Forgetting Rate as a metric to quantify cases where golden evidence is retrieved but not correctly used. Extensive experiments across various multi-hop QA benchmarks show that PruneRAG achieves superior accuracy and efficiency over state-of-the-art baselines.
MDIT-Bench: Evaluating the Dual-Implicit Toxicity in Large Multimodal Models
May 22, 2025The widespread use of Large Multimodal Models (LMMs) has raised concerns about model toxicity. However, current research mainly focuses on explicit toxicity, with less attention to some more implicit toxicity regarding prejudice and discrimination. To address this limitation, we introduce a subtler type of toxicity named dual-implicit toxicity and a novel toxicity benchmark termed MDIT-Bench: Multimodal Dual-Implicit Toxicity Benchmark. Specifically, we first create the MDIT-Dataset with dual-implicit toxicity using the proposed Multi-stage Human-in-loop In-context Generation method. Based on this dataset, we construct the MDIT-Bench, a benchmark for evaluating the sensitivity of models to dual-implicit toxicity, with 317,638 questions covering 12 categories, 23 subcategories, and 780 topics. MDIT-Bench includes three difficulty levels, and we propose a metric to measure the toxicity gap exhibited by the model across them. In the experiment, we conducted MDIT-Bench on 13 prominent LMMs, and the results show that these LMMs cannot handle dual-implicit toxicity effectively. The model's performance drops significantly in hard level, revealing that these LMMs still contain a significant amount of hidden but activatable toxicity. Data are available at https://github.com/nuo1nuo/MDIT-Bench.
GaussTrap: Stealthy Poisoning Attacks on 3D Gaussian Splatting for Targeted Scene Confusion
Apr 29, 2025As 3D Gaussian Splatting (3DGS) emerges as a breakthrough in scene representation and novel view synthesis, its rapid adoption in safety-critical domains (e.g., autonomous systems, AR/VR) urgently demands scrutiny of potential security vulnerabilities. This paper presents the first systematic study of backdoor threats in 3DGS pipelines. We identify that adversaries may implant backdoor views to induce malicious scene confusion during inference, potentially leading to environmental misperception in autonomous navigation or spatial distortion in immersive environments. To uncover this risk, we propose GuassTrap, a novel poisoning attack method targeting 3DGS models. GuassTrap injects malicious views at specific attack viewpoints while preserving high-quality rendering in non-target views, ensuring minimal detectability and maximizing potential harm. Specifically, the proposed method consists of a three-stage pipeline (attack, stabilization, and normal training) to implant stealthy, viewpoint-consistent poisoned renderings in 3DGS, jointly optimizing attack efficacy and perceptual realism to expose security risks in 3D rendering. Extensive experiments on both synthetic and real-world datasets demonstrate that GuassTrap can effectively embed imperceptible yet harmful backdoor views while maintaining high-quality rendering in normal views, validating its robustness, adaptability, and practical applicability.
Merge then Realign: Simple and Effective Modality-Incremental Continual Learning for Multimodal LLMs
Mar 08, 2025Recent advances in Multimodal Large Language Models (MLLMs) have enhanced their versatility as they integrate a growing number of modalities. Considering the heavy cost of training MLLMs, it is necessary to reuse the existing ones and further extend them to more modalities through Modality-incremental Continual Learning (MCL). However, this often comes with a performance degradation in the previously learned modalities. In this work, we revisit the MCL and investigate a more severe issue it faces in contrast to traditional continual learning, that its degradation comes not only from catastrophic forgetting but also from the misalignment between the modality-agnostic and modality-specific components. To address this problem, we propose an elegantly simple MCL paradigm called "MErge then ReAlign" (MERA). Our method avoids introducing heavy training overhead or modifying the model architecture, hence is easy to deploy and highly reusable in the MLLM community. Extensive experiments demonstrate that, despite the simplicity of MERA, it shows impressive performance, holding up to a 99.84% Backward Relative Gain when extending to four modalities, achieving a nearly lossless MCL performance.
Graph-Enhanced Dual-Stream Feature Fusion with Pre-Trained Model for Acoustic Traffic Monitoring
Dec 26, 2024



Microphone array techniques are widely used in sound source localization and smart city acoustic-based traffic monitoring, but these applications face significant challenges due to the scarcity of labeled real-world traffic audio data and the complexity and diversity of application scenarios. The DCASE Challenge's Task 10 focuses on using multi-channel audio signals to count vehicles (cars or commercial vehicles) and identify their directions (left-to-right or vice versa). In this paper, we propose a graph-enhanced dual-stream feature fusion network (GEDF-Net) for acoustic traffic monitoring, which simultaneously considers vehicle type and direction to improve detection. We propose a graph-enhanced dual-stream feature fusion strategy which consists of a vehicle type feature extraction (VTFE) branch, a vehicle direction feature extraction (VDFE) branch, and a frame-level feature fusion module to combine the type and direction feature for enhanced performance. A pre-trained model (PANNs) is used in the VTFE branch to mitigate data scarcity and enhance the type features, followed by a graph attention mechanism to exploit temporal relationships and highlight important audio events within these features. The frame-level fusion of direction and type features enables fine-grained feature representation, resulting in better detection performance. Experiments demonstrate the effectiveness of our proposed method. GEDF-Net is our submission that achieved 1st place in the DCASE 2024 Challenge Task 10.
A Reference-free Metric for Language-Queried Audio Source Separation using Contrastive Language-Audio Pretraining
Jul 06, 2024



Language-queried audio source separation (LASS) aims to separate an audio source guided by a text query, with the signal-to-distortion ratio (SDR)-based metrics being commonly used to objectively measure the quality of the separated audio. However, the SDR-based metrics require a reference signal, which is often difficult to obtain in real-world scenarios. In addition, with the SDR-based metrics, the content information of the text query is not considered effectively in LASS. This paper introduces a reference-free evaluation metric using a contrastive language-audio pretraining (CLAP) module, termed CLAPScore, which measures the semantic similarity between the separated audio and the text query. Unlike SDR, the proposed CLAPScore metric evaluates the quality of the separated audio based on the content information of the text query, without needing a reference signal. Experimental results show that the CLAPScore metric provides an effective evaluation of the semantic relevance of the separated audio to the text query, as compared to the SDR metric, offering an alternative for the performance evaluation of LASS systems.
KnobTree: Intelligent Database Parameter Configuration via Explainable Reinforcement Learning
Jun 21, 2024Databases are fundamental to contemporary information systems, yet traditional rule-based configuration methods struggle to manage the complexity of real-world applications with hundreds of tunable parameters. Deep reinforcement learning (DRL), which combines perception and decision-making, presents a potential solution for intelligent database configuration tuning. However, due to black-box property of RL-based method, the generated database tuning strategies still face the urgent problem of lack explainability. Besides, the redundant parameters in large scale database always make the strategy learning become unstable. This paper proposes KnobTree, an interpertable framework designed for the optimization of database parameter configuration. In this framework, an interpertable database tuning algorithm based on RL-based differentatial tree is proposed, which building a transparent tree-based model to generate explainable database tuning strategies. To address the problem of large-scale parameters, We also introduce a explainable method for parameter importance assessment, by utilizing Shapley Values to identify parameters that have significant impacts on database performance. Experiments conducted on MySQL and Gbase8s databases have verified exceptional transparency and interpretability of the KnobTree model. The good property makes generated strategies can offer practical guidance to algorithm designers and database administrators. Moreover, our approach also slightly outperforms the existing RL-based tuning algorithms in aspects such as throughput, latency, and processing time.
SVDE: Scalable Value-Decomposition Exploration for Cooperative Multi-Agent Reinforcement Learning
Mar 16, 2023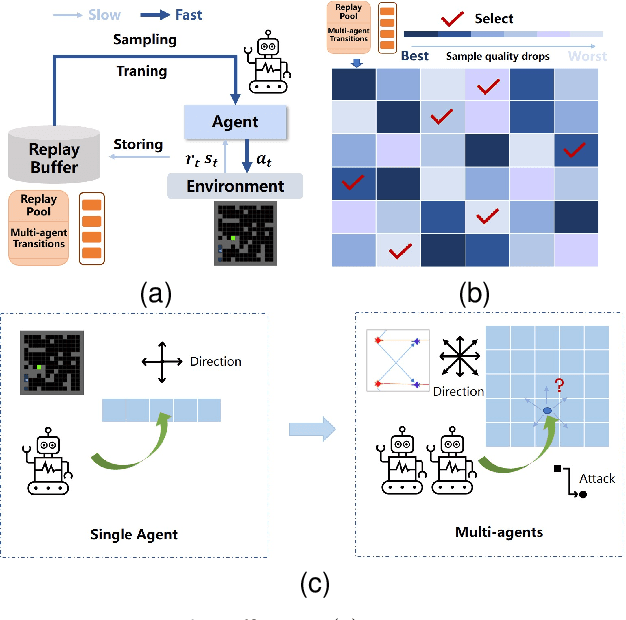
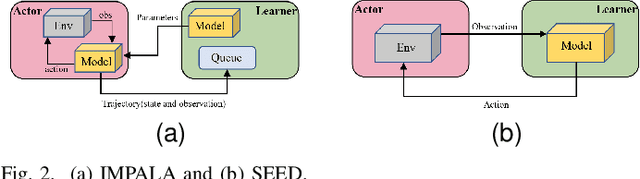
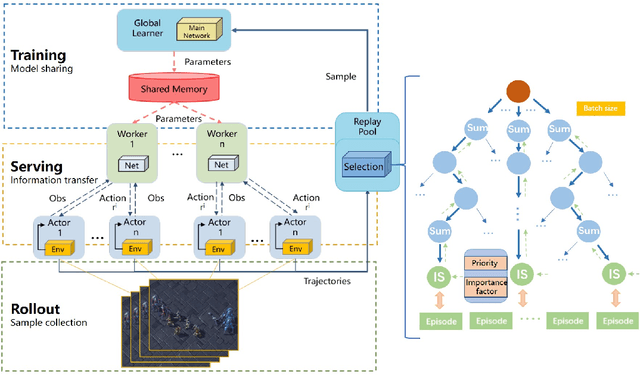
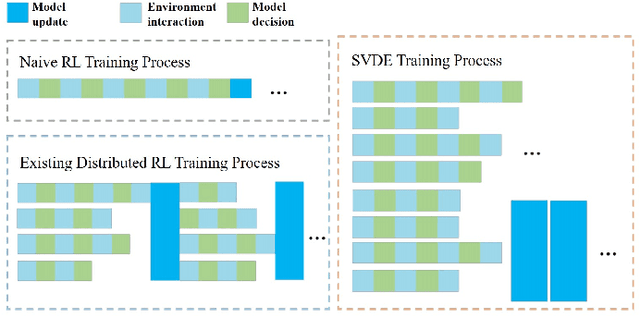
Value-decomposition methods, which reduce the difficulty of a multi-agent system by decomposing the joint state-action space into local observation-action spaces, have become popular in cooperative multi-agent reinforcement learning (MARL). However, value-decomposition methods still have the problems of tremendous sample consumption for training and lack of active exploration. In this paper, we propose a scalable value-decomposition exploration (SVDE) method, which includes a scalable training mechanism, intrinsic reward design, and explorative experience replay. The scalable training mechanism asynchronously decouples strategy learning with environmental interaction, so as to accelerate sample generation in a MapReduce manner. For the problem of lack of exploration, an intrinsic reward design and explorative experience replay are proposed, so as to enhance exploration to produce diverse samples and filter non-novel samples, respectively. Empirically, our method achieves the best performance on almost all maps compared to other popular algorithms in a set of StarCraft II micromanagement games. A data-efficiency experiment also shows the acceleration of SVDE for sample collection and policy convergence, and we demonstrate the effectiveness of factors in SVDE through a set of ablation experiments.